arxiv : https://arxiv.org/abs/2405.17430
code : https://github.com/mu-cai/matryoshka-mm
이용재 교수님 세미나를 들으며 직접 전해들었던 논문.
이 랩실의 연구들은 참 내 스타일인게 많은 것 같다.
근데 사실 논문 자체는 뭐가 1도 없다;;
Before reading
- 논문 제목을 보고 해당 모델이 어떤 방법론을 바탕으로 할지 가설을 세워봅시다.
- Matryoshka 인형 처럼(?) token 수를 정하면 그거에 맞는 output(coarse to fine)을 출력하는 LMM
- 논문의 main figure를 보고 전체 흐름을 유추해봅시다.

적절한 M을 어떻게 구해야하는지가 궁금하다. 특정 이미지가 얼마나 복잡한지 그 최적의 token 수를 사람이 눈으로 보고 결정할 수 있나..? 사람의 직관과 뉴럴넷의 직관이 다를 것 같은데, 그냥 이것 저것 다 해봐야하려나....
1. Introduction
- 논문이 다루는 task : image2text(LMM)
- Input : image
- Output : text
- 해당 task에서 기존 연구 한계점
- attention 연산의 복잡도 + token이 너무 많이 필요함(특히 video나 high resolution의 경우)
- -> Sparse Attention(Linformer / ReFormer)등으로 해결하거나 + Token Merging 등이 있지만
- single-length output만 가능하다는 단점이 있다.
2. Related Work
- LMM : LLAVA, MiniGPT-4 등
- very long visual sequence에서 large and fixed token 수 때문에 visual content를 표현하기 쉽지 않음
- Matryoshka Representation Learning
- Token Reduction : Linformer / ReFormer / Token Merging 등
- single-length output only
3. 제안 방법론

- Main Idea
CLIP-ViT-L-336을 visual encoder의 baseline으로 사용하였고, M sets을 {1, 9, 36, 144, 576}으로 설정하였다.
CLIP-ViT-L의 visual token이 24x24(57)개이므로 이로 부터 2x2 pooling(stride 2)을 적용하여 12x12 -> 6x6 -> 3x3 ->1x1(마지막에는 2x2pooling)을 통해 단일 토큰까지로 점점 coarse한 정보를 담을 수 있게 적용했다.

Train 과정은 기존의 LLM과 동일한 autoregressive next token prediction을 사용했고, 다만 각 scale S_i(M값)에 따라 이를 구한 뒤 평균을 내서 loss로 활용하였다.

- Contribution
- 효과적으로 visual contetnt representation 가능(어떤 granularity에서도)
- vision-language datasets/benchmarks(COCO 등)의 complexity 측정 가능
- provides a foundation to tackle a critical task in LMMs
- How to use the least amount of visual tokens while answering the visual questions correctly?
4. 실험 및 결과
- Dataset

- Baseline
LLaVA-1.5, LLaVA-NeXT : LMMs
Vicuna 7B : Language Model backbone
- Results

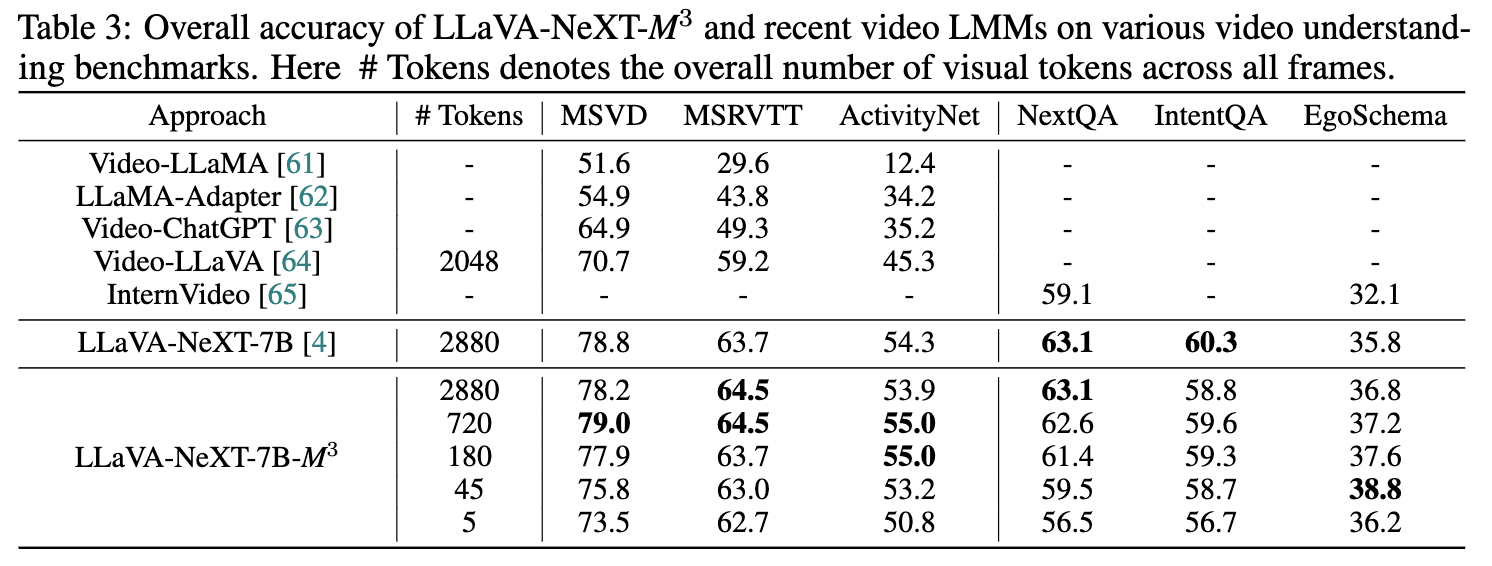
- Conclusion (What I learned)
활용할 수 있는 부분이 정말 많은 것 같은 연구였다. 그리고 이제는 논문을 읽을때 writing도 많이 보게 되는 것 같다.
'Paper Review > Large Multimodal Model' 카테고리의 다른 글
| [최대한 자세하게 설명한 논문리뷰] Flamingo: a Visual Language Model for Few-Shot Learning (1) (0) | 2022.08.26 |
|---|

댓글