1. 머신러닝이란?
머신러닝은 컴퓨터(기계)가 데이터로부터 학습할 수 있도록 하는 인공지능(AI) 기술 중 하나다.
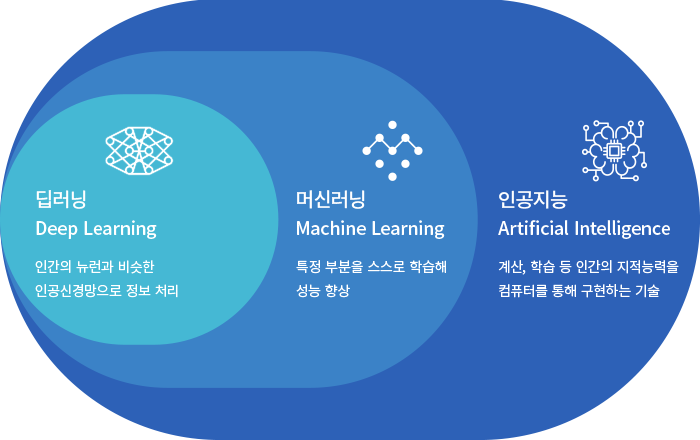
인공지능이 각광받으면서 인공지능/머신러닝/딥러닝 세가지 개념이 혼동되어 사용되고 있는데 정확히는 위와같은 포함관계에 있다.
또한 머신러닝은 주로 정형데이터(데이터베이스의 정해진 규칙에 맞춰 행과 열로 구성된 데이터)를, 딥러닝은 주로 비정형데이터(영상, 텍스트, 음성)를 활용한다. (반드시 그런것은 아니지만 통상적으로 성능이 더 좋다고 알려져있다.)
머신러닝이 잘 작동하려면 사람이 데이터의 특징(feature)을 잘 분류하고 분석해야한다.
이때 인간의 실수까지 기계가 그대로 학습한다는것이 머신러닝의 가장 큰 단점이다.
이러한 단점을 보완하는것이 바로 딥러닝이다. 딥러닝은 고도화된 머신러닝 방법으로 음성이나 사진 같은 고차원 데이터에서 기계 스스로 패턴을 알아낼 수 있다.
2. 머신러닝 구분
머신러닝의 학습 방법은 지도학습, 비지도학습, 강화학습 세 가지로 구분된다.

지도학습 : 정답 레이블이 주어진 데이터를 이용해 예측값과 실제 정답을 비교하며 학습하는 방법
비지도학습 : 정답 레이블이 주어지지 않은 데이터를 탐색해 패턴이나 구조를 파악하는 학습 방법
강화학습 : 자신이 한 행동에 대해 보상을 받으며, 그 보상을 최대화 할 수 있는 행동을 찾는 학습 방법
3. 지도학습(Supervised Learning)
지도학습은 정답 레이블이 있는 환경에서 입력 데이터(input)에 대한 출력 데이터(output)를 주어 입·출력 사이의 관계를 학습하는 것이다.
지도학습의 가장 큰 장점은 예측값을 정답과 비교해 틀린 정도를 확인하여, 알고리즘을 평가하고 업데이트 해 나갈 수 있다는 것이다.
지도학습 문제는 크게 회귀와 분류로 나눌 수 있다.
이때 둘은 손실함수를 서로 다른 것을 사용하는데 여기서 손실함수란 예측 결과와 실제 정답 사이의 차이를 의미한다.
회귀에서는 손실 함수로 평균 제곱 오차(Mean Squared Error, MSE)를 사용하고 분류에서는 교차 엔트로피 오차(Cross Entropy Error, CEE)를 사용한다.
3-1. 회귀(Regression)
회귀 문제는 출력변수가 주가, 속도, 키와 같은 연속형 변수를 예측해야 하는 문제이다.
회귀에서는 손실함수(loss function)로 평균 제곱 오차(Mean Squared Error, MSE)를 사용하는데 식은 다음과 같다.
MSE는 예측값과 실제값의 유클리디안 거리를 측정한다.

3-2. 분류(Classification)
분류 문제는 출력변수가 성별, 동물의 종류처럼 두 개 혹은 그 이상의 클래스(범주형 변수)일 때를 말한다.
분류에서는 손실함수(loss function)로 교차 엔트로피 오차(Cross Entropy Error, CEE)를 사용하는데 식은 다음과 같다.
CEE는 두 확률 분포의 차이를 측정하는 것이고 분류 문제는 이 차이값을 줄이는 방향으로 학습한다.

위 식에 대한 부연설명을 조금 하자면, 예를들어 어떤 이미지를 개, 고양이, 하마의 세 가지 클래스로 분류하는 문제가 있다고 하자.
이때 분포 q(y)는 실제 데이터의 확률 분포, p(y)는 모델이 예측한 확률 분포다.
만약 이미지가 하마 이미지라면 분포q(y)는 개와 고양이일 확률은 0, 하마일 확률은 1이다. 이때 분류모델이 각각[0.2,0.3,0.5]로 예측했다면, 손실함수는 -(0*log0.2 + 0*log0.3 + 1*log0.5) = 0.69로 계산 할 수 있다. 따라서 이 모델은 이 값을 줄이는 방향으로 학습해 나갈 것이다.
3-3. 지도학습의 방법론
3-3-0. 선형 회귀 모델 (Linear Regression Model)
선형 회귀 모델은 y=f(X)+ε 의 형태로 출력변수(Y)와 입력변수(X) 사이의 관계를 수학적으로 추정한다.
단순 선형 회귀 모형은 입력변수 X가 하나 인 것으로 y=b0+b1X+ε 형태로 일차함수와 그 모양이 비슷하다.

이때, b0는 y절편, b1은 기울기 역할을 하며 회귀 계수(regression coefficient)라고 부른다. ε(Epsilon)은 측정의 한계나 설명할 수 없는 외부요인에 의해 생긴 잡음(noise)을 의미한다.

다중 선형 회귀 모형은 입력변수 X가 여러개 인 것으로 수식은 다음과 같다.

다중 선형 회귀의 경우 입력변수가 많아지면서 설명하지 못하던 부분을 설명해 오차항의 값이 줄어들 수 있다.
그러나 변수가 많아지면 과적합(Overfitting)과 다중공선성(Multicollinearity)과 같은 문제가 발생할 수 있다.
과적합은 모델이 학습 데이터를 너무 집중적으로 추정해서 실제 맞춰야할 데이터에 대해서는 잘 맞지 않는 현상을 의미한다.
다중공선성은 입력변수 사이에 높은 상관관계를 갖는 것을 의미하는데 예를 들어, 광고 횟수와 광고 비를 입력변수로 매출을 추정하려 할때, 횟수와 비용은 높은 상관관계를 갖기때문에 설명하는 부분이 겹친다.
선형회귀모델의 가장 큰 장점은 "설명력"이다. 다른 지도학습 방법론들과 비교했을때 선형 회귀 모델의 "예측력"은 그렇게 뛰어나지 않다. 하지만 입력변수 X 와 출력변수 Y 사이의 관계를 쉽게 설명 가능한 선형 방정식으로 나타내기 때문에 X가 Y에 대해 어떻게 또 얼만큼 영향을 주는지 알 수 있다.
<Lasso와 Ridge>
입력 변수가 많으면 과적합과 다중공선성이 발생할 가능성이 커진다.
따라서 변수를 줄이거나 변수의 영향도에 대한 적절한 처리(Regularization, 정규화)를 해야한다.
그 방법으로는 크게 Lasso(Least Absolute Shrinkage and Selection Operator)와 Ridge라는 두 개의 모델이 있다.
두 방법론 모두 함수에 penalty를 추가해 회귀 계수가 과하게 추정되는 것을 막아준다.
Lasso는 전체 변수 중 일부 변수만을 선택하고, Ridge는 0에 가까운 회귀 계수로 감소시킨다.
선형회귀모델은 출력변수가 연속형인 경우에 주로 사용하는데 그렇다면 출력변수가 범주형일때 사용하는 모델은 어떤 것일까? 바로 로지스틱 회귀 모형이다.
3-3-1. 로지스틱 회귀 모델(Logistic Regression)
출력변수가 0 또는 1(성공/실패)로 범주가 2개인 경우라면 로지스틱 회귀모형을 사용하면 된다. (3개 이상도 가능)

선형회귀(좌)는 출력변수(Y)의 범위가 정해져있지 않기 때문에 가능한 Y값이 0 또는 1인경우에는 적합하지 않다. 로지스틱 회귀에서는 이러한 문제를 해결하기 위해 Odds라는 개념을 사용한다.
Odds란 실패에 비해 성공할 확률의 비율이다. 즉 성공할 확률 / 실패할 확률로 계산하고 이를 통해 그래프를 S자 형태로 만들어준다. 이때 odds는 그 범위가 0부터 무한대이므로 log 함수를 적용하여 -무한대 ~ 무한대로 범위를 바꿔준다.
3-3-2. 의사결정나무(Decision Tree)

의사결정나무는 마치 스무고개 처럼 "예" 혹은 "아니요"로만 대답하며, 정답의 후보를 찾아가는 것이다. 예측 성능은 비록 조금 낮지만 해석이 직관적이라는 장점이 있다. 따라서 주로 여러개의 단일 모델을 통합하여 결과를 도출하는 랜덤 포레스트(Random Forest)와 같은 앙상블(Ensemble) 모형에 자주 사용된다.
3-3-3. Support Vector Machine (SVM)
SVM은 2010년도 초반까지 다양한 분야에서 사용된 방법론으로 예측 성능이 높으며 과적합에 면역능력이 있는 모델이다.

SVM은 클래스를 가장 잘 나눌 수 있는 결정 경계를 정하는 모델이다.
이때, 각 클래스에서 결정 경계와 가장 가까운 데이터를 서포트 벡터(Support Vector)라고 하며, 두 클래스 사이의 거리를 마진이라고 한다. SVM의 목적은 마진을 최대로 하는 결정 경계(초평면)를 갖는 것이다.
만약 클래스가 완벽하게 구분되지 않는다면 일부 서포트 벡터를 허용해 초평면을 찾을 수 있고, 이는 과적합을 어느 정도 예방하는데 도움이 된다.
SVM은 예측 성능이 상위권에 있는 모델 중 하나이지만, 결정해야할 hyperparameter가 많고 학습 속도가 느리다는 단점이 있다. 또한 회귀모델과 의사결정 나무와는 다르게 해석이 힘들기 때문에 설명력 관점에서는 SVM을 사용하기 어렵다.
3-3-4. k-Nearest Neighbors (k-NN)
KNN은 가장 가까운 데이터 k개를 이용하여 해당 데이터를 유추하는 모델이다. 이는 매우 직관적이고 실제로 많은 연구에서 높은 예측력을 보이고 있으나 데이터의 양이 많으면 학습 속도가 급격하게 느려지는 단점이 있다.
이때 k는 사용자가 정하는 hyperparameter인데 k가 너무 작으면 시야가 좁아지면서 과적합의 가능성이 있으며, 반대로 너무 크면 주변 데이터를 고려하는 의미가 사라지게된다.

3-3-5. 앙상블 모형
앙상블 모형은 여러 모형의 결과를 종합하여 단일 모형보다 정확도를 높이는 방법이다.
앙상블 모형에서 사용되는 방법론에는 대표적으로 보팅(Voting), 배깅(Bagging), 부스팅(Boosting) 그리고 랜덤 포레스트(Random Forest)가 있다.
보팅(Voting) : 여러개의 분류기가 투표를 통해 최족 예측 결과를 결정하는 방식
배깅(Bagging) : Bootstrap Aggregating의 줄임말로 이미 존재하는 데이터로부터 같은 크기의 표본을 여러 번 복원추출한 부트스트랩 표본에 대해 예측 모델을 생성한 후 그 결과를 조합하는 방법론

보팅과 배깅은 둘 다 여러개의 분류기가 투표를 통해 최종 예측 결과를 정하는 방식이지만, 보팅은 서로 다른 알고리즘을 가진 분류기를 결합하고, 배깅은 모든 같은 유형의 알고리즘 기반이다.
부스팅(Boosting) : 부트스트랩 표본을 구성하는 과정에서 이전 모델에서 잘못 예측된 데이터의 비율을 높여 더욱 집중적으로 학습하는 방법론
랜덤 포레스트(Random Forest) : 배깅의 일종으로 의사결정 나무가 모여 숲을 이룬것 같은 형태를 말하며, 각 의사 결정 나무 모델링 단계에서 변수를 랜덤으로 선택하여 진행하는 방법론

4. 비지도학습(Unsupervised Learning)
비지도학습은 레이블이 주어지지 않은 상태에서의 학습 방법이다.
비슷한 데이터를 그룹화하거나 데이터의 숨겨진 특징을 추출하여 지도학습의 전처리 단계로 사용하기도 한다.
대표적으로는 군집화와 차원 축소가 있다.
4-1. 군집화(Clustering)
군집화는 특징이 유사한 데이터끼리 묶어 여러 개의 군집으로 나누는 방법이다.
군집화는 군집 내 응집도는 최대화, 군집 간 분리도는 최대화 이렇게 두가지 원리를 토대로 진행된다.
군집화의 대표적인 방법론에는 K-Means Clustering, Hierachical Clustering 등이 있다.

4-2. 차원 축소(Dimensionality Reduction)
차원 축소는 차원의 저주를 해결할 수 있는 방법 중 하나이며 고차원 데이터를 인간이 인지 할 수 있는 2, 3 차원 데이터로 축소하여 데이터를 시각화 할 수 있다는 장점이 있다. 차원 축소 방법론으로는 PCA, LLE, t-SNE 등이 있다.
차원의 저주가 무엇인지는 아래 링크에서 확인 할 수 있다.
오토인코더(Autoencoder)가 뭐에요? - 1.Dimensionality reduction and Maninfold Learning
- Reference Naver d2 이활석님의 '오토인코더의 모든것' Kaist Edward Choi 교수님의 Programming for AI(AI 504, Fall2020) Naver d2 이활석님의 '오토인코더의 모든것'과 Kaist Edward Choi 교수님의 AI 504 수..
hyunsooworld.tistory.com
5. 과적합과 모델 학습법
위 설명에서 '과적합'이라는 단어가 자주 등장했다.
과적합이 중요한 이유는 결국 우리가 예측하려는 것은 그동안 보지 못했던 새로운 데이터이기 때문이다.
과적합이 일어나는 경우는 주로 3가지 때문이고 각각의 문제는 다음과 같이 해결 할 수 있다.
1. 데이터 수가 적은 경우 -> 데이터 증강(data augmentation)
2. 입력 변수의 개수가 많은 경우 -> 차원 축소(PCA, t-SNE) 기법 활용
3. 복잡한 모델을 사용한 경우 -> regularization(Lasso, Ridge)
만든 모델이 과적합된 모델인지 판단하기 위해서 우리는 데이터를 train, validation, test 세 가지로 나누어서 학습을 진행한다. train data는 모델을 학습시킬때, validation data는 성능을 조정하기 위해(hyperparameter 선택), test data는 모델의 성능을 측정하기 위해 사용된다.

위 그래프에서 볼 수 있듯, test data(sample)의 오차가 증가하는 부분이 생길 수 있는데 그 부분부터 모델이 overfitting되고 있다고 생각하면 된다.
6. 성능 지표
6-1. 회귀에서의 성능 지표
회귀에서는 주로 MSE와 MAPE(Mean Absolute Percentage Error)가 사용된다. MAPE는 실제값 대비 오차의 정도를 퍼센트 값으로 나타내기 때문에 출력 변수의 단위에 영향을 받지 않는다.


6-2. 분류에서의 성능 지표


정확도(Accuracy) : 전체 데이터 중 모델이 올바르게 분류한 비율
정밀도(Precision) : 예측값이 Positive라 분류된 것 중에 실제값이 Positive인 비율 -> 모델의 입장
재현도(Recall) : 실제값이 Positive인 것 중 예측값이 Positive라 분류된 비율 -> 실제의 입장
F1 Score : 정밀도와 재현도의 조화평균
(조화평균을 사용하는 이유는 precision과 recall이 0에 가까워지면 f1 score에 낮은 값을 갖게(penalty) 하기 위함이다.)
분류문제에서는 각 클래스가 갖는 데이터량의 차이가 큰 경우 데이터 불균형 문제가 발생한다.
예를들어 보이스피싱에 대한 조사를 하기 위해 통화내역 100통을 조사한다고 가정해보자.
이때 실제 보이스피싱 사례가 단 한건이라면, 예측값 100통 모두를 "정상"으로 판정한다면 해당 모형은 99/100 = 99%의 정확도를 갖는다. 그러나 이 예시에서는 보이스피싱을 탐지하는 것이 목적이므로 정밀도 성능지표를 살펴보는것이 적절하다. 정밀도는 0/1 = 0%의 성능을 보여준다. 따라서 보이스피싱을 탐지하지 못하는 모형이라고 결론 지을 수 있다.
재현율이 중요지표인 경우 : 실제 positive 양성 데이터를 negative로 잘못판단하게 되면 업무상 큰 영향이 발생하는 경우 (ex, 암 판단모델)
정밀도가 중요지표인 경우 : 실제 negative 음성 데이터를 positive로 잘못판단하게 되면 업무상 큰 영향이 발생하는 경우
(이때, positive가 확률이 낮고, negative가 확률이 높다.)
'AI Theory > DL Basic' 카테고리의 다른 글
| [Pytorch] torch.nn.Module에는 어떤 method가 있을까? (0) | 2022.09.29 |
|---|---|
| [Pytorch] torch.gather vs torch.Tensor.scatter_ (pytorch 인덱싱 방법) (0) | 2022.09.29 |
| 딥러닝을 위한 경사하강법(Gradient Descent) (1) | 2022.09.23 |
| Inception v1,v2,v3,v4는 무엇이 다른가 (+ CNN의 역사) (1) | 2022.03.30 |
| 딥러닝을 위한 Window10 Docker 설치 방법 (윈도우 도커 설치 방법) (0) | 2022.03.11 |




댓글