- Reference
[DMQA Open Seminar] Transformer in Computer Vision
0. 글 쓰기에 앞서
Transformer는 자연어 처리에서는 굉장히 획기적인 아이디어였지만, 컴퓨터비전 분야에서는 잘 사용되지 않았다.
비전 분야에서는 주로 CNN구조를 사용하는 경우가 많았는데 이번 논문에서는 CNN을 아예 사용하지 않고 Vision task에 Transformer를 최대한 변형 없이 적용하였다.
이 논문은 Transformer 구조를 활용해 image classification을 수행한 최초의 논문이라는데서 의미가 있다.
(CNN 기반 모델들(SotA)과 비슷하거나 그 이상의 성능을 낸다)
1. Vision Transformer 개요
1-1. Vision Transformer의 구조
Vision Transformer 모델의 기본적인 구조는 다음과 같다.

Vit-Base/16에서 Base는 Vit의 가장 기본 모델이란 뜻이고(Vit-Large,Huge 모델도 있다), 16은 patch의 사이즈를 의미한다.
Transformer와 비교하면 input image가 전체 문장이고, patch가 문장을 구성하는 각각의 토큰이라고 생각하면 된다.
각 patch를 위와같이 하나의 문장처럼 sequence로 쭉 연결해준 후 1-dimension 벡터로 풀어준다.
이때, 각 patch size가 16x16이였는데 이미지이기 때문에 RGB 3채널을 곱해서 768차원(16x16x3)의 벡터가 될 것이다.
1차원으로 만들어진 patch를 Linear Projection을 통해 embedding vector로 표현해주는데, 간단하게 input이 768차원이고 output이 768차원인 fully connected layer을 통과한다라고 생각하면 된다.
이렇게 만들어진 patch의 embedding vector에 Classification token과 Position embedding이 추가된다.
(코드를 보면 알겠지만, 둘 다 사용자가 지정하는 것이 아닌 파라미터를 통해 학습된다.)
Position embedding은 기존의 transformer에서와 마찬가지로 patch(이미지)의 위치 정보를 제공하기 위한 것이고,
Classification token은 classification을 위해 사용되는 token이다.
(Classification token이 필요한 이유는 뒤에서 더 자세히 다룰 것이다.)
(BERT의 CLS token과 동일한 역할을 한다고 한다.)
💡 자연어처리에서의 transformer에서는 positional embedding으로 sin,cos함수를 이용하였는데, ViT에서는 이미지임에도 불구하고 2-D position embedding이 아닌 1-D position embedding을 사용하였다. (성능차이X)

embedding vector가 768차원이였으므로 당연히 Classification token과 Position embedding 또한 768차원 일 것이다.
위와 같이 각각의 값들을 서로 더해주면 최종적으로 transformer의 인코더로써 활용이 되게 된다.
Classification token과 Position embedding은 학습을 통해 결정되는 일종의 parameter라고 생각하면 된다.
1-2. "Vanilla" Transformer Encoder vs "ViT Transformer Encoder
2017년 transformer가 등장한 이후 후속 연구들에서 transformer가 layer를 깊게 쌓게되면 학습이 어렵다는 단점이 지적되고, 이를 극복하기 위해서는 layer normalization의 위치가 중요하다는 것이 밝혀졌다.
(Learning Deep Transformer Models for Machine Translation(Qiang Wang,...))
ViT Transformer 역시 기존의 transformer의 구조와 비교해보면 normalization의 위치가 다른 것을 알 수 있다.

기존의 Transformer는 Multi-Head Attention을 통과한 후에 normalization을 진행하였다면, ViT transformer는 normalization을 먼저 한 후 Multi-Head Attention을 진행한다.

기본적으로 normalization은 학습의 안정성을 위해 추가되는 layer이다.

일반적으로 Batch Normalization의 경우 feature단위로 Normalization을 진행하는데 layer Normalization은 instance 단위로 진행한다.
normalization이 끝난 후에는 다음과 같이 Wq,Wk,Wv의 Weight matrix와 곱해져 각각 query, key, value 값이 된다.

query, key, value 값은 각 W matrix와 인코더의 input z와 곱해서 나타나는 것이고, W matrix의 학습을 통해 attention 과정이 진행된다.
기본적인 과정은 기존 transformer와 동일한데 query와 key의 dot product를 통해 유사도를 계산하고, softmax함수를 취해 0과 1사이의 attention score(a)를 구하고 거기에 value를 곱해서 최종적인 attention의 output을 구한다.
위 과정은 입력 벡터 하나에 대한 attention score를 구하는 과정이고 입력 전체에 대해서 흐름을 살펴보면 다음과 같다.
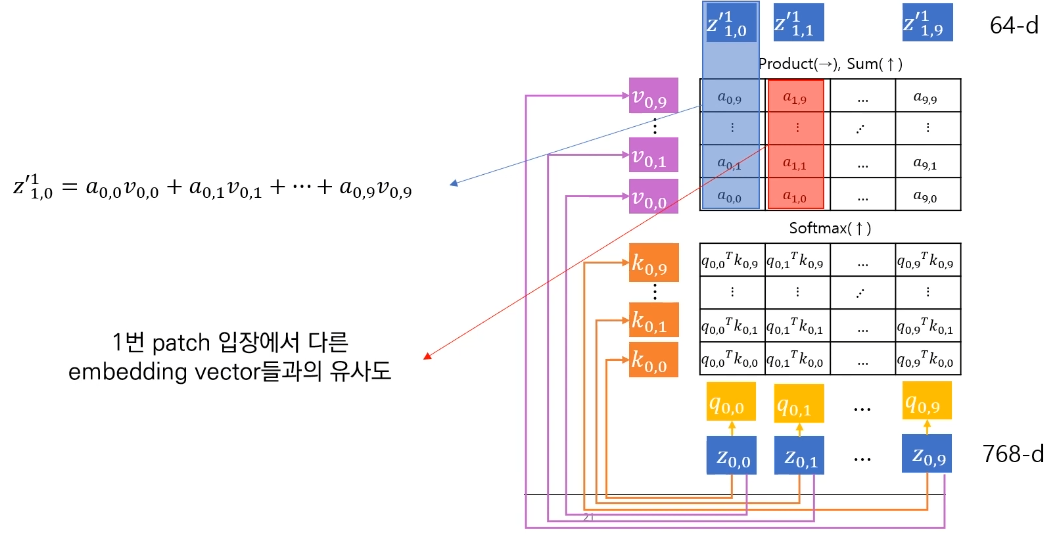
빨간색으로 표시된 attention score에 대해 살펴보면, 1번 patch 입장에서 다른 embedding vector와의 유사한 정도를 계산한 값이다. 이 값을 모두 곱해서 더해주면 최종적인 self attention의 output이 되는 것이다.
Transformer encoder는 기본적으로 self attention을 여러번 수행하는 Multi-Head Self Attention인데 ViT-Base/16 모델에서는 self attention을 12번 수행한다고 한다.
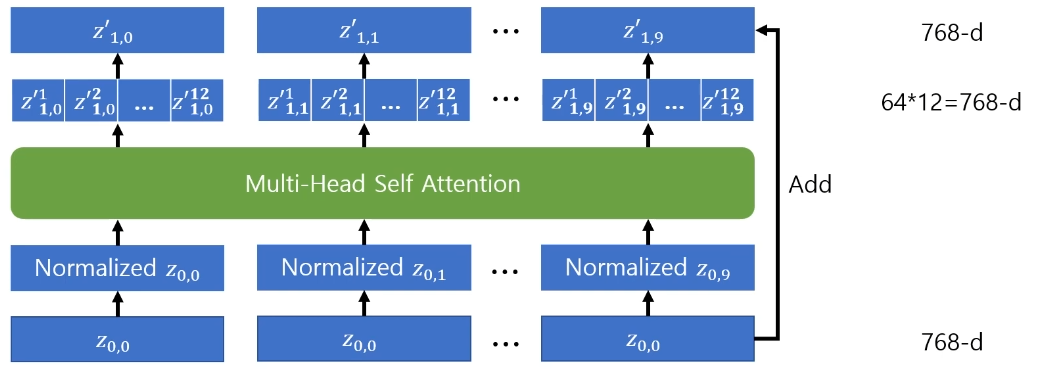
위에서 말했듯 self attention을 한번 수행했을때는 output dimension이 64-d가 되는데 12번 수행해주면서 다시 input dimension과 같은 크기인 768-d(64*12)가 된다.
Multi-Head Attention 과정이 끝났으면 다시 그 output에 대해 normalization을 진행해준다.
(앞에서 해준 normalization와 동일하게 layer normalization이다.)
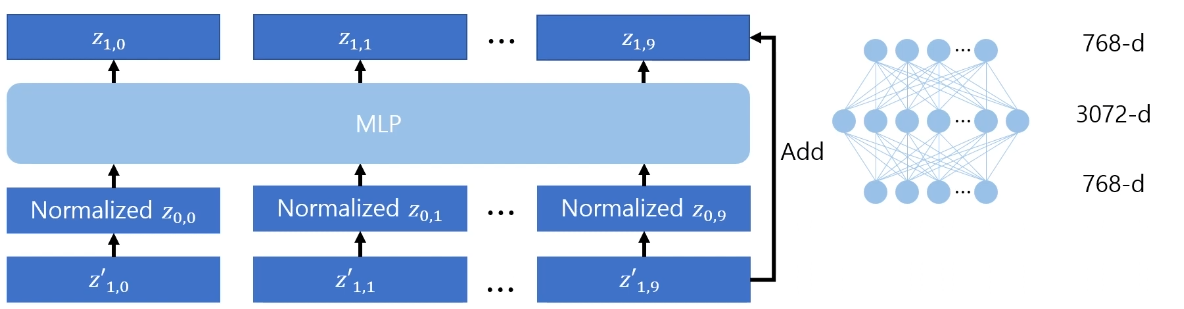
그 후 MLP를 통과하면서 최종적인 transformer encoder의 output이 된다.
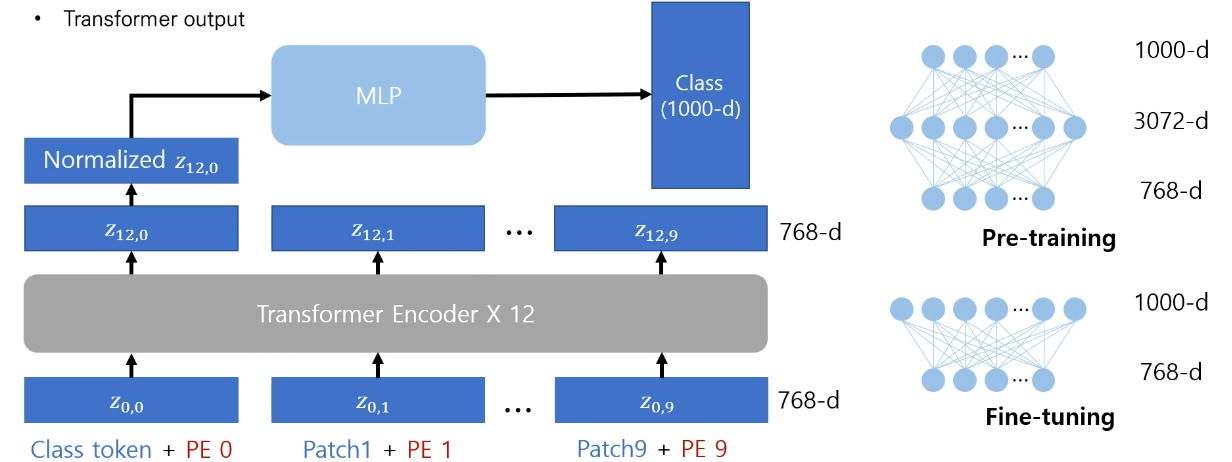
마지막으로 Vision Transformer의 output을 살펴보자.
Vision Transformer base model은 transformer encoder를 12층을 쌓아준다.
이때 각각의 patch에 대한 embedding이 계산 될 것인데, task를 수행할때는 patch에 대한 embedding이 아닌 이미지 전체(문장 전체)에 대한 embedding이 필요할 것이다.
이때 필요한 것이 바로 classification token이다.
classification token의 최종적인 embedding이 이미지 전체에 대한 embedding이다라는 가정을 하는데, 이러한 방식은 BERT에서 처음 제안되었다.
이러한 부분을 활용하여 ViT에서도 classification token을 도입해 최종적인 output이 이미지 전체의 embedding vector라고 가정하고 모델을 설계 할 수 있는 것이다.
2. Vision Transformer의 성능
기존의 연구에 따르면 pre-training 이미지의 resolution을 줄이고, fine-tuning을 할 때 resolution을 올려주면 모델의 성능이 올라간다고 한다.(해당논문)
ViT에서도 이러한 테크닉을 이용해 pre-training 이미지의 resolution은 224*224로, fine-tuning 할때는 384*384로 사용한다.
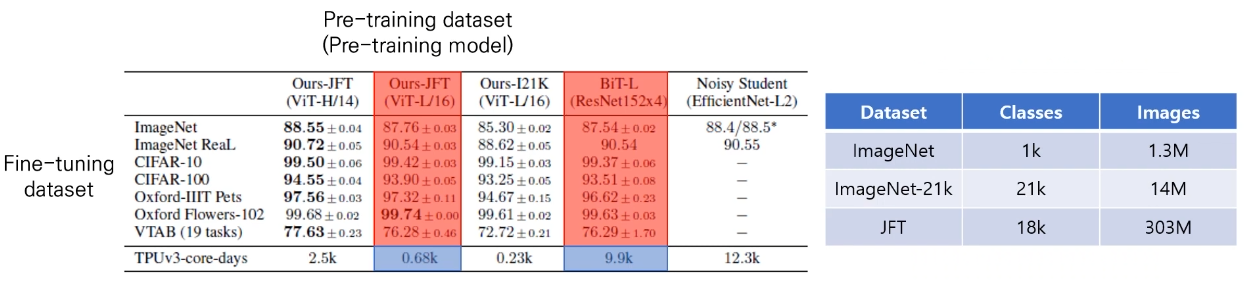
논문에서 ViT와 비교하는 것은 Big Transfer라는 방법론이고, 이는 CNN기반의 모델이고 성능이 가장 좋은 모델이라고 알려져있다.
위 표를 보면 Big Transfer보다 사용하는 자원은 적고, 성능은 올라갔다는 것을 볼 수 있다.
-> 훨씬 더 효율적인 학습
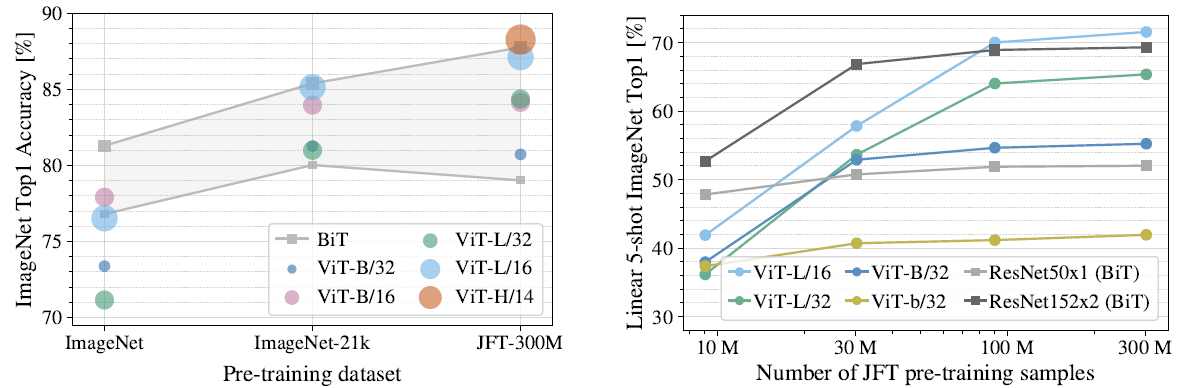
또한 사전학습시 데이터셋이 클수록 성능이 좋다는 것을 볼 수 있다.
-> ImageNet data를 사용하면 ResNet보다 정확도가 비슷하거나 조금 더 낮음
(데이터셋의 크기 : ImageNet-1k(1.3M) / ImageNet-21k(14M) / JFT-18k(303M))
-> JFT데이터는 공개되어 있지 않고, 그 정도의 학습 자원을 찾아 개인이 직접 사전학습을 진행하기에는 어려움이 있다.
-> ViT의 단점 보완 -> DeIT
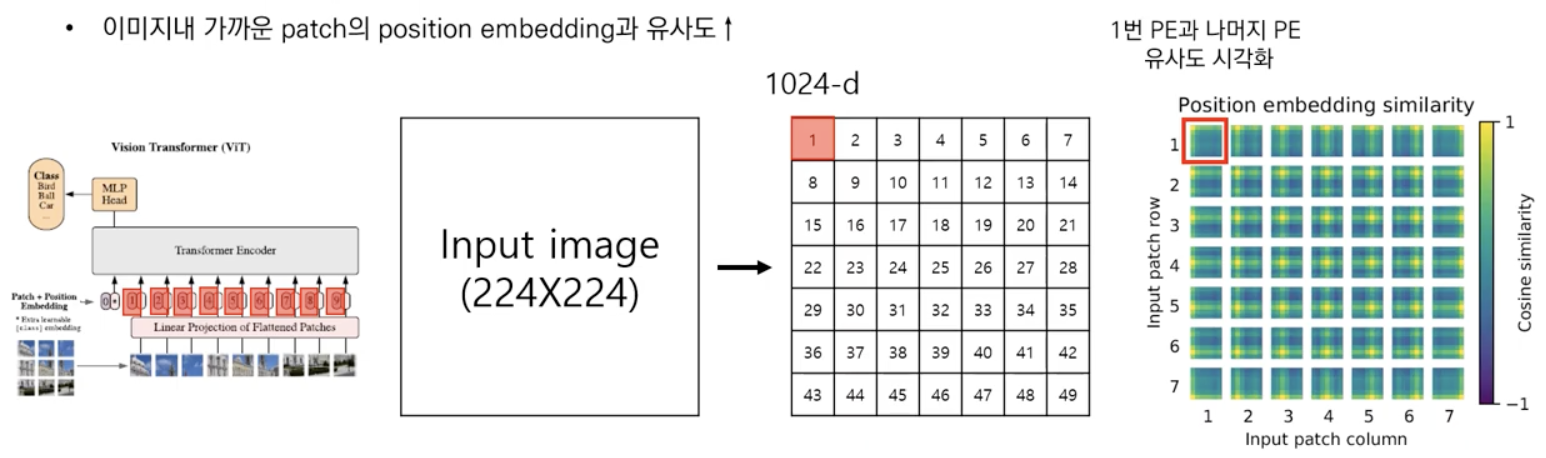
<position embedding의 시각화>
3. 코드실습
https://deep-learning-study.tistory.com/807
[논문 구현] ViT(2020) PyTorch 구현 및 학습
공부 목적으로 ViT를 구현하고 학습한 내용을 공유합니다 ㅎㅎ. 작업 환경은 Google Colab에서 진행했습니다. 필요한 라이브러리를 설치 및 임포트합니다. !pip install einops import torch import torch.nn..
deep-learning-study.tistory.com

댓글