- References
https://storage.googleapis.com/deepmind-media/DeepMind.com/Blog/tackling-multiple-tasks-with-a-single-visual-language-model/flamingo.pdf (논문 원본)
Multimodal VLM은 nlp뿐만 아니라 computer vision에서도 알아야 할 사전 지식이 많아 글 중간중간에 특정 설명을 논문 링크로 대체한 경우들이 있습니다. 해당 논문들에 대해서는 추후에 다시 읽고 정리해보겠습니다.
Flamingo 논문을 자세히 읽으며 공부한 내용들을 논문의 목차 순서대로 정리해보았다.
(연구 주제를 찾는 과정에서 논문들을 읽었기 때문에, 레퍼런스 논문을 최대한 많이 첨부하였고, 설명이 다소 빈약할 수 있습니다.)
+ 선행 연구들 중 모르는 내용이 많아 천천히 공부하며 정리 해 나가겠습니다 ..
0. Abstract
Flamingo model은 Deepmind에서 올해 4월에 발표한 Visual Language Models(VLM)이다.
Flamingo의 구조적 혁신 아키텍쳐는 다음과 같다.
- 강력한 pre-trained vision-only 그리고 language-only 모델들의 연결
- visual data와 textual data가 임의적으로 섞인 시퀀스 처리
- input으로서 이미지와 텍스트의 매끄러운(seamlessly) 입력
이러한 이미지-텍스트간의 유연성 덕분에, Flamingo는 이미지와 텍스트가 마구 섞여있는 대규모 multimodal wep corpora로부터 학습을 시킬 수 있었다. 이는 Flamingo가 few-shot learning에 있어서 탁월한 성능을 보이는 이유다.
💡 Few-shot learning이란?
소수의 데이터 셋(few-shot) 만으로도 downstream task에서 좋은 성능을 낼 수 있도록 학습하는 것이다.
이때, few-shot을 이용해서 사전학습(pre-training)을 시키는 것이 아니라 대규모 데이터 셋으로 사전학습된 모델을 가지고 특정 downstream taks에 fine-tuning 시킬때, few-shot을 이용하는 것이다.
Flamingo는 open-ended tasks와 close-ended tasks 모두에서 탁월한 성능을 보였다.
- open-ended tasks : visual qusetion answering
- close-ended tasks : multiple-choice visual question answering
Flaming는 다양한 image and video understanding tasks에서 좋은 성능을 보였는데, 수천 배 많은 데이터(task-specific data)로 fine-tuning 시킨 모델보다 few-shot만을 이용해 Flamingo로 학습시킨 것이 성능이 더 좋았다.
이에 대한 설명은 뒤의 4. Experiments 부분에서 더 자세하게 설명하겠다.
> Flamingo의 다양한 예시들












아래 그래프들은 Vision-Text 데이터 셋 별 Fine-tuning된 Flamingo model의 성능을 측정한 것이다.
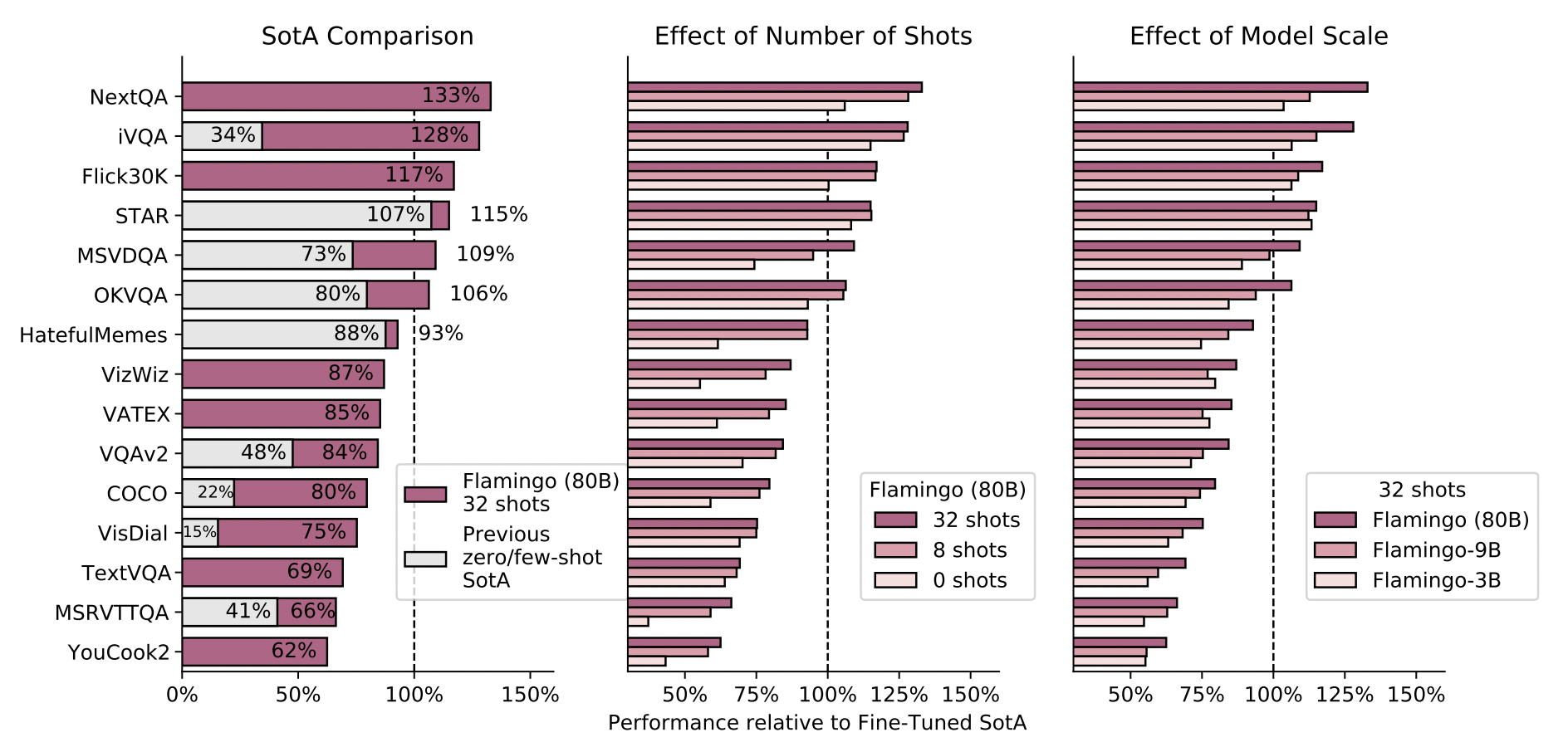
제일 왼쪽 SotA Comparision을 보면, 6개의 task에서 기존의 SOTA(100%)를 뛰어넘는 것을 확인 할 수 있다.
가운데 그래프를 보면, N-shots에서 N이 커질수록 즉 task-specific 데이터 쌍이 많아질수록 대부분의 task에서 좋은 성능을 내는 것을 확인 할 수 있다.
오른쪽 그래프에서는 모델의 크기에 따른 성능 비교를 나타낸 것인데, 대체적으로 크기가 커질 수록 모델의 성능이 좋아진다.
1. Introduction
인공지능에서 "지능"의 핵심 중 하나는 짧은 지시(예시)가 주어졌을때, 해당 문제를 해결을 얼마나 빠르게 학습하는지다.
오늘날 컴퓨터 비전 분야에서는 이러한 연구가 막 진행되고 있지만, 아직 대부분의 패러다임은 방대한 양의 데이터(multimodal web data)로 pre-training을 진행하고, 여전히 많은 양의 데이터(task-specific)로 fine-tuning을 진행한다.
이러한 방식의 문제점 중 하나는 해결하려는 task 별 하이퍼파라미터 조정이 매우 조심스러워야하고, 비용이 많이 든다는 것이다.
최근 연구들에서, contrastive objective를 통해 학습된 multimodal VLM의 zero-shot adaptation이 가능해졌다.
Contrastive objective papers
- Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
- Learning Transferable Visual Models From Natural Language Supervision
여기서 zero-shot adaptation이란 fine-tuning 없이 pre-trained 된 모델만으로 down-stream task에 적용하는 것을 말한다.
그러나 이러한 모델은 단순히 텍스트와 이미지 사이의 유사도 점수만을 제공하기 때문에 분류와 같은 제한된 사용 사례만 다룰 수 있다.
무엇보다도 언어를 생성해내는 능력이 많이 부족한데, 이러한 이유때문에 기존의 multimodal VLM은 VQA나 captioning같은 open-ended task에 적합하지 않았던 것이다.
또 다른 연구는 visually conditioned language generation에 대해 탐구했지만 low data 체제에서 아직 좋은 성능을 보여주지 못했다.
이러한 연구들에 대한 논문은 아래에 있으니와 관심있으면 읽어보면 좋을 것 같다.
Visually conditioned language generation papers
- Unifying Vision-and-Language Tasks via Text Generation- Multimodal few-shot learning with frozen language models
- SimVLM: Simple visual language model pretraining with weak supervision
- VLM: Task-agnostic video-language model pre-training for video understanding
이번 논문에서 소개할 Flamingo는 다양한 open-ended vision, language tasks의 few-shot learning에 대해 SOTA를 달성했다.
Flamingo는 대규모 언어 생성모델에 대한 최근 연구들에서 영감을 얻었는데, 이러한 생성모델들은 좋은 few-shot learners이다.
Large-scale generative language models papers
- Language Models are Few-Shot Learners
- PaLM: Scaling language modeling with pathways
- Training compute-optimal large language models
- Scaling language models: Methods, analysis & insights from training Gopher
이러한 대규모 언어 생성 모델 하나만으로 매우 강력한 성능 낼 수 있는데, 몇 개의 예시만 모델에게 입력값으로 줌으로써, 모델은 특정 태스크의 출력값을 예측할 수 있다.
그렇다면 대규모 언어 생성 모델과(위에 언급된 PaLM 등) Flamingo의 차이점은 무엇일까?
바로 Flamingo는 image와 text가 섞여있는 multimodal prompt를 입력값으로 줄 수 있다는 것이다.
이를 통해 Flamingo는 text들 중간에 image(or videos)가 끼워져있는(interleaved) 시퀀스를 입력으로 받을 수 있다.
(이러한 모델을 visually-conditioned autoregressive text generation model이라 한다.)
Flamingo는 새로운 아키텍쳐를 추가해 대규모 언어 모델에 강력한 visual embeddings를 접목시켰다.
이때, 대규모 언어모델과 visual embeddings 각각은 독립적으로 pre-train된 후 frozen된다.
(model frozen은 Flamingo에서 굉장히 중요한 컨셉인데, 이에 대해서는 뒤에서 자세히 설명하겠다.)
1-1. Challenges of multimodal generative
Multimodality model에 대한 연구들은 대규모 언어 모델(Large LM)에서 많은 영감을 얻었지만, language-only domain에서만 잘 작동하지 않게 다양한 도전을 하였다. 아래에서는 이러한 도전들의 한계를 간단히 소개하고 Flamingo에서 이러한 한계를 어떻게 극복하였는지 설명하겠다.
1-1-1. Unifying strong single-modal models
Pretrained LM을 기반으로 하는 multimodality model은 LM에서 pretraining한 엄청난 연산량을 절약할 수 있다.
그러나 LM(Language Model)은 "텍스트만으로" 학습되었고, multimodality model이 "잘 작동"하려면 다른 modality의 입력도 잘 처리해야한다.
따라서 이러한 inputs from other modalities을 pretrained LM에 적용하는 것은 해결해야할 큰 과제 중 하나이다.
Pretrained LM의 language understanding이나, generation 능력은 완전히 유지하면서, 다른 inputs의 개입으로 인한 불안정성은 최대한 피해야한다.
이러한 어려움을 해결하기 위해 우리는 cross-attention layers를 language-only self attention layers 사이에 끼워넣었다.
(cross-attention layers는 training 중에 frozen되어있다.)
또한 initialization 단계에서, 이 새로운 layers(cross-attention layers)의 영향력을 최소화하기 위해서, 논문에서는 특별한 gating mechanisms을 소개한다. (이 gating mechanisms으로 모델의 안정성과 최종 성능이 엄청 올라갔다고 한다.)
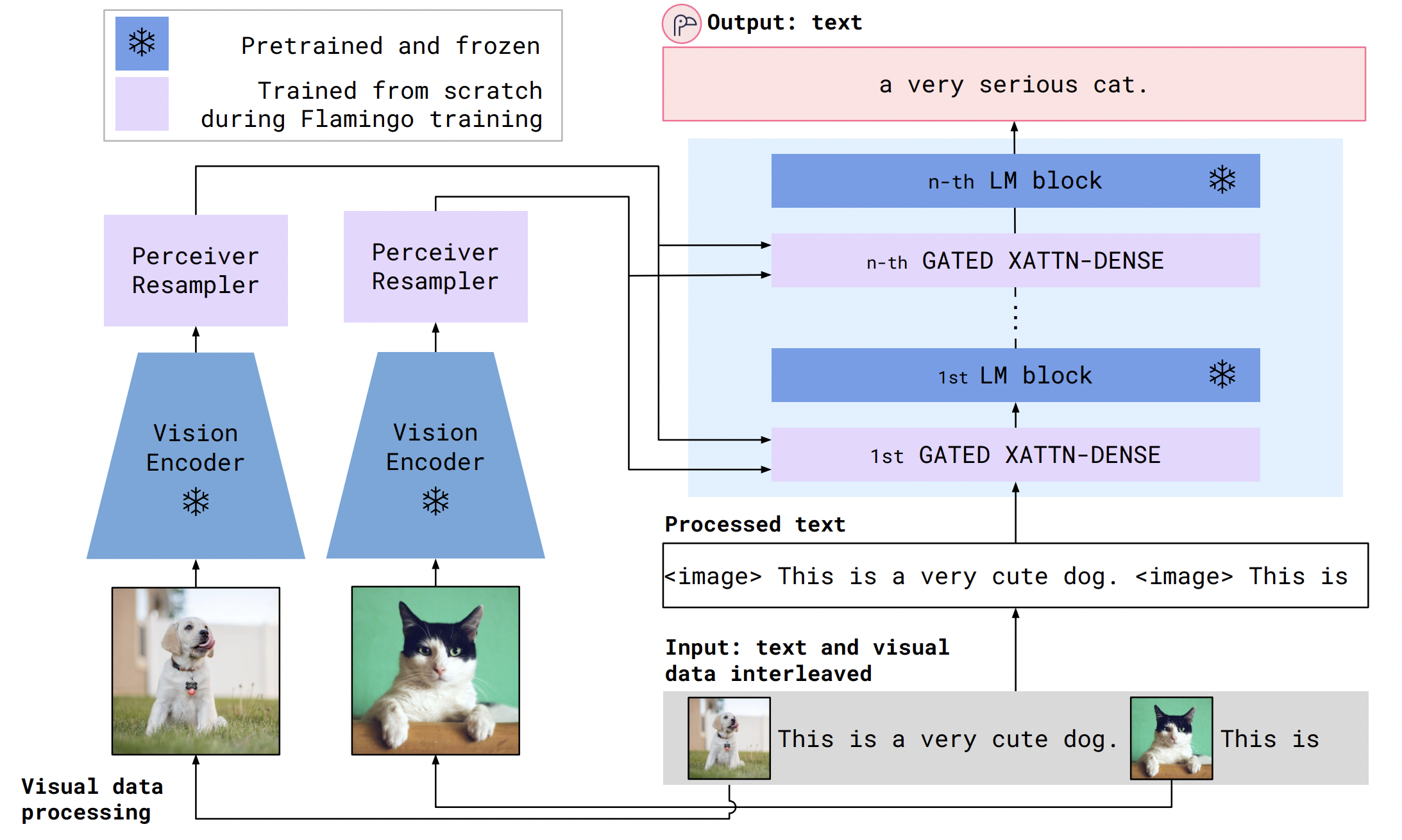
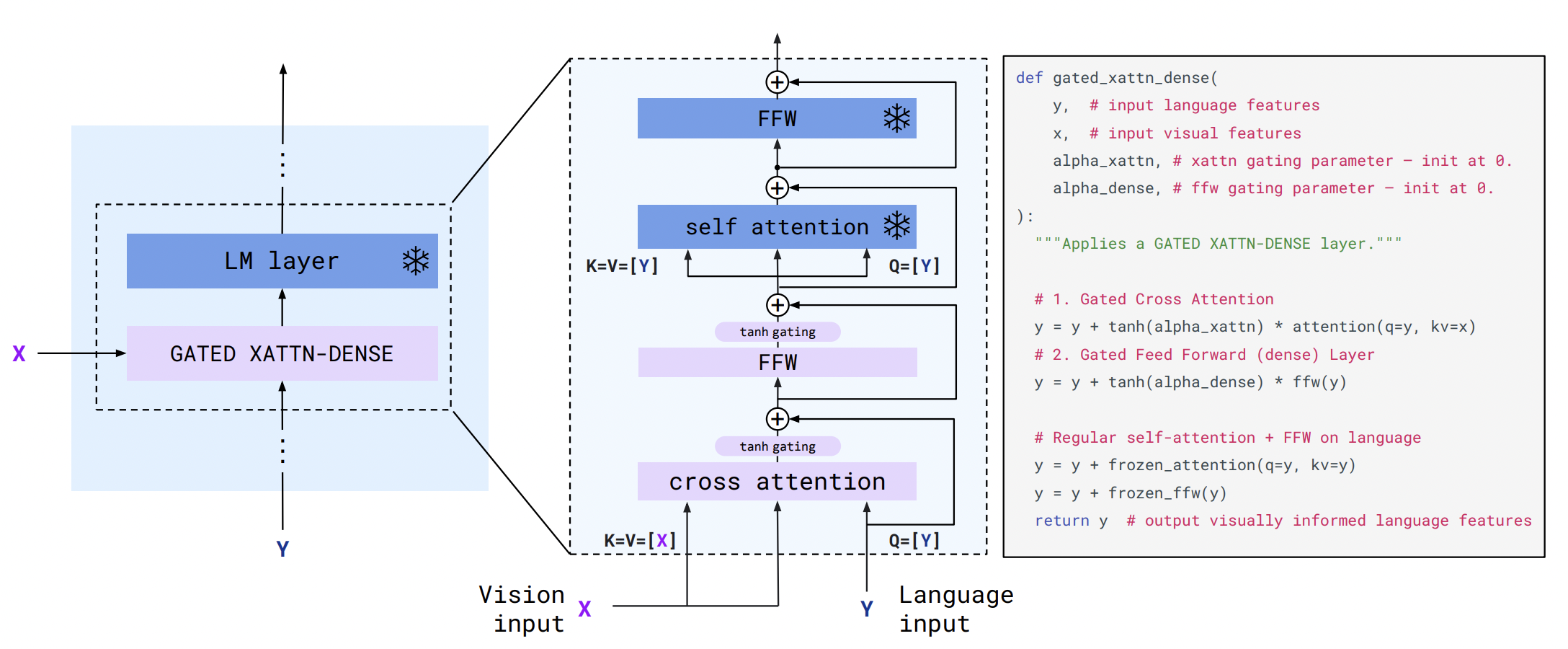
gating mechanisms은 위 그림에서 GATED XATTN-DENSE에 해당한다. 이는 뒤에 나오는 모델 아키텍쳐 부분에서 자세하게 설명하겠다.
1-1-2. Supporting both images and videos
2차원 혹은 그 이상의 고차원 이미지나 비디오는 unimodal text generation에서 처럼 1D seqeunce로는 즉각적으로 처리할 수 없다.
특히 transformer 계열의 모델은 단순히 고차원 visual data를 시퀀스로 펼쳐서 더하기 때문에 엄청난 메모리 부족 문제를 겪는다.
(계산량이 시퀀스 길이에 제곱하여 늘어난다.)
Computer vision 분야의 대표적인 SOTA 모델인 transformer도 Inductive Bias를 높이기 위해 local 2D priors에 의존하는데, 이는 텍스트 데이터에는 적합하지 않다.
💡Inductive Bias?
Inductive Bias를 높인다는 것은 보지 못한 새로운 데이터에 대해서도 귀납적 추론이 가능하게 한다는 것이다.
💡Local 2D priors?
Local 2D priors에서 priors는 사전지식을 의미한다. 즉 국소적인 2D 이미지 사전지식 정도로 생각하면 될 것이다.
정적인 이미지와 동적인 비디오를 하나의 통일된 아키텍쳐로 처리하는 것은 굉장히 어려운 일이다.
Flamingo에서는 Perceiver 기반의 아키텍쳐를 사용해 다양한 visual input features가 주어진 하나의 이미지 혹은 동영상을 일정 숫자(약 100개)의 visual tokens로 나눈다. 이를 통해 large inputs이 들어왔을때 모델의 expressivity(표현력)는 유지하면서 이를 잘 처리할 수 있었다.
(Perceiver 기반의 아키텍쳐에 대한 논문은 Perceiver: General Perception with Iterative Attention 에서 확인할 수 있다.)
1-1-3. Obtaining heterogeneous training data to induce good generalist capabilities
수 십억 개의 파라미터를 가진 large model을 학습시킬때는 방대한 데이터셋이 필요하다.
수 십억 개의 웹사이트를 스크래핑해서 반 자동적으로 수집한 일부 large-scale language datasets은 데이터의 양은 방대하지만, general하게 few-shot learning에서 좋은 성능을 기대하긴 어렵다.
이를 위해서는 large multimodal dataset이 필요한데, Flamingo에서는 웹 페이지들을 스크래핑해 이러한 데이터셋을 구축하였다.

위 그림과 같이 웹페이지에서 image-text가 섞여있는 데이터를 웹 브라우저에서 스크래핑하였다.
그럼에도 여전히 이미지와 텍스트의 연관성이 약했는데, 이를 해결하기 위해 이 데이터셋을 기존에 일반적으로 사용되던 image/text, video/text dataset과 합쳤다. (기존의 데이터들은 대체적으로 연관성은 매우 높았다.)
즉, 기존의 image/text, video/text 데이터셋은 연관성은 높았지만 데이터 크기가 너무 작았고, Flamingo에서 구축한 웹 스크래핑 기반 데이터셋은 연관성은 조금 낮지만 데이터의 양이 매우 커진것이다.
이러한 데이터셋의 혼합은
- Flamingo model의 few-shot task 귀납추론 능력을 general하게 하는데 필수적이다.
- 또한 visual inputs(images/videos)에 대해 생성된 output과의 연관성을 크게 보장한다.
1-2. Contributions
해당 논문의 contributions는 다음과 같다.
- Flamingo라는 visual language model을 소개함으로써 다양한 multimodal tasks를 적은 input/output 예시들로만 수행 할 수 있다.
- Flamingo는 임의적으로 image와 text data를 섞은 input을 받아들여서 open-ended 방식의 text output을 만들어내는 "새로운" 아키텍쳐다.
- Pre-trained된 large vision, language 모델을 효과적으로 활용하여, 각 초기 모델들의 장점은 유지하고 동시에 이를 효율적으로 융합하는 아키텍쳐 혁신 및 training 전략
- 이러한 모델의 시작은 80B 파라미터로 학습된 Flamingo 이전에는 Chinchila(Hoffmann et al., 2022)(70B)가 있었다. (Chinchila가 처음이다.)
- 다양한 크기의 visual inputs에 적응해 이미지와 비디오 모두 처리할 수 있는 Flamingo의 효율적인 방법
- Flamingo 모델이 few-shot learning을 통해 다양한 tasks에 적용될 수 있는지 정량적으로 평가한다.
- Flamingo는 16개의 language and image/video understanding tasks에서 SOTA를 달성하였고, 심지어 그 중 6개는 32개의 task-specific 예시만을 이용해 fine-tuning시켰다.
- 이는 기존 SOTA 모델보다 1000배정도 적은 예시를 사용한 것이다.
2. Related work
이 파트에서는 Flamingo와 관련있는 크게 네가지 분야의 연구를 간략하게 소개한다.
우선 Flamingo의 접근에 많은 영향을 준 large-scale language modelling에 대한 연구를 소개한다. 그 후 vision과 language 각각을 결합한 모델, VLM을 소개하며 수많은 VLM과 Flamingo를 비교한다. 또한 적절한 데이터셋을 모으는 것 역시 굉장히 중요한 작업이므로, 웹에서 수집한 multimodal training data들을 소개하고 Flamingo의 데이터셋과는 어떻게 다른지 설명한다. 마지막으로 few-shot learning에 대해 개략적으로 설명한다.
2-1. Language modelling
Language modelling은 최근 몇년 사이 엄청나게 발전해왔고, 특히 Transformer의 등장 이후 모델의 처리량이 늘어남에 따라 학습 가능한 데이터의 양이 증가하였다. Pretraining 역시 많이 연구되어 왔는데 masked language modelling loss(BERT or T5) 혹은 next-token prediction loss를 주로 사용해왔다.
지난 2년 동안은 GPT-3의 영향으로 언어 모델의 사이즈가 방대하게 커졌다. 또한 Language model의 성능이 model의 size와 매우 큰 관련이 있다는 연구 결과와 연산의 효율성을 극대화하기 위해서는 data token의 수를 model size와 동일한 비율로 설정해야한다는 연구 결과가 나왔다. 이러한 발견을 기반으로 Chinchilla라는 VLM 모델이 나왔고, 이는 70B개의 파라미터를 사용하였고 이는 Flamingo의 base model이다.
2-2. Joint vision and language modelling
Vision-Language modelling에서는 크게 세가지 접근 방식으로 나누어 설명한다.
2-2-1. Multimodal BERT-based approaches
[기존]
첫번째는 Multimodal BERT 기반 접근이다.
2018년에 나온 BERT는 많은 multimodal works에 영감을 주었다.
최근의 많은 연구들에서 visual region proposal를 위해 pretrained object dector를 image나 video에 적용시킨다.
이때 visual words를 활용하는데, visual words는 text tokens들과 합쳐져서 bi-directional transformer에 들어간다.
MLM loss뿐만 아니라 MRM loss(masked region modelling loss)는 masking visual tokens에 적용되곤 한다.
또한 cross-modal matching loss는 vision input과 text input이 매칭되는지 예측하는데 사용될 수 있다.
[Flamingo]
Flamingo는 위 나온 예시들과는 다르게 새로운 task에 대해서 fine-tuning을 필요로 하지 않는다.
게다가 Flamingo는 BERT-style models에는 native하게 생성 할 수 없는 텍스트를 생성 할 수 있다.
(아마 image interleaved text를 의미하는 것 같음, 확실하진 않음)
2-2-2. Contrastive daul encoder approaches
[기존]
더 최근에는 contrastive learning을 기반으로 한 vision-language model에 대한 연구도 활발히 진행되고 있다.
이러한 모델들은 vision, text inputs을 각각 다른 인코더에 넣고, 각각의 벡터를 만든 후에 contrastive loss를 활용해서 joint space에 embedding한다.
Contrastive approach는 highly generic visual representation을 학습한다는 장점이 있다.
크고 다양한 데이터셋을 학습할때는 강력한 zero shot vision-text retrieval과 classification이 포함되어야하는데,
불행하게도, 위의 연구들은 visual data를 text description에 매치시키는 것만 학습되었기 때문에, close-ended tasks에만 적용될 수 있다.
결과적으로, contrastive model을 다루기힘든(open-ended task) task에 적용시키는것은 굉장히 challenge하다.
사실 이 논문(CLIP)에서는 클래스당 2개의 training examples만을 활용하여 CLIP zero-shot performance를 감소시켰다.
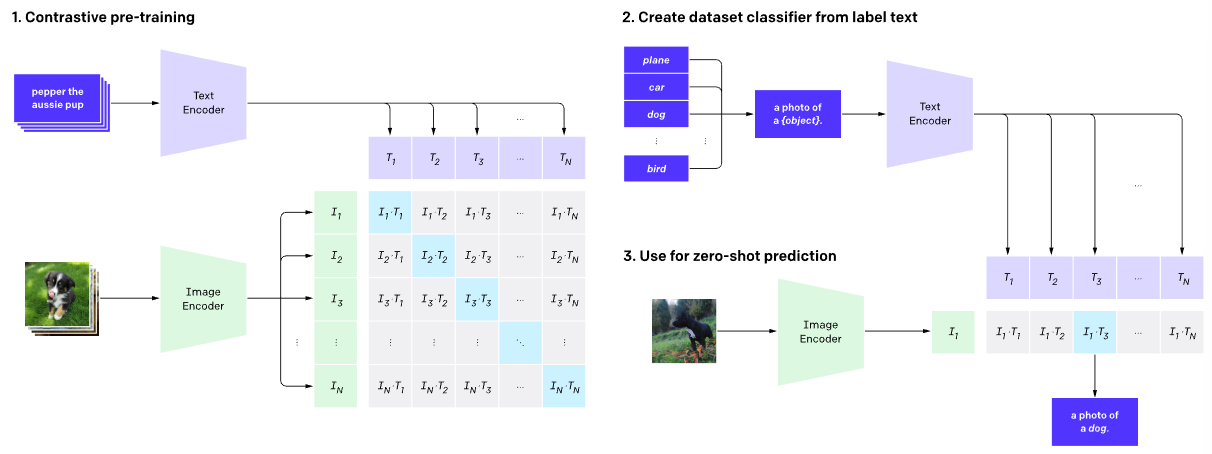
[Flamingo]
CLIP와 비교했을때 Flamingo는 4개의 training examples를 활용하여서 성능을 엄청나게 끌어올렸다.
정리하자면, Flamingo는 contrastive learning을 vision encoder가 수십억개의 웹 이미지를 텍스트와 함께 pretrain하도록 하는 기술로서 사용한 것이다.
2-2-3. Visual language models(VLM)
[기존]
Flamingo와 가장 유사한 VLM들은 autoregressive 방식으로 텍스트를 생성할 수 있는 VLM이다.
Autoregressive text generation(VLM) paper
Long-term Recurrent Convolutional Networks for Visual Recognition and Description - 2015
Show and Tell: A Neural Image Caption Generator - 2015
UniVL: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation - 2020
Scaling Up Vision-Language Pre-training for Image Captioning - 2021
첫 시도는(2015년) image를 설명하는 text를 추출하는 visual captioning 방식이였다.
VirText는 captioning을 text description을 통해 visual representation을 학습 할 수 있는 pretext task라고 본다.
💡Pretext task란 어떤 문제를 풀기 위해 pre-designed된 tasks를 의미한다.
CM3는 Flamingo와 비슷하게, 이미지에 대한 single caption 생성을 넘어, 이미지가 포함된 HTML 웹 페이지의 내용을 생성할 것을 제안한다.
여러 연구들은 수많은 vision task들을 text generation 문제로 formulate 할 것을 제안한다.
(classification, vqa, visual entailment, visual captioning, visual grounding, obeject detection .. )
Formulating numerous vision tasks as text generation problems papers
Unifying vision-and-language tasks via text generation - 2021
Uni-Perceiver: Pre-training unified architecture for generic perception for zero-shot and few-shot tasks - 2021
BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation - 2022
Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework - 2022
Large-scale LM을 학습시키는 것은 데이터가 많이 필요하고, 많은 컴퓨팅 자원을 필요로한다.
때문에, 이러한 모델들은 강력한 pretrained text-only LM 위에 구축하는 형식으로 연구된다.
VisualGPT는 pre-trained language-only model으로 VLM의 weights들을 initializing하는 것의 장점을 보여준다. (데이터가 충분할때)
Multimodal few-shot learning with frozen language models 논문에서는 이러한 아이디어를 pretrained LM weights를 freezing하는 것으로 확장시킨다.
Vision에서 모델의 weigt 조절은 prefix가 visual encoder에 의해 인코딩되는 prefix tuning(prompt tuning)의 개념과 유사하다. (Prefix-Tuning: Optimizing Continuous Prompts for Generation) (Prefix-tuning에 기반한 한국어 자연어 처리)
강력한 frozen LM 위에 구축하는 VLM의 장점은 비슷한 강력한 language-only model의 성능을 유지할 수 있게 한다는 것이다. (ex : few-shot language adaptation, external knowledge retrieval, dialogue capabilities)
Frozen language 모델의 conditioning의 구조적인 차이점은 조금 있지만, 많은 연구들이 이러한 아이디어를 따른다.
MAGMA : frozen language model에 bottleneck adapters 추가
ClipCap : vision features를 prefix에 mapping시킬때, simple linear layer 대신 vision-to-prefix transformer 사용
VC-GPT : visual prefix tuning 접근 대신, 새로운 learnt layer를 접목시켜서 frozen language model 연구
PICA and Socratic Models : 이미지의 내용을 GPT-3에 전달하기 위해 기성 vision-language 모델 사용 제안
[Flamingo]
- 기존 VLMs들의 아이디어 중 Flamingo에 적용된 것들
- Frozen pretrained language model에 의존
- Vision encoder와 frozen language model 사이의 transformer-based mapper 사용
- Frozen language model layers가 중간중간 껴있는 cross attention layers를 이용하여 학습
- 기존 VLM들과 Flamingo의 차이점
- Flamingo는 몇개의 few-shot examples만으로 새로운 tasks에 fine-tuning 없이 빠르게 적용될 수 있다.
- 성능 역시 SOTA 달성
- 시퀀스에 text, videos, images가 막 임의로 섞여있어도 전부 적용가능하다.
2-3. Web-scale vision and language training datasets
[기존]
일일이 직접(수작업으로) 주석을 단 vision-language dataset은 비용이 많이 들기 때문에 그 규모가 매우 작다. (10k-100k)
최근 연구들에서는 web scraping을 통해 자동적으로 visuals과 text 쌍을 만들어낸다.
그러나 이러한 데이터 쌍들은 단일 이미지(혹은 비디오)와 그에 대한 텍스트 묘사 밖에 고려하지 못한다.
또한 entire multimodal webpages에 있는 이미지, 텍스트가 섞여있는 시퀀스를 학습시키는 것은 굉장히 중요하다.
CM3에서는 이러한 접근을 시도하는데, 웹페이지의 전체 HTML markup을 만들고, 웹페이지의 title과 main body에서 자연어만을 추출하여 LM의 베이스로 사용하여 text prediction task를 단순화한다.
[Flamingo]
Flamingo는 VQAv2, COCO, ImageNet 등의 흔히 사용되고 엄선된 데이터셋이 아닌 오직 web scraped data만을 사용하여 많은 benchmarks에서 SOTA를 달성하였다.
논문에서는 web scraped data를 task-agnostic이라 표현하는데 이는 task에 구애받지 않는다 정도로 해석하면 된다.
2-4. Few-shot learning in vision
Few-shot learning은 computer vision분야에서 매우 빠르게 연구되고 있다.
Few-shot learning이란 매우 적은 예시 몇개로, 새로운 downstream task에 모델을 적용시키는 학습을 의미한다.
[기존]
기존의 few-shot learning에 대한 연구는 크게 세가지 종류가 있다.
- Query와 Support 간의 유사도 분석이 few-shot learning의 base라는 관점 (few-shot eaxmple이 실제 task와 얼마나 유사한가)
- Downstream에 잘 적용되기 위한 좋은 initialization을 찾기 위해 gradient updates를 사용하는 최적화에 초점을 둔 관점
- "in-context" few shot prompts에 초점을 둔 관점 → 최근 image-language task에 까지 확장됨 → Flamingo의 base idea
- "in-context learning"(문맥 내 학습)이란 예제들을 입력하면, 그 규칙을 파악하고 추론해서 문제를 예제처럼 푸는 것이다.
[Flamingo]
Flamingo는 "in-context learning pardigm"을 적용시키고 이를 video에 까지 확장시킨다.
3. Approach
이번 섹션에서는 Flamingo model이 어떻게 이미지와 텍스트가 섞인 input과 free-form 텍스트 output을 받아들이는지 설명한다.
겉으로 보기에는 단순해보이지만, 이 API(Flamingo)는 open-ended task와 close-ended task 등 다양한 작업을 처리하기에 충분한 표현력이있다.
open-ended task : visual question-answering, captioning → 텍스트 생성
close-ended task : classification → 카테고리나 정답 선택
Flamingo의 핵심은 few-shot in-context learning이 가능하단 것인데, 이는 interleaved prompts가 주어졌을 때 모델의 weight를 바꾸지 않고 원하는 task를 잘 수행하도록 학습하는 것이다.
Flamnigo의 아키텍쳐는 다음과 같다.
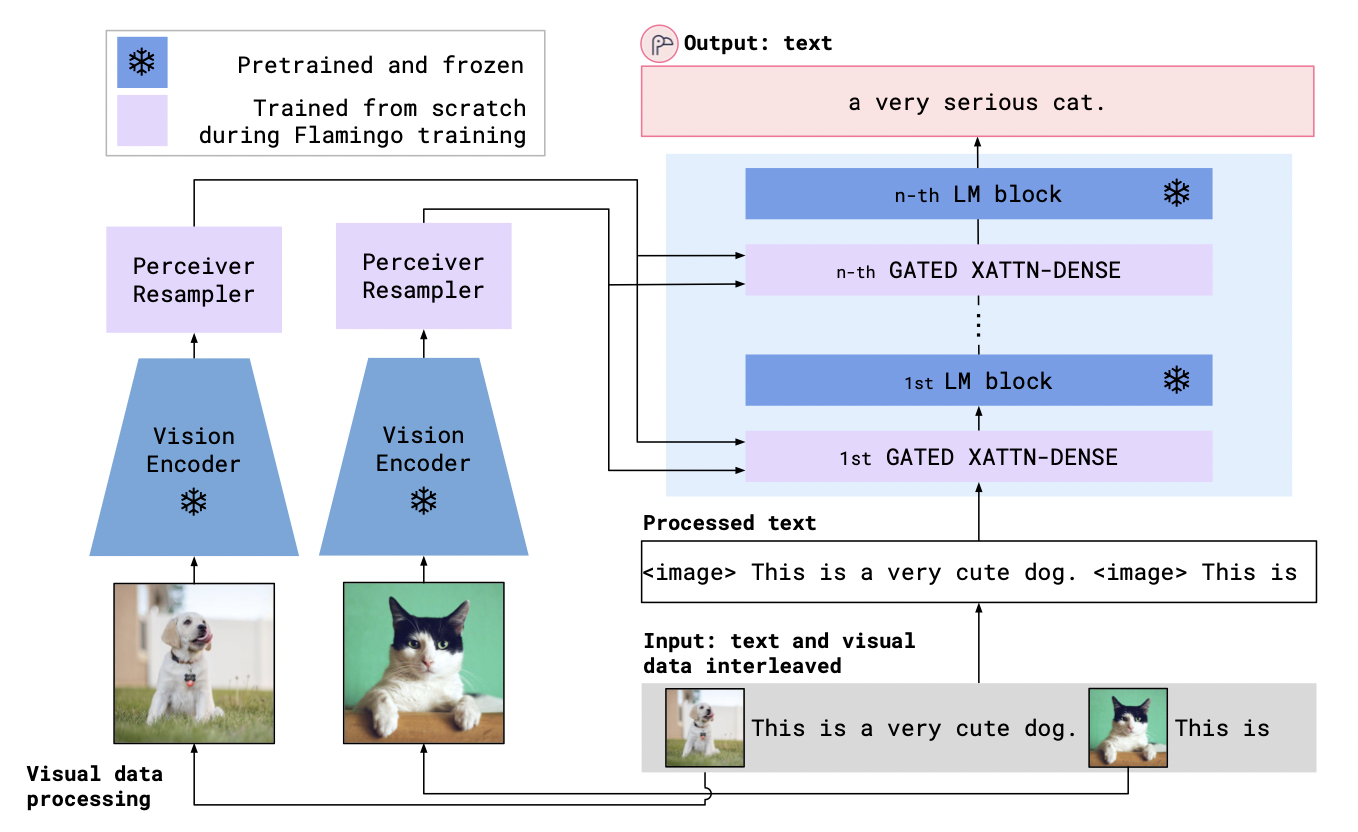
Flamingo가 objectives는 두가지다.
첫번째 목적은, 학습 시 scratch부터 훈련시키는 데 시간을 쓰지 않고 pre-trained model을 활용하는 것이다.
pre-trained model의 활용은 vision(image/video)쪽과 language(text)쪽으로 나눌 수 있다.
Vision에서는 CLIP라는 Vision Encoder를 contrastive text-image approach로 pretrain시킨다. (논문 참고)
여기서 CLIP의 역할은 색, 모양, 자연, 물체의 위치 등 시각적 기준에 대해 질문하고 싶은 속성을 설명하는 의미론적 공간 정보 features를 추출하는 것이다.
Language에서는 크고 다양한 text corpus로 pre-train된 autoregressive language model에서 출발한다.
이렇게 함으로써 Flamingo는 강력한 언어 생성 능력을 얻을 수 있고, LM weights에 저장되어 있는 방대한 양의 지식에 접근 할 수 있다.
두번째 목적은, 이러한 사전 훈련된 모델들을(vision과 language) 조화롭게 연결하는 것이다.
이렇게 하기 위해 Flamnigo는 이 모델들의 weights를 freeze시켜서 initial capability가 변하지 않도록 유지시킨다.
그리고 두개의 learnable architecture components를 활용하여 연결시킨다.
첫번째는 Perceiver Resampler라는 Vision Encoder로부터 시공간 features를 받고 outputs으로 고정된 크기의 visual tokens를 내보낸다.
두번째로, 이러한 Perceiver Resampler로 부터 나온 visual tokens은 새로 초기화 되는 cross attention layers(아래 그림 참고) 통해 frozen LM layer를 조정한다.
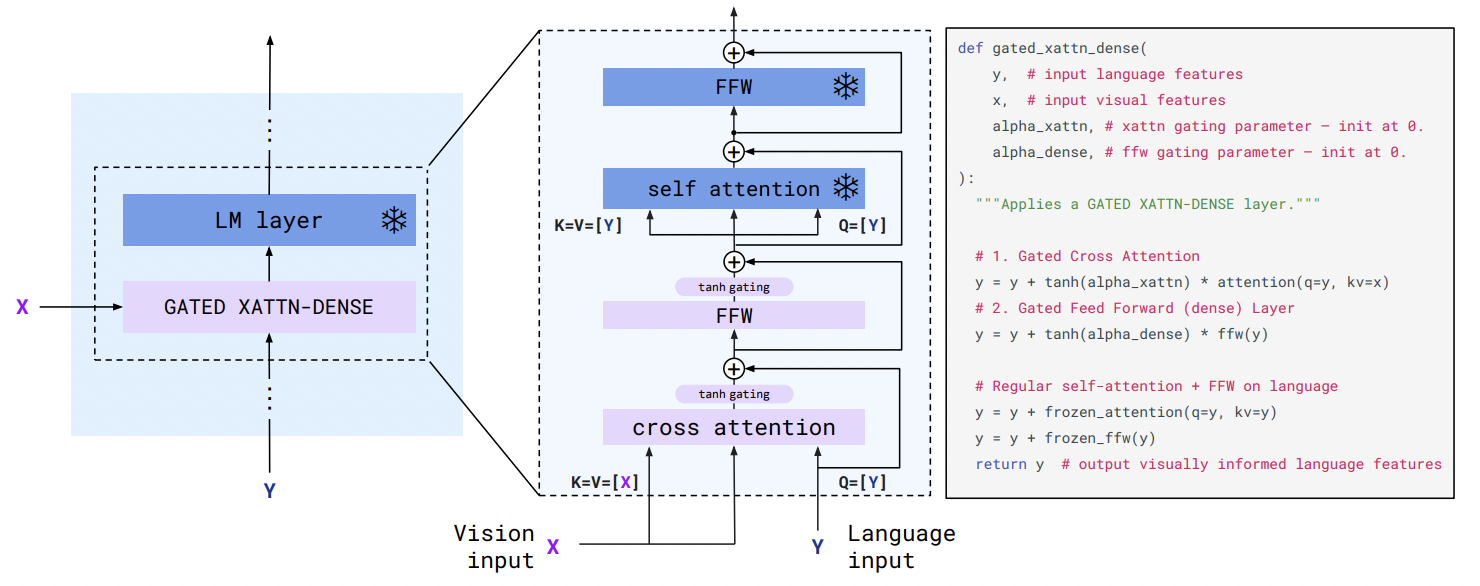
이러한 새로운 layer(cross attention layer)는 LM이 next-token prediction task를 위한 visual 정보를 통합하는 표현 방법을 제공한다.
중요한 점은 Flamingo 모델이 x(images/videos의 시퀀스)가 섞여있는 text y의 likelihood를 모델링 할 수 있다는 것이다.
x(images/videos의 시퀀스)가 섞여있는 text y의 예시는 아래와 같다.

좀 더 형식적으로, visually conditioned text likelihood(p(y|x))는 다음과 같이 나타낼 수 있다.

이때 yl은 input text를 구성하는 -번째 토큰이고, y<l은 앞에 있는 토큰들의 집합이며, x<=l은 시퀀스에서 yl토큰 앞에 있는 이미지/비디오 토큰들이다. 마지막으로 p는 Flamingo 모델에 의해 변하는 파라미터다. 이에 대한 자세한 내용은 3-1-3에서 자세하게 설명하겠다.
이러한 interleaved sequence에 대한 모델링은 Flamingo 구조가 causal masks를 통해 cross attention하는 것을 가능하게 한다.
Causal mask는 multimodal seqeunce내의 conditional dependencies을 지정한다. (잘 이해되지 않음)

text와 image가 섞인 시퀀스를 handling하는 능력(by likelihood)은 Flamingo model으로 in-context few-shot learning을 사용하는 것을 자연스럽게 한다.
이는 few-shot text prompting을 활용하는 GPT3와 유사하다.
Flamingo를 새로운 multimodal task에 학습시키기 위해서는, visual 입력과 예상 text 응답을 번갈아 가며 몇 개의 examples를 구성한 다음 최종 query로 이미지 또는 비디오를 제시하면 된다.

위 예시처럼 <image> [Output text], <image> [Output text] 를 제시한 후 최종 <image>와 "Output"을 입력하면 task에 맞춰 output을 출력 할 수 있다. 이러한 prompt를 모델에 제공함으로써 output text를 sampling하거나 fixed set of completions의 확률을 평가할 수 있다. fixed set of completions의 확률을 평가한다는 말은 아래 3-3에서 더 자세하게 설명하겠다.
3-1. Flamingo models architecture
이제 본격적으로 Flamingo의 아키텍쳐를 알아보자.
우선 input x(이미지)를 handling하는 visual stack에 대해 설명하고, 시퀀스 y(텍스트)를 생산해내는 text generative decoder에 대해 설명하겠다.
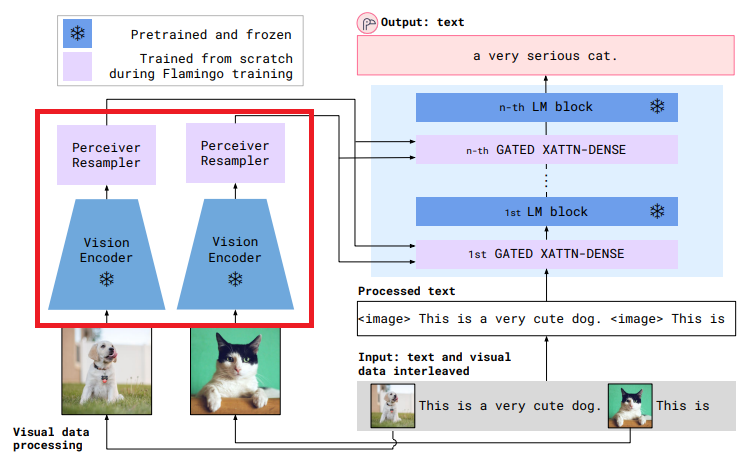
3-1-1. Visual processing and the Preceiver Resampler
Visual stack은 Vision Encoder과 Perciever Resampler로 구성되어있다.
Vision Encoder : "pixels을 features로"
Flamingo의 vision encoder는 Normalizer-Free ResNet (NFNet)을 사용하였다.
Vision encdoer는 contrastive objective를 사용하여 pretrain시켰는데, two-term contrastive loss(참고 논문)를 사용하였다.
Contrastive 유사도는 image encoder output의 mean pooling의 dot product(스칼라곱)와 BERT 모델의 평균 pooled output으로 계산된다.
Flamingo가 훈련되는 동안, vision encoder는 freeze되어있는데 vision encoder가 텍스트 생성을 할 때 직접 vision 모델을 학습시키는 것 보다 freeze시켜놓고 사용하는 것이 더 좋은 성능을 발휘하기 때문이다.
Vision Encoder의 최종 output은 2차원 공간의 features다.
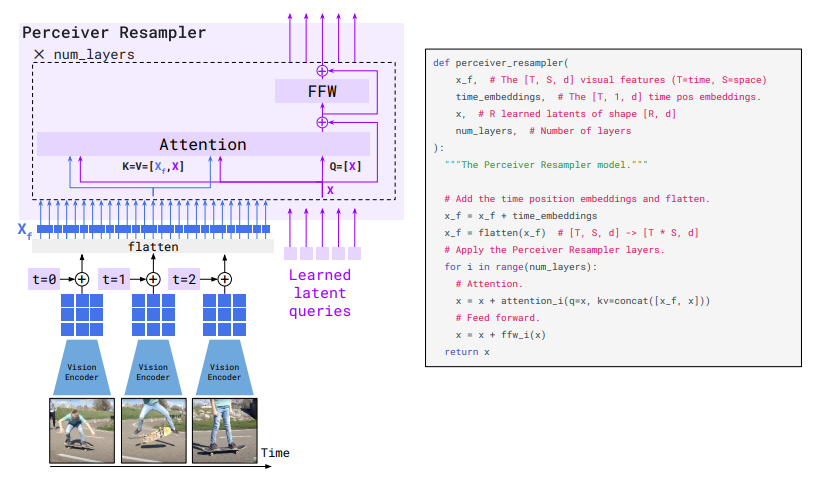
위 그림과 같이 각 그림마다 2차원의 features를 뽑아내고 이를 1차원으로 flatten시킨다.
Flamingo는 image뿐만 아니라 video input 역시 처리할 수 있는데, 논문에서는 frame을 1FPS로 설정하고, downstream components와 만나기 전에 독립적으로 인코딩시켜 T개의 feature maps를 얻고 이를 flatten 시켜 합친것이 Xf다.
(downstream components란 few-shot에 해당하는 downstream examples를 의미한다.)
Perceiver Resampler : "다양한 크기의 feature maps을 몇개의 visual tokens로"
Perceiver Resampler는 vision encoder과 frozen language model을 연결한다. (아래 빨간색 네모 참고)
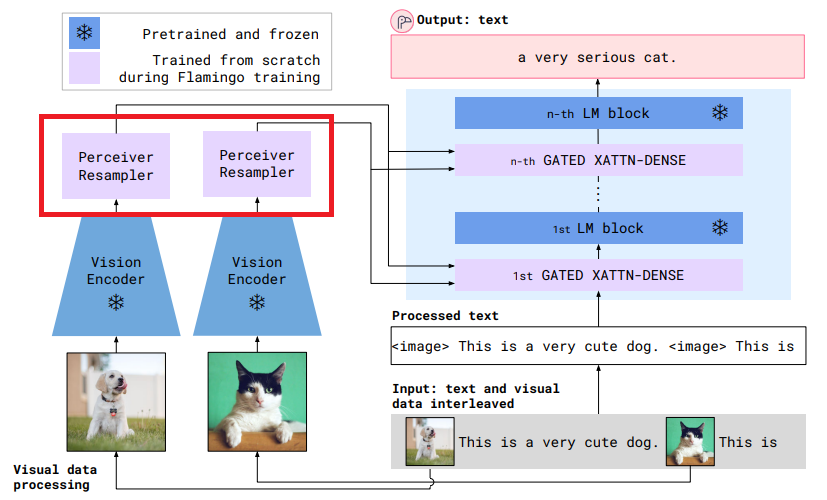
3-1-2. Conditioning a frozen language model on visual representations
3-1-3. Multi-visual input support : per-image/video attention masking
3-2. Training on a mixture of vision and language datasets
3-2-1. Interleaved image and text dataset
3-2-2. Visual data paired with text
3-2-3. Training objective and optimisation strategy
3-3. Task adaptation with few-shot in context learning
4. Experiments
4-1. Training and evalutation setting
4-2. Few-shot learning with Flamingo model
4-3. Fine-tuning Flamingo as a pretrained vision-language model
4-4. Ablation studies
5. Qualitative results
6. Discussion
6-1. Limitations, failure cases and opportunities
6-2. Benefits, risks and mitigation strategies
7. Conclusion
8. Appendix
'Paper Review > Large Multimodal Model' 카테고리의 다른 글
| [논문 리뷰] Matryoshka Multimodal Models (arxiv 240527) (1) | 2024.08.23 |
|---|

댓글