목차
arxiv : https://arxiv.org/abs/2110.15943
code : https://github.com/facebookresearch/MetaICL
1. Introduction
- 논문이 다루는 task : in-context learning
- Input : x_1,y_1, ... ,x_k
- Output : y_k
- 해당 task에서 기존 연구 한계점
기존의 연구들에 따르면 LM의 모델 사이즈가 크거나(68B 이상), task reformatting 혹은 task-specific templates가 있어야만 in-context learning이 가능하다.
그러나 본 연구에서 제시하는 MetaICL은 훨씬 더 작은 언어 모델들로, specific한 formula없이 in-context learning을 가능하게 하고, 성능 역시 fine-tuning한 모델과 비슷하거나 일부 경우에는 더 좋다.
2. Related Work
In-context learning
기존의 연구들에서 언어모델의 in-context learning target task가 language modeling과 많이 다르거나, 모델의 크기가 충분히 크지 않으면 성능이 매우 좋지 않았다. 또한 variance도 크고, 최악의 경우 정확도도 떨어질 수 있다.
본 논문에서, in-context learning object로 explicit하게 학습시킨 LM은 그 크기가 작더라도 충분한 성능 향상을 보였다.
Language models are few-shot learners(GPT3), Neurips 2020
Calibrate before use: Improving few-shot performance of language models, ICML 2021
Surface form competition: Why the highest probability answer isn’t always right, EMNLP 2021
Noisy channel language model prompting for few-shot text classification, ACL 2022 -> 저자의 paper, 중요해보임 ..
Meta-training via multi task learning
Meta-training을 위한 기존의 연구들은 fine-tuning이 필요하거나, trainin task와 format이 비슷하거나, task specific templates에 심하게 의존해야했다. (혹은 모델의 크기가 매우 크거나)
본 논문에서는, 추가적인 노력 없이 새로운 task의 의미를 효과적으로 학습할 수 있게 하는 zero-shot transfer를 제안하였다.
Finetuned language models are zero-shot learners, ICLR 2021
Meta-learning via language model in-context tuning, ACL 2022
3. 제안 방법론
- Main Idea

MetaICL은 위 알고리즘이 전부이고,
Channel MetaICL에 대해서도 소개하는데 이건 저자의 이전 논문인 Noisy channel language model prompting for few-shot text classification, ACL 2022를 읽어봐야 한다. 이에 대한 설명은 생략하겠다.
- Contribution
- 기존에 In-context learning을 위해 꼭 필요했던 (human writen) template 제거
- downstream task로 다양한 task가 가능해졌고, 굉장히 많은 비교 실험을 진행
- 매우 강력한 baseline을 포함하여 모델의 크기 대비 성능이 많이 좋아짐
4. 실험 및 결과
- Dataset
CROSSFIT
UNI-FIED QA
- Baseline
GPT-2 Large
GPT-J
- Results
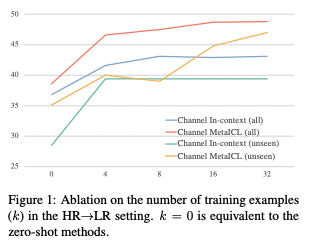
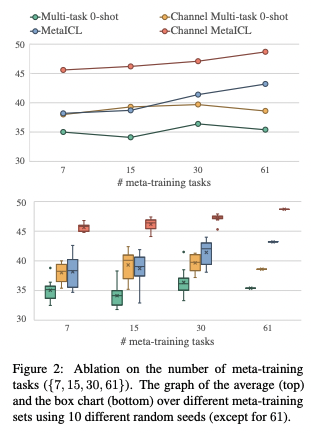
- Conclusion (What I learned)
사실 top-down으로 읽고 있기 때문에 논문 자체에서 엄청 배울만한 것이 많지는 않지만, 개인적으로 이 논문을 읽으며 괜찮은 아이디어가 떠올라서 굉장히 기분이 좋았다.



댓글