- Reference
Naver d2 이활석님의 '오토인코더의 모든것'
Kaist Edward Choi 교수님의 Programming for AI(AI 504, Fall2020)
Naver d2 이활석님의 '오토인코더의 모든것'과 Kaist Edward Choi 교수님의 AI 504 수업을 토대로 공부한 후 정리하였습니다.
0. 글 쓰기에 앞서
지난번 포스팅에서는 Neighborhood based training의 종류와 문제점에 대해 알아보았다. 또한 오토인코더의 등장 배경에 대해서 알아보았는데 이번 포스팅에서는 오토인코더의 구조와 학습 방법에 대해 조금 더 구체적으로 알아보자.
(지난번 포스팅 -> 오토인코더(Autoencoder)가 뭐에요? - 2.Why AutoEncoder?)
오토인코더(Autoencoder)가 뭐에요? - 2.Why AutoEncoder?
- Reference Naver d2 이활석님의 '오토인코더의 모든것' Kaist Edward Choi 교수님의 Programming for AI(AI 504, Fall2020) Naver d2 이활석님의 '오토인코더의 모든것'과 Kaist Edward Choi 교수님의 AI 504 수..
hyunsooworld.tistory.com
1. 오토인코더의 구조

오토인코더는 입력과 출력이 같은 구조다.
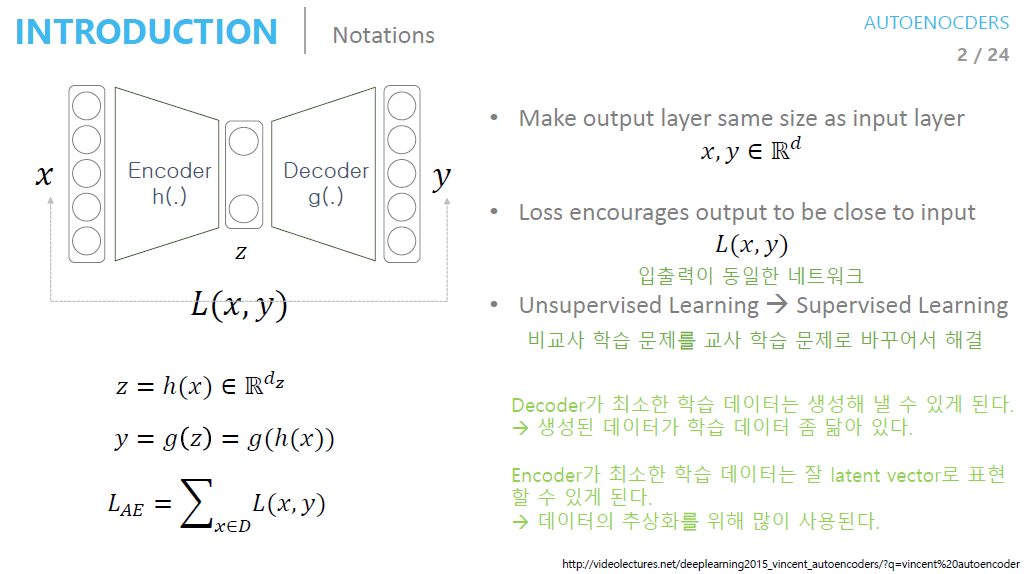
AutoEncoder가 초기에 각광받은 이유는 Unsupervised Learning 문제를 Supervised Learning 로 바꿔서 해결했기 때문이다. (ex: Dimensionality Reduction)
학습이 끝난 AutoEncoder는 보통 Encoder와 Decoder로 구분해서 해석한다.
Encoder 관점 : 최소한 학습 데이터는 latent vector로 표현을 잘 할 수 있다.(압축을 잘 한다)
=> 데이터의 추상화에 많이 사용
Decoder 관점 : 최소한 학습 데이터는 생성해 낼 수 있다.(Generator)
=> 생성된 데이터가 학습 데이터와 비슷함
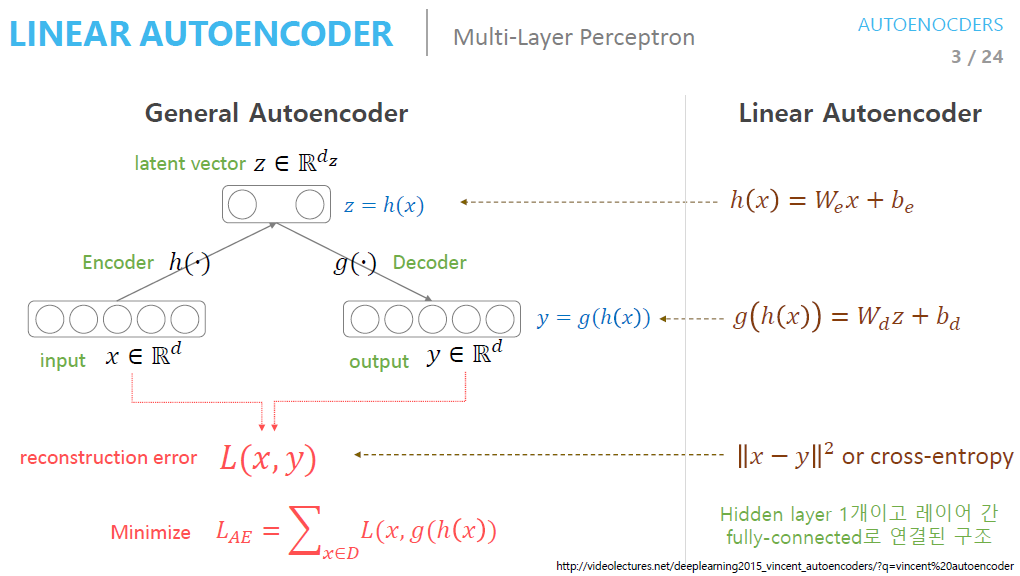
Linear Autoencoder는 activation function 없이 쓰는 것을 의미한다.
Linear Autoencoder는 PCA와 같은 매니폴드(subspace)를 학습한다.
2. Stacking AutoEncoder for pre-training
AutoEncoder가 처음 나왔을때는 dimension reduction method로도 쓰였지만 네트워크 파라미터 초기화(pre-training)에도 많이 쓰였다(pre-training).
그 당시에는 pre-traing방법들이(Xavier initializer 등) 존재하지 않았고, 오토인코더로 pre-training을 시킨 후 학습을 진행하였더니 높은 성능을 보여 많이 사용했다고 한다.
그렇다면 AutoEncoder에서는 어떤식으로 pre-training이 진행될까?
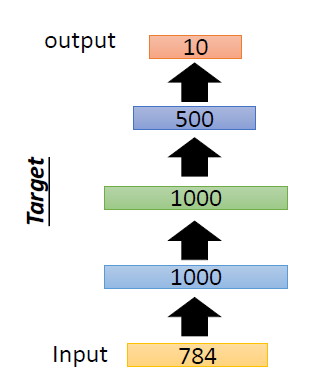
AutoEncoder의 특징 중 하나는 "적어도 입력값에 대해서는 복원을 잘한다"라는 것이다.
즉 AutoEncoder는 layer by layer로 하나씩 initialize를 진행한다.
이때, Input값과 동일한 Output을 출력하도록 Weight를 초기화해준다.
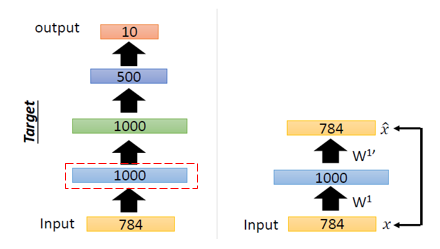
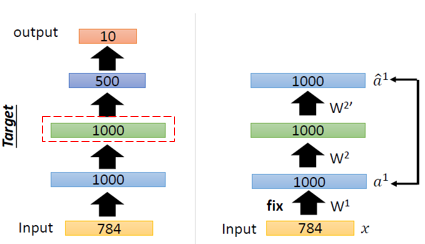
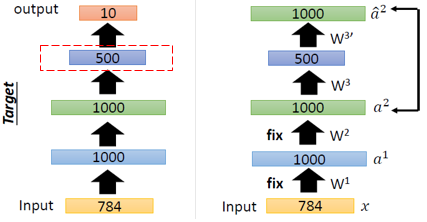
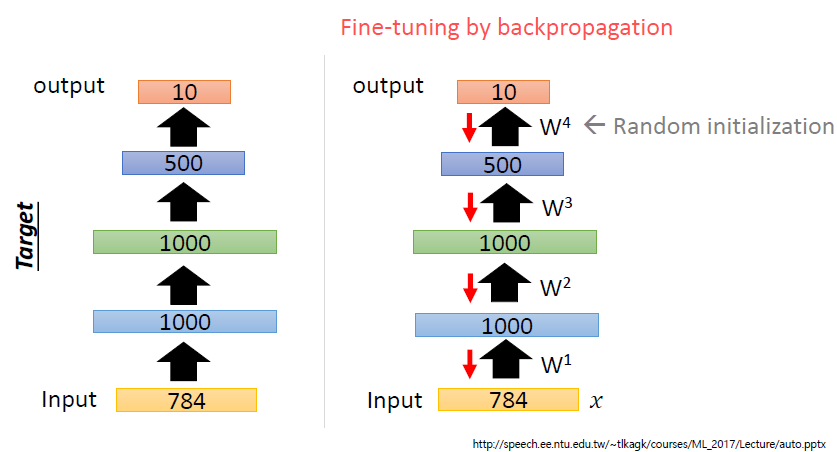
이러한 일련의 과정들을 AutoEncoder를 쌓아가면서 pre-training한다고해서 Stacking AutoEncoder라고 한다.
3. DAE (Denoising AutoEncoder)
DAE(Denoising AutoEncoder)란 기존의 AutoEnccoder에서 입력값에 noise를 추가해준 것을 의미한다.
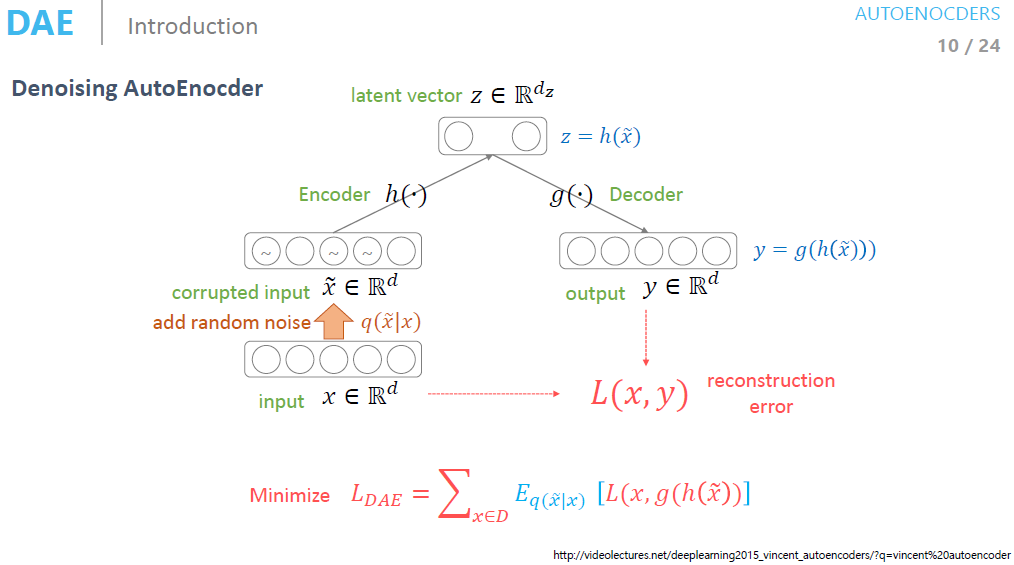
갑자기 noise는 왜 추가해 주는 것일까?
결론부터 말하자면 noise를 추가한 DAE(Denoising AutoEncoder)가 AE(AutoEncoder)보다 성능이 더 좋기 때문이다.
이때 AutoEncoder의 특징이였던 "입력값과 출력값이 동일해야 한다"에서 입력값은 noise를 추가하기 전의 값으로 생각해야된다.
즉, noise를 input에다가 추가해서 학습시켜도, output으로는 noise가 없는 원래 input값이 나와야 한다.
❗ 여기서 noise는 사람이 데이터에 대해 의미적으로 똑같다고 생각할 만큼의 noise를 추가해 주는 것이다.
(-> 손글씨의 경우 사람이 noise를 추가하기 전과 후가 같은 글씨라는 것을 인식 할 수 있어야함)
또한 의미적으로는 같기 때문에 noise를 추가하더라도 manifold 상에서는 똑같은 곳에 분포되어 있을 것이다.
DAE의 성능 (AE보다 좋은가)

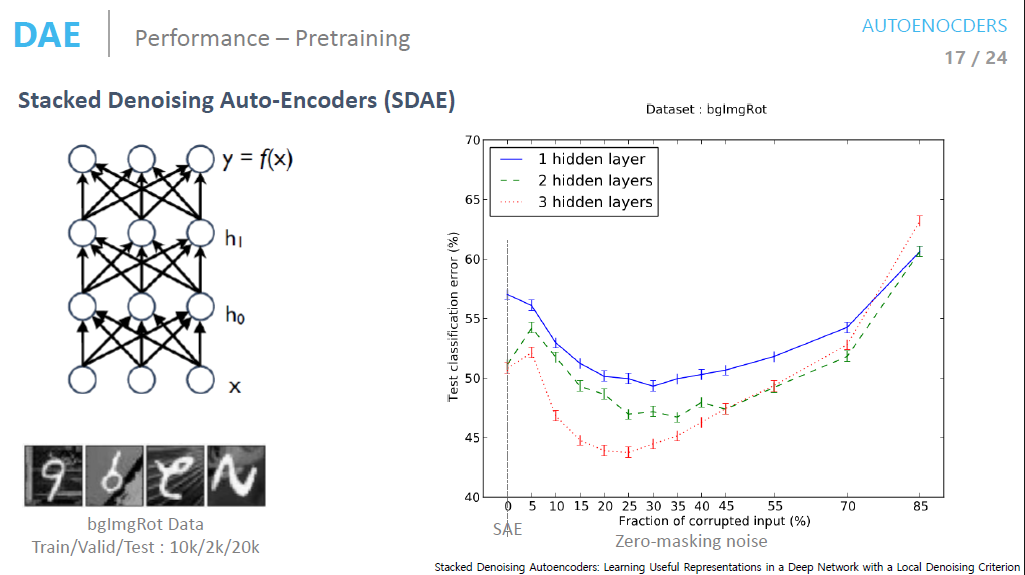
오른쪽 표를 보면 noise의 추가 레벨이 커질수록 분류 모델의 에러가 줄어드는 것을 볼 수 있다.
이때 noise가 0인 부분이 일반적인 AutoEncoder이다.
(너무 많은 noise를 넣으면 오히려 학습이 잘 이루어지지 않는다.)
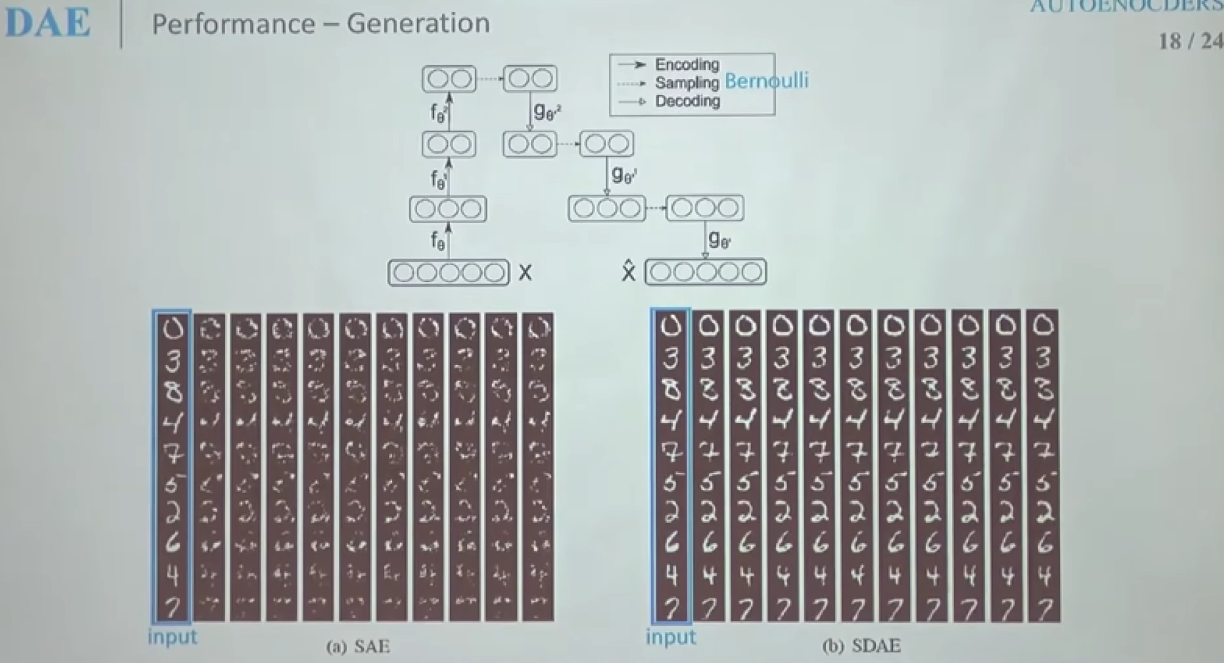
4. 정리
이번 포스팅에서는 오토인코더의 구조와 학습 방법 그리고 DAE에 대해 알아보았다.
다음 포스팅에서는 오토인코더 부분의 핵심이라 할 수 있는 VAE(Variational Autoencoders)에 대해 알아보자.
'AI Theory > Generative models' 카테고리의 다른 글
| 최대한 쉽게 설명한 GAN (1) | 2022.02.07 |
|---|---|
| 오토인코더(Autoencoder)가 뭐에요? - 5. Variational AutoEncoder(VAE) (0) | 2022.02.03 |
| 오토인코더(Autoencoder)가 뭐에요? - 4. Practice with PyTorch (AutoEncoder) (0) | 2022.01.31 |
| 오토인코더(Autoencoder)가 뭐에요? - 2.Why AutoEncoder? (0) | 2022.01.25 |
| 오토인코더(Autoencoder)가 뭐에요? - 1.Dimensionality reduction and Maninfold Learning (0) | 2022.01.24 |




댓글