- References
https://youngq.tistory.com/40
https://junklee.tistory.com/111
https://medium.com/@msmapark2/vgg16-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-very-deep-convolutional-networks-for-large-scale-image-recognition-6f748235242a
https://velog.io/@whgurwns2003/Network-In-NetworkNIN-%EC%A0%95%EB%A6%AC
Neural Networks - Networks in Networks and 1x1 Convolutions
https://deep-learning-study.tistory.com/525
0. 사전지식
0-1. CNN
CNN(Convolutional Neural Network)은 이름 그대로 Convolution 방법을 이용한 Neural Network model이다.
CNN은 기존의 Deep Neural Network에서 이미지나 영상 데이터를 처리하기 위해 발전한 방법이다.
기존의 DNN은 1차원 형태의 데이터를 주로 사용하는데, 이미지나 영상 데이터는 2차원 이상의 데이터인 경우가 대부분이다.
그렇다면 Convolution 방법은 어떤 원리로 이미지 데이터를 처리하는 것일까?
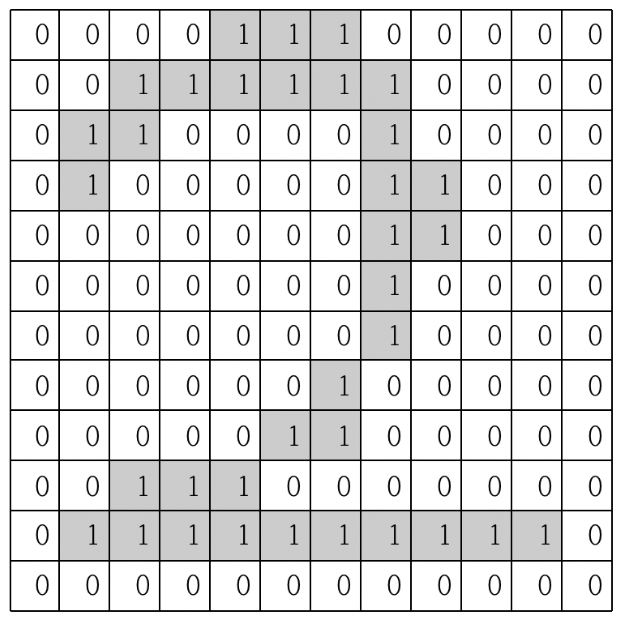
위 이미지와 같이 12x12 사이즈의 숫자 2에서 픽셀이 회색인 경우 1이, 흰색인 경우 0이 들어있다고 생각해보자.
CNN은 이 이미지의 픽셀들은 순차적으로 훑으면서 이미지의 특징을 추출해내는 것을 목적으로 한다.
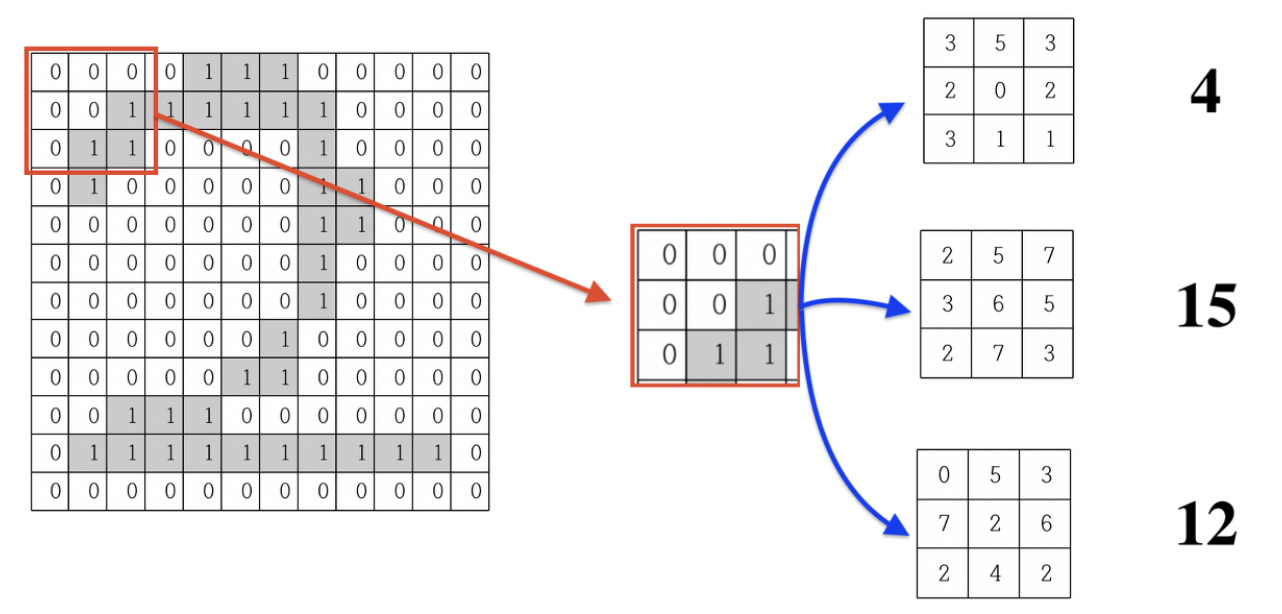
3x3 크기의 이미지 필터를 이용해 이미지의 좌측 상단에서부터 시작해 3x3 크기의 이미지를 뽑아내면서 각 데이터와 필터의 데이터 값을 곱해서 더해준다.
각 필터의 데이터들은 랜덤값을 갖고, 여러개의 필터를 이용해(위에서는 3개) 각각 계산을 해준다.
계산을 마치면 각 필터 값에 따라서 4, 15, 12와 같은 서로 다른 값이 나오는 것을 알 수 있다.
그 후 빨간색 칸을 한 칸씩 이동시키며 나머지 이미지 전체에 대해서 같은 과정을 반복해준다.
모든 과정을 마치면 위와 같은 12x12 이미지가 10x10 크기의 이미지 3개로 바뀔것이다. (필터가 3개이므로 3개의 이미지가 생긴다.)
이때 한 가지 의문점이 들 수도 있다.
입력 데이터의 크기는 12x12였는데 출력 데이터의 크기는 10x10이면, 정보의 손실이 발생한 것 아닌가?
이 문제(?)는 padding이라는 방법을 통해 해결 할 수 있다.
padding은 convolution을 수행하기 전, 입력 데이터 주변(padding)에 특정 값을 추가시켜 출력 데이터의 크기를 일정하게 만들어주는 방법을 말한다. 이때 주변 값으로 보통 0을 사용하는데 이를 zero-padding이라고 한다.
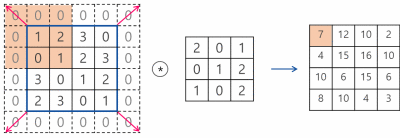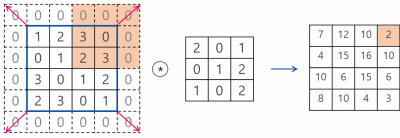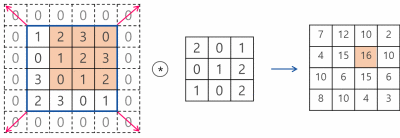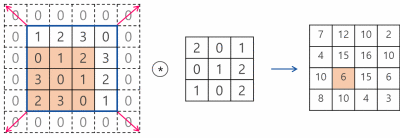
또한 빨간색 칸이 이동할 단위를 stride라고 하는데 정확하게는 필터가 이동할 간격을 의미한다.
위 이미지는 stride가 1일때 zero-padding을 사용한 convolution 연산 과정을 나타낸다.
convolution 연산 말고도 cnn에는 중요한 특징이 한가지 더 존재한다.
바로 Pooling이다.
Pooling을 해주는 목적은 다음과 같다.
- Input size(텐서의 크기)를 줄여줌 -> 데이터의 특징을 더 잘 추출할 수 있다.
- Overfitting을 어느정도 예방한다 -> input size가 줄어든다는 것은 쓸모없는 파라미터 수를 줄여주는 것
Pooling은 크게 Max Pooling, Average Pooling, Min Pooling이 있는데 각 과정은 다음과 같다.
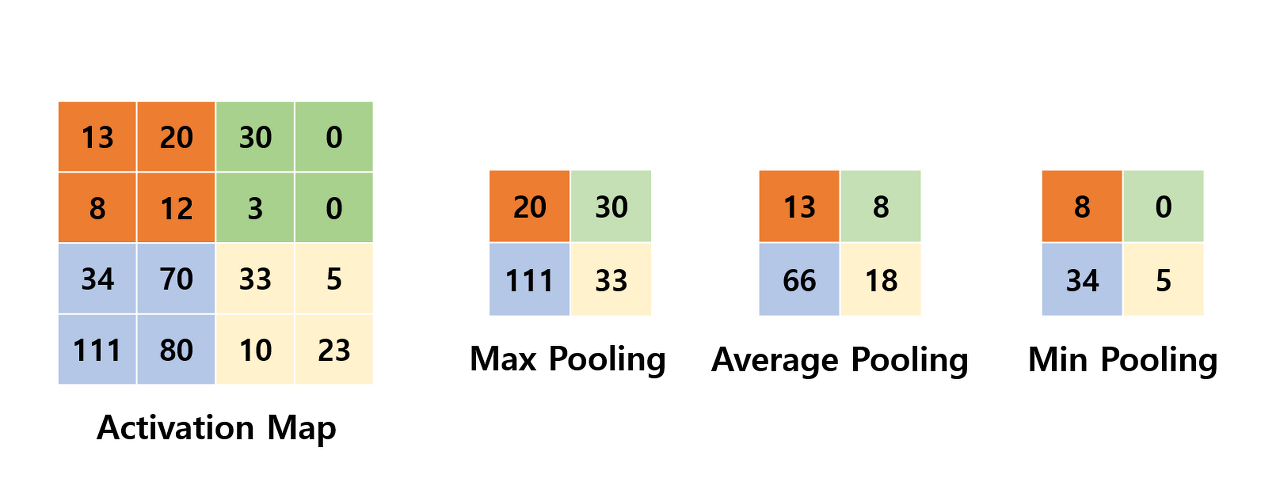
일반적으로 Pooling의 크기와 Stride의 크기를 같게 설정해 모든 원소가 한 번씩 처리되도록 한다.
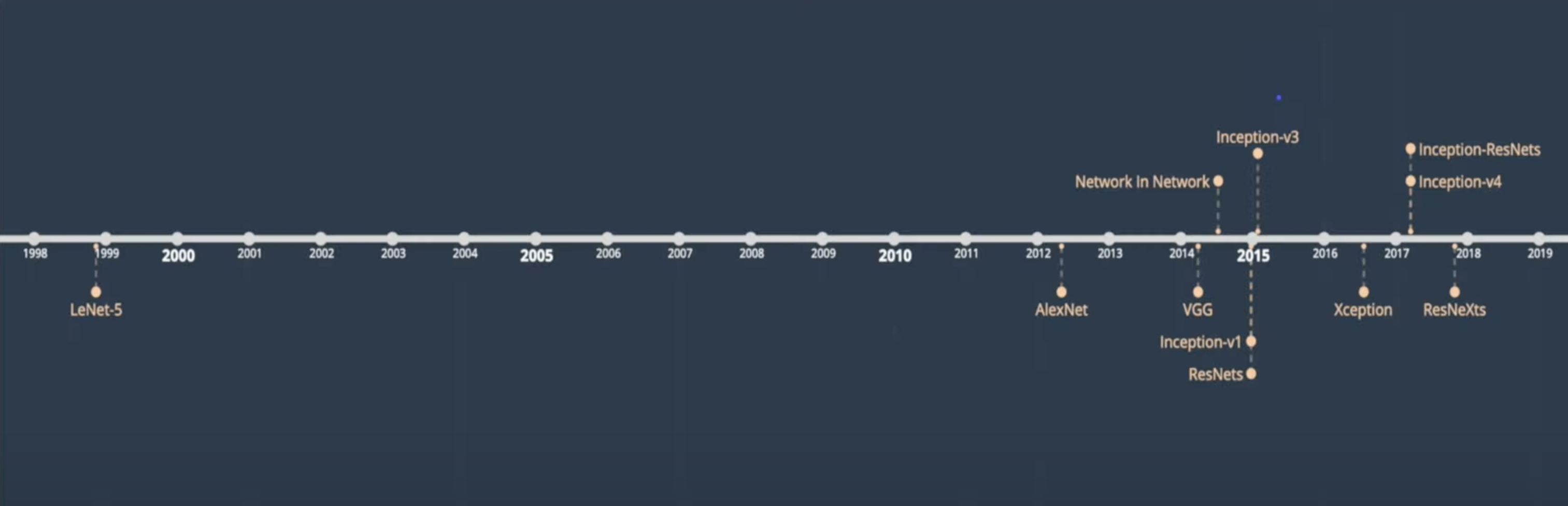
0-1. Lenet
이런 CNN의 특징을 지닌 가장 기본적인 모델이 바로 LeNet이다.

LeNet은 CNN을 처음 만든 얀 르쿤(Yann LeCun)이 1995년 처음 발표한 모델이다.
이 당시에는 우편봉투에 쓰인 POSTCODE(숫자 데이터)를 인식하는 task가 주요 과제였고, 이를 학습시키는 과정에서 등장한 데이터셋이 바로 오늘날 딥러닝 모델 학습에서 가장 기본으로 사용되는 MNIST dataset이다.

사실 LeNet이 나오기 전에도 이런 image classification에 대한 연구는 많이 진행되고 있었다.
- Baseline Linear Classifier
- Baseline Nearest Neighbor Classifier
- Pairwise Linear Classifier
- Principle Component Analysis and Polynomial Classifier
- Radial Basis Function Network
- Large Fully Connected Multi-Layer Neural Network
- Tangent Distance Classifier
- Optimal Margin Classifier
위 알고리즘들은 CNN 기반의 딥러닝 알고리즘이 나오기 전 연구되던 Image classification method이다.
그러나 1995년 LeNet이 처음 나왔을 때, 기존의 알고리즘보다 성능이 훨씬 더 잘 나왔기 때문에 현재까지 CNN 기반의 모델들이 더욱 더 발전해 왔다.
LeNet이 처음 논문에 등장한 것은 1995년이고, 최종적인 결과를 낸 것이 1998년이다.
1995년에는 NIST dataset을, 1998년에는 MNIST dataset을 이용해 모델을 학습시켰다.
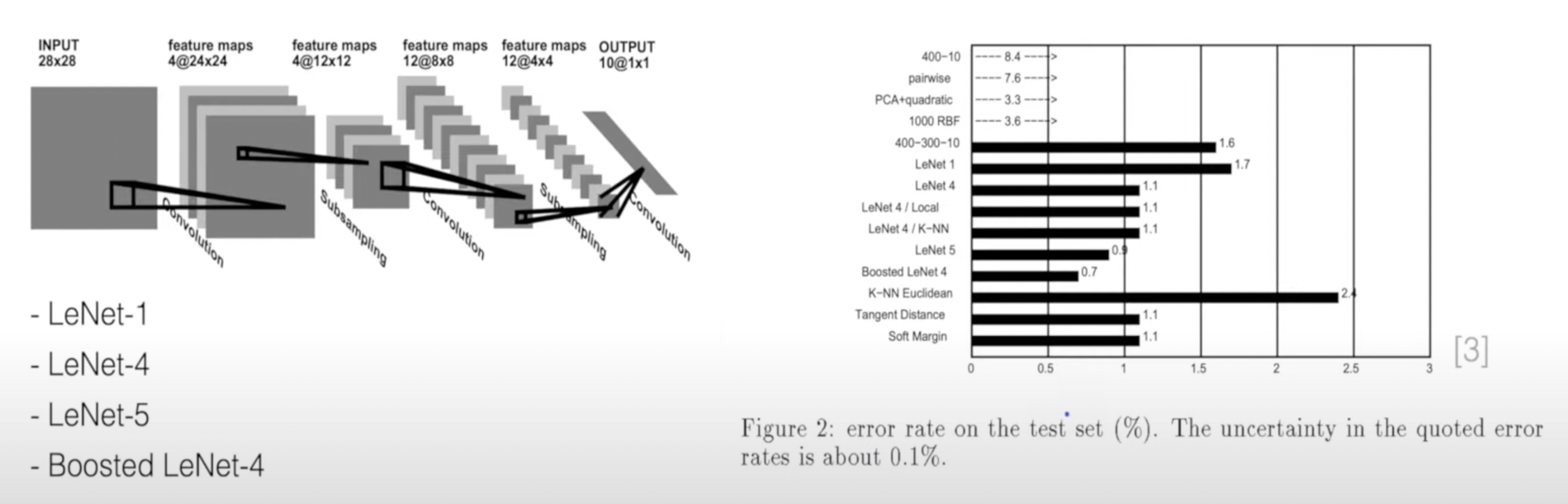
LeNet은 이때 당시 MNIST data 기준 99.05%에 달하는 정확도를 달성했다고 한다.
0-2. Alexnet
비록 LeNet이 MNIST data 기준 99.05%라는 매우 좋은 정확도를 달성했지만, 더 복잡한 데이터(얼굴, 사물인식)를 다루기에는 컴퓨터 연산 능력이 턱없이 부족하였다. (이때 당시에는 기존의 알고리즘(HarrCascade, SIFT feature extractor with SVM 등)이 더 널리 사용되었다.)
이러던 중 등장한 것이 바로 AlexNet이다.
AlexNet과 기존의 LeNet-5의 가장 큰 차이점은 바로 연산시 병렬 처리가 가능하다는 것이다.
당시 AlexNet을 학습시키기 위해 GTX 580 2개를 사용하였다는데, AlexNet의 구조를 살펴보면 다음과 같다.
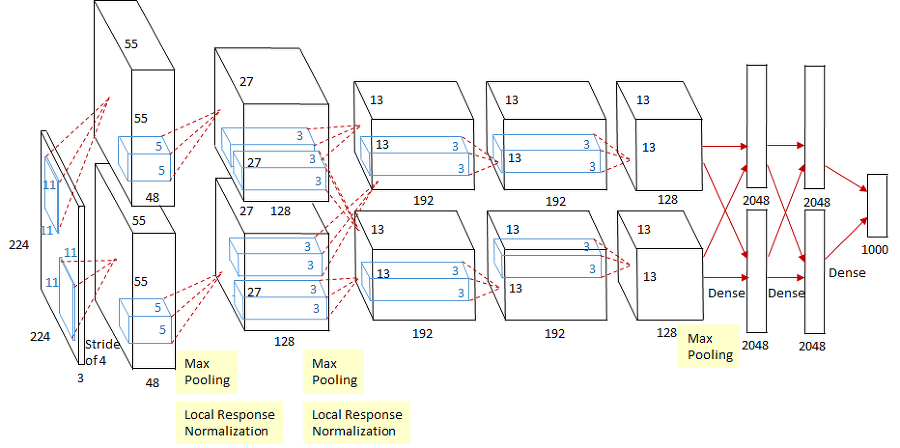
기존 LeNet-5에서 input data size는 32x32이지만, AlexNet은 224x224이다.
AlexNet은 ImageNet test(Top-5)에서 정확도를 74%에서 84%로 약 10%나 증가시켰다.
이외에도 AlexNet은 다음과 같은 특징이 있다.
1. ReLU function의 사용
AlexNet에서는 activation function으로 ReLU function을 사용하였고, 모델의 사이즈(파라미터 수)가 커짐에 따라 발생할 수 있는 과적합 문제를 해결하기 위해 dropout을 사용하였다.
이전의 LeNet-5에서는 활성화 함수로 Tanh를 사용하였는데 ReLU와 비교했을때 속도가 6배나 차이 난다고 한다. AlexNet 이후부터는 ReLU가 활성화 함수의 주요 메소드로 활용되었다.
2. Local Response Normalization (LRN) 사용

ReLU함수는 input이 0 이상일때 output을 그대로 내보낸다. 이는 학습 속도가 굉장히 빠르다는 장점이 있지만 CNN에서는 큰 input이 들어왔을때 그 값 그대로를 전달하여, 주변 값(상대적으로 작은)들이 뉴런에 전달되는 것을 막을 수 있다는 단점이 있다. 이를 예방하기 위한 방법이 바로 Local Response Normalization이다.
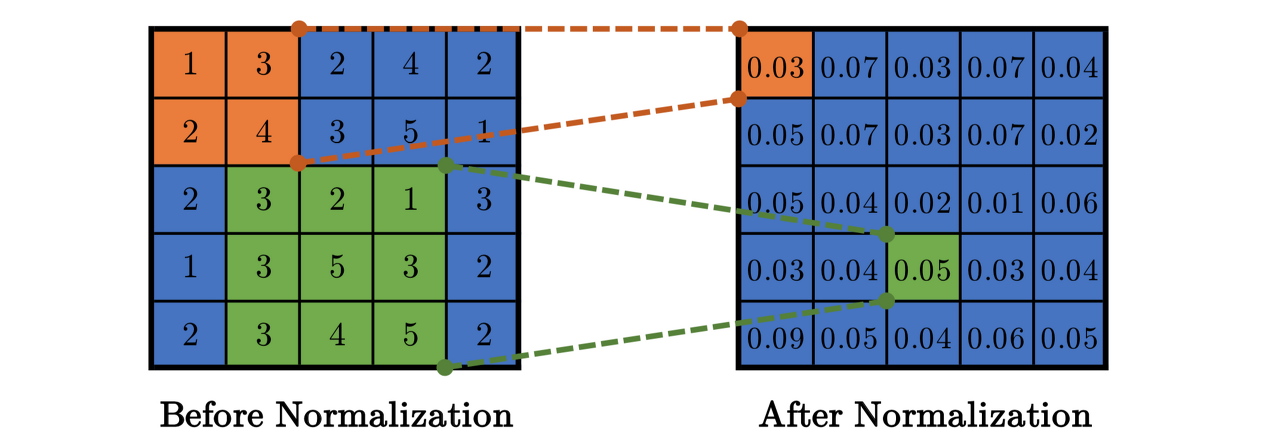
이 과정은 활성화 함수를 적용하기 전에 일어나는데, 인접한 채널에서 같은 위치에 있는 픽셀 n개를 통해 정규화 시켜준다.
오늘날에는 Local Response Normalization 대신 Batch Normalization을 대부분 사용한다.
(Local Response Normalization과 Batch Normalization의 차이)
3. Data augmentation
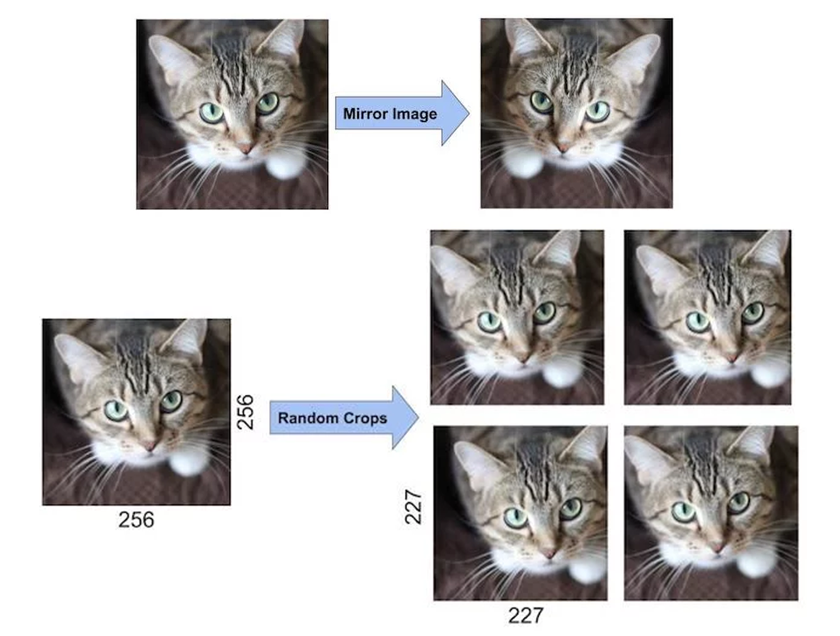
Data augmentation은 현재 갖고있는 데이터를 변형하여 다양한 데이터를 얻는 기법이다.
AlexNet에서는 데이터를 수평 반전 및 랜덤으로 잘라서 하나의 이미지당 10개정도의 이미지를 생성해 그 예측값들의 평균을 최종 예측값으로 사용했다.
0-3. VGGNet
AlexNet이 좋은 성과를 내면서, CNN은 학계의 엄청난 주목을 받았고, VGGNet와 같은 후속 모델들이 계속해서 나왔다.
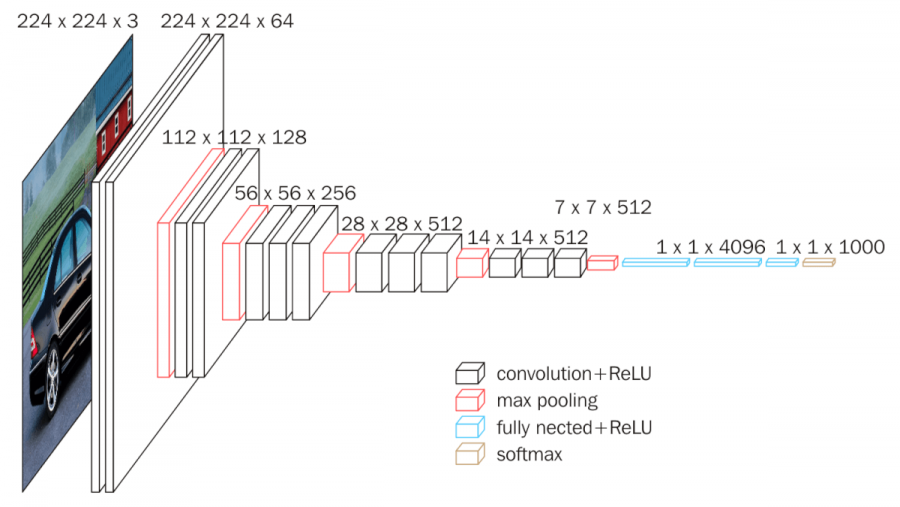
💡VGGNet 연구의 핵심은 뉴럴 네트워크의 깊이가 과연 성능 변화의 차이에 큰 영향을 주는가 였다.
AlexNet이 5개의 convolution layer를 사용했던 것에 비해 VGG-16은 13개의 convolution layer과 3개의 fully connected layer으로 총 16개의 layer를 사용하였다.
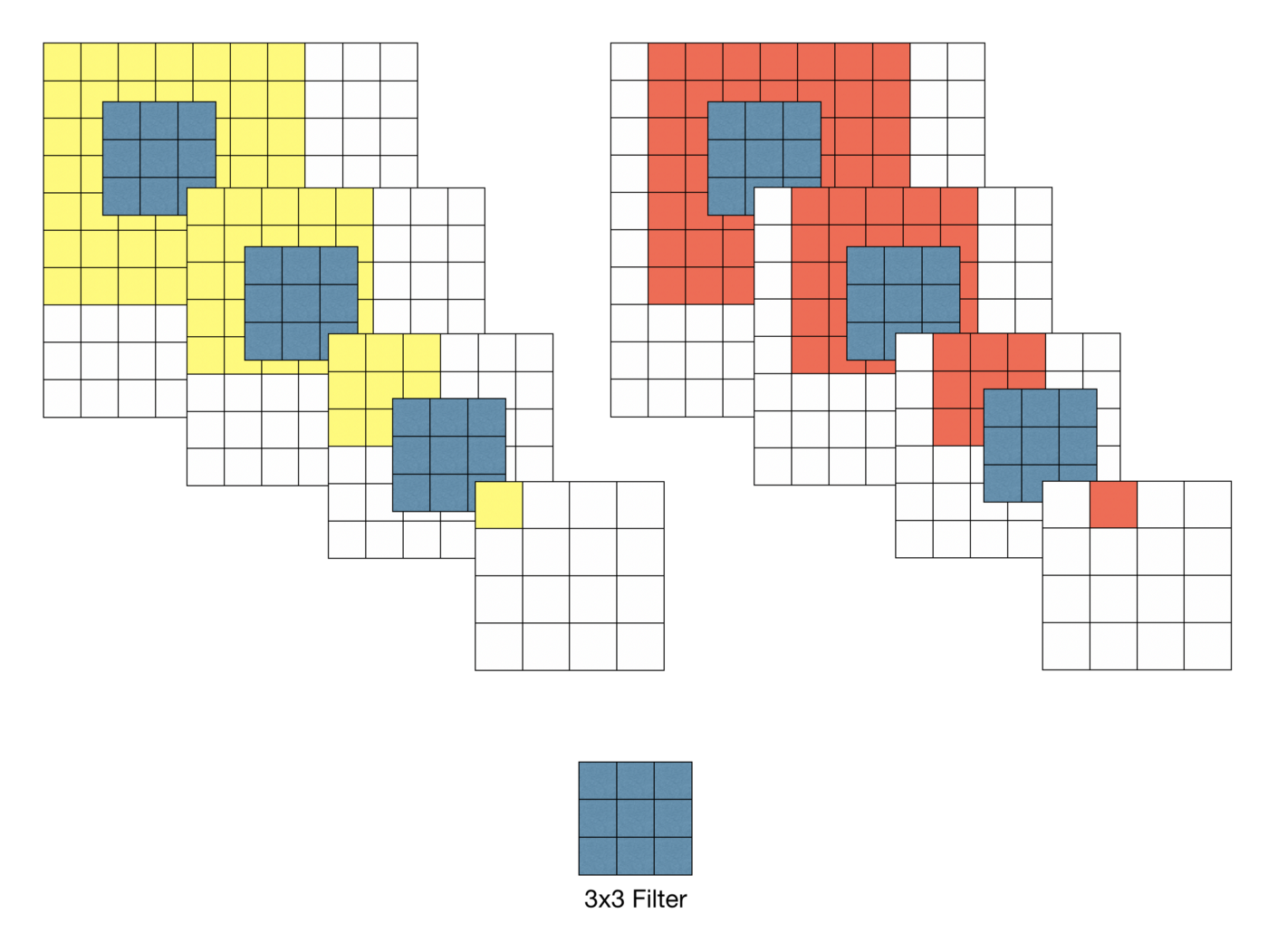
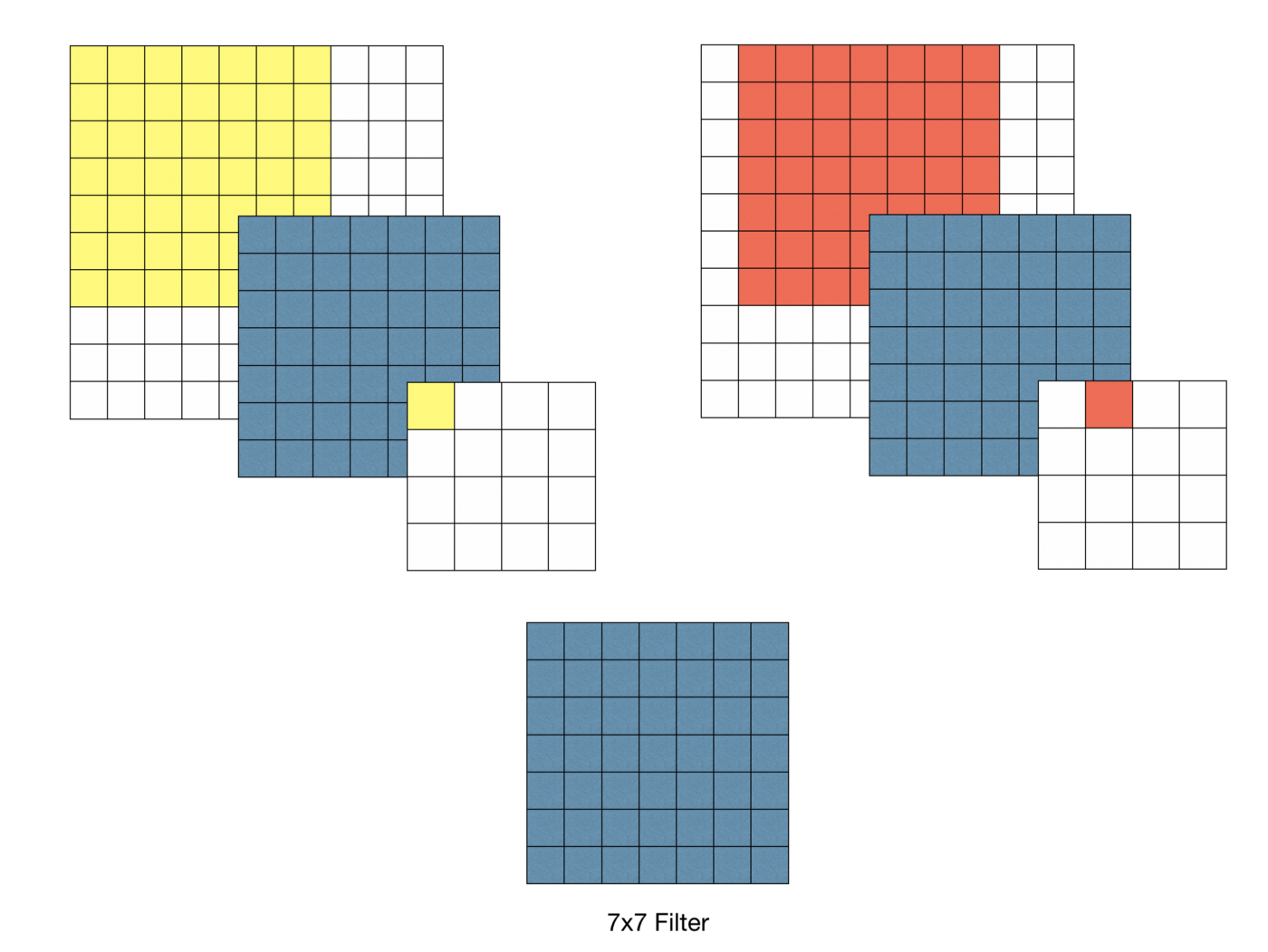
그러나 VGG가 등장한 논문에서 3x3 하나의 필터로 여러 차례(3차례) convolution 하는 것이 7x7 필터로 convolution하는 것과 동일한 결과를 낼 수 있다고 밝혀졌다.
동일한 결과라면 VGGNet에서는 왜 3x3을 세번 사용하였을까?
1. 결정 함수의 비선형성 증가
각 Convolution 연산에는 ReLU함수가 포함된다. 7x7 필터링을 한 번 사용하면 비선형 함수가 한 번 적용되는 반면, 3x3 필터링을 세 번 사용한다면 세 번의 비선형 함수가 적용된다.
이는, 레이어가 깊어짐에 따라 비선형성이 증가해 모델이 특징 식별을 더 잘 할 수 있게 해준다.
2. 학습 파라미터 수의 감소
convolution network를 학습할때, 학습 대상인 가중치(weight)는 필터의 크기에 해당한다.
7x7의 경우 학습 파라미터 수는 7x7=49개이고, 3x3을 세 번 사용하는 경우 3x3x3=27개다.
0-4. Network in Network
Network in Network(NIN)는 2014년 ICLR에서 발표된 논문으로서 뒤에 나오는 Inception 모델을 이해하는데 꼭 필요한 개념이다.
Network in Network의 전체적인 구조를 보면 다음과 같다.
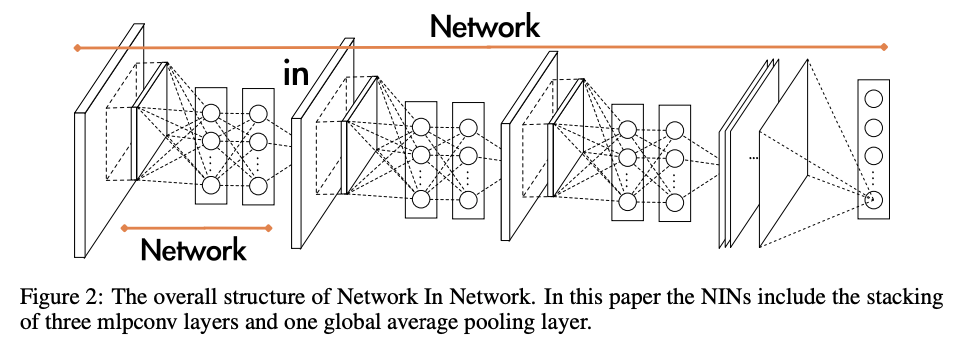
핵심 아이디어는 기존 CNN의 Conv-Activation-Conv와 같은 단순한 Linear convolution layer 구조로는, 필터가 늘어남에 따라 기하급수적으로 늘어나는 연산량을 해결할 수 없었고, 더 복잡한 차원의 Nonlinearlity 역시 충분히 표현할 수 없기때문에 MLP(Multi layer perceptron)를 사용하자는 것이다.
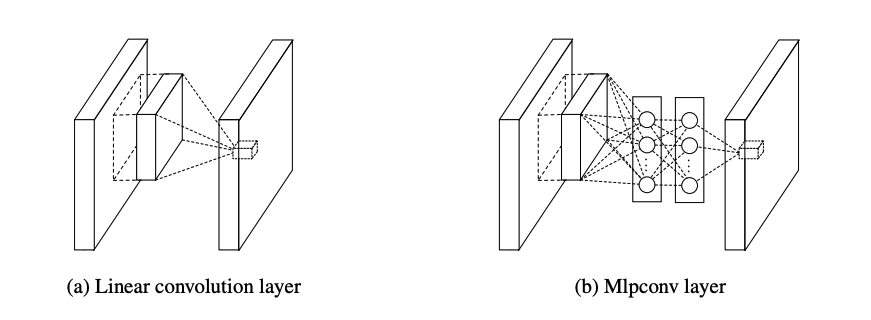
1x1 convolution layer를 사용하는 가장 큰 이유는 차원을 줄이기 위함이다.
사실 Feature map의 channel이 다음과 같이 1개 뿐이라면 1x1 convolution layer를 이용해도 아래와 같이 차원축소는 커녕 연산의 별 의미가 없을 것이다. (단순 2를 곱해주는 것이므로)
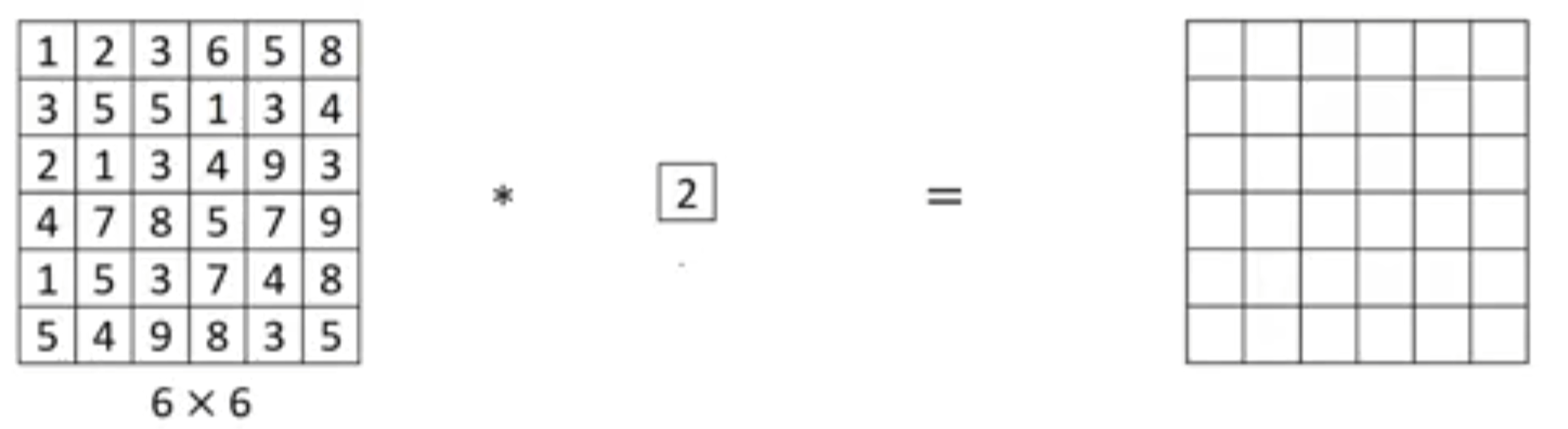
그러나 아래 그림처럼 channel이 여러개로 쌓여있는 구조라면 기존의 Fully connected layer을 이용했을 때 보다 연산량이 훨씬 적음을 알 수 있다.
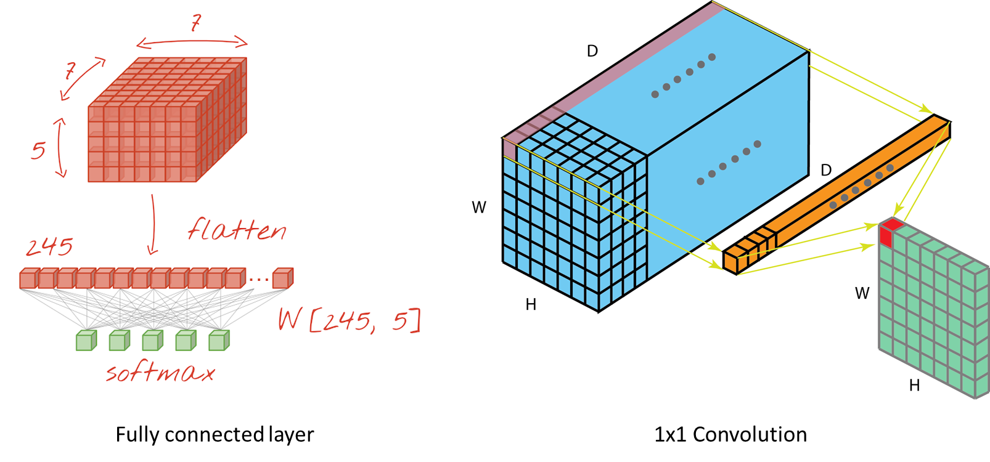
좌측 그림은 Feature map을 flatten 해준 후 가중치 matrix w와 하나하나 곱해져서 FC layer로 전달되는 구조이다.
이때 Feature amp의 모든 값 하나하나가 다른 weight를 가지므로 학습해야될 파라미터 수가 굉장히 많다.
반면 우측 그림은 1x1 convolution layer를 이용한 것인데, Feature map값과 1x1 convolution layer의 각 Filter값 하나하나가 곱해져 새로운 Feature map이 만들어진다. 결과적으로는 연산도 줄어들고 차원도 훨씬 줄어들었음을 볼 수 있다.
1. Inception v1 (GoogLeNet)
1-1. Inception 개요
딥러닝 모델의 성능을 높이는 가장 간단한 방법은 모델(네트워크)의 깊이를 깊고 넓게 만들면 된다.
그러나 이 방법에는 두 가지 큰 문제가 존재한다.
- 모델의 사이즈가 커지면, 학습해야 할 파라미터들이 많아지고 이는 과적합으로 이어질 수 있다.
- 컴퓨팅 파워(컴퓨터 연산의 한계 및 자원 낭비)의 문제가 있다.
이러한 문제를 해결하는 핵심 키워드로 나온것이 바로 "Inception" 모델 구조이다.
구글이 발표한 Incaption v1(GoogLeNet)은 AlexNet보다 학습할 파라미터의 수는 12배 적지만, 정확도는 훨씬 높다.
Inception module이 나오게 된 흐름을 생각해보면 다음과 같다.
- Conv filter size가 작다면 -> 위치적 정보는 잘 볼 수 있지만 local region에 너무 집착한다. (나무만 보고 숲은 안본다)
- Conv filter size가 크다면 -> 추상화 정도는 올라가지만 위치 정보는 떨어진다. (숲을 보는데 나무는 안본다)
=> 어차피 이런 trade-off 관계일거면 순차적으로 쓰거나 하지말고 다 같이 한번에 쓰자!
1-2. Inception module
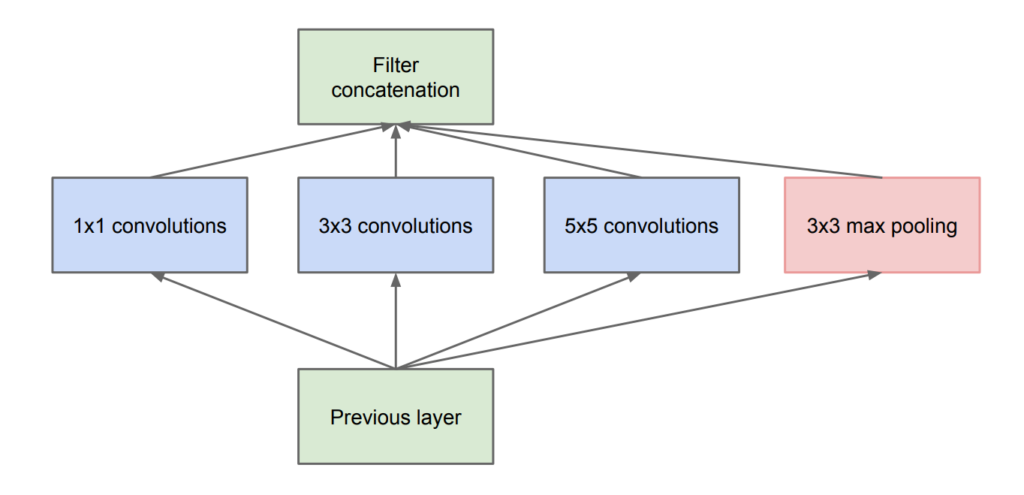
Inception module의 맨 처음 등장한 naive version은 다음과 같다.
그러나 이러한 구조는 Feauture map의 channel이 많을 경우(우측 그림의 파란색 모형) 굉장히 복잡한 연산을 필요로 한다. 또한 max pooling의 특성상 input channel과 output channel의 개수가 같아야하는데 이 모든 output들을 merge해주려면 엄청난 계산을 필요로한다.
따라서 1x1 conv를 사용해 차원을 축소한 후 연산을 진행하는 방식으로 다시 만들게 되었고 아래 그림과 같은 구조이다.
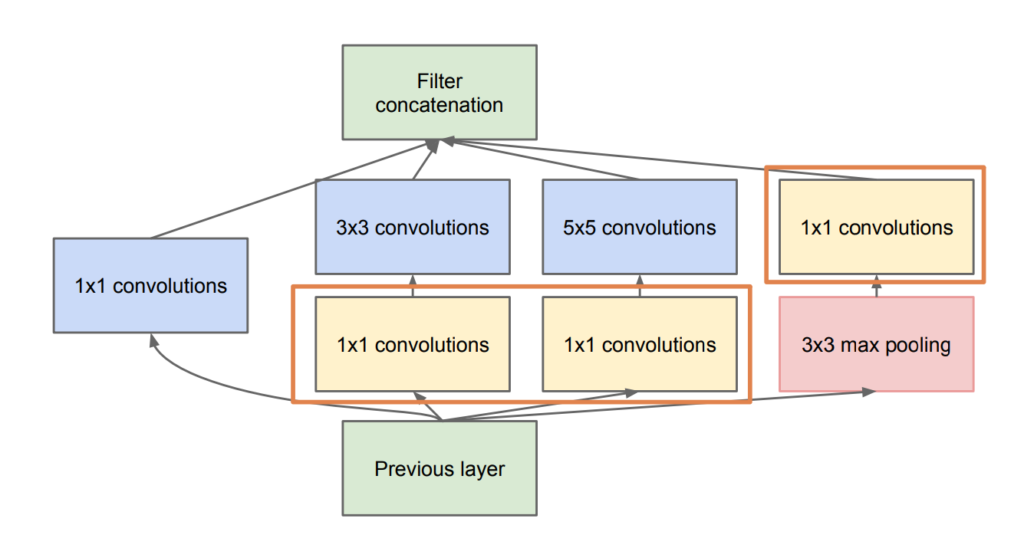
이렇게 1x1 conv layer를 이용함으로서 모델의 깊이와 넓이도 깊어지고, 무엇보다 차원축소의 역할을 통해 계산량이 엄청나게 줄어든다.
예를들어, 480장의 14x14 사이즈의 feature map이 있다고 가정해보자.
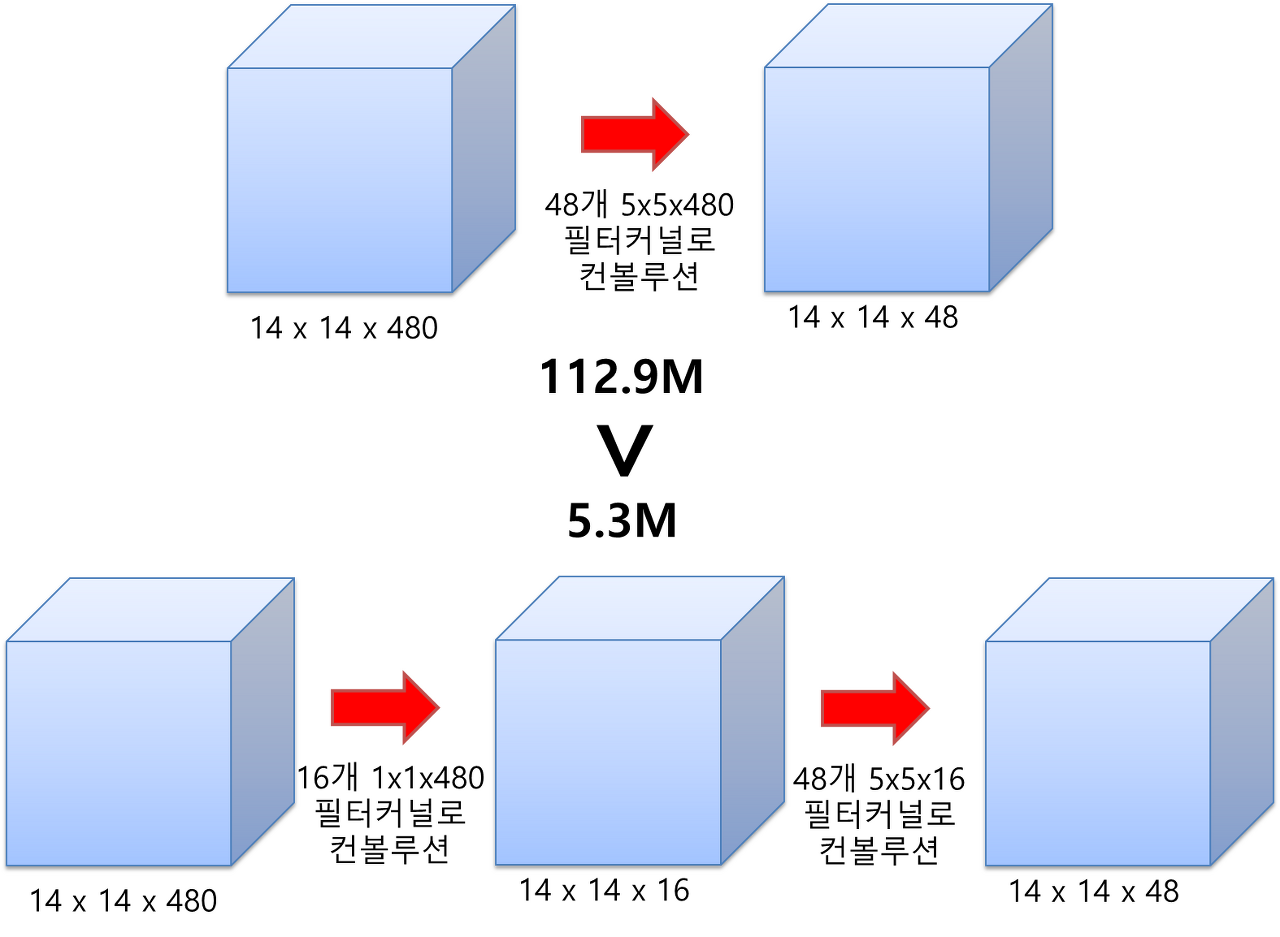
이것을 48개의 5x5x480 필터로 convolution을 해주면, 14x14의 feature map이 48장 생성 될 것이다. (zero-padding:2, stride : 1로 가정) 이때 필요한 연산 횟수는 (14 * 14 * 48) * (5 * 5 * 480) = 약 112.9M이다.
반면 1x1x480 필터(1x1 conv layer)로 convolution을 해줘 특성맵의 갯수(차원)를 줄인 후 연산을 진행하면,
(14 * 14 * 16) * (1 * 1 * 480) + (14 * 14 * 48) * (5 * 5 * 16) = 약 5.3M이다.
이는 약 20배가 넘게 연산량이 줄었음을 보여준다.
1-3. Inception V1(GoogLeNet)
GoogLeNet의 구조는 아래와 같다.
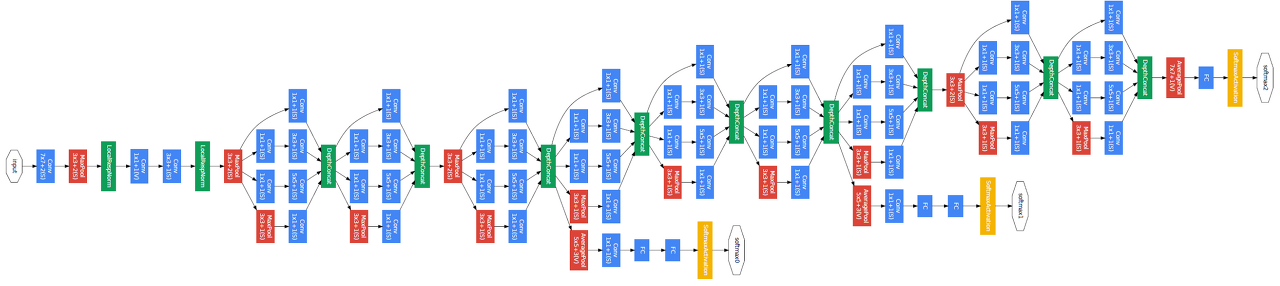
여기서 위에 설명한 Inception 모듈을 표시해보면 이렇게나 많이 있다.
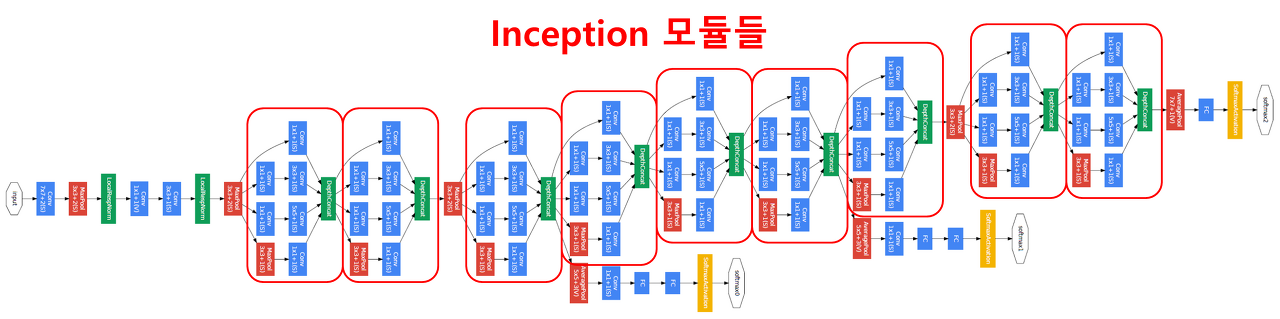
GoogLeNet은 Inception모듈을 활용해 데이터의 더 다양한 종류의 특성을 도출하며 연산량은 훨씬 줄였다.
GoogLeNet의 또 다른 특징중 하나는 auxiliary classifier network를 사용한다는 것이다.
모델의 네트워크 깊이가 깊어지면 back propagation(역전파) 과정에서 gradient vanishing 문제가 발생 할 수 있다.
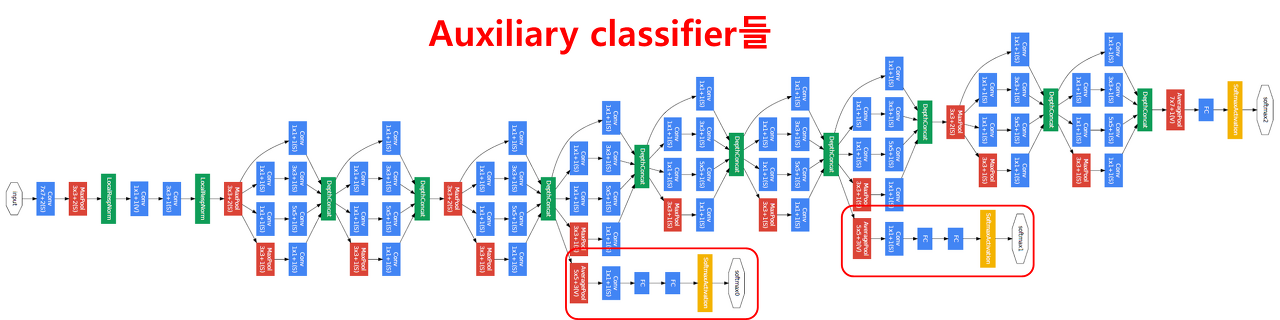
auxiliary classifier network를 사용해 역전파과정에서 gradient signal을 증폭시키는데, 모델을 학습시킬때만 30%의 가중치를 가지고 학습을 진행하고, 학습이 끝나면 사용하지 않는다. (관리자같은 역할)
1-4. 결론
GoogLeNet은 같은 해에 나온 VGG에 비해 성능이 눈에 띄게 좋아지지는 않았다.
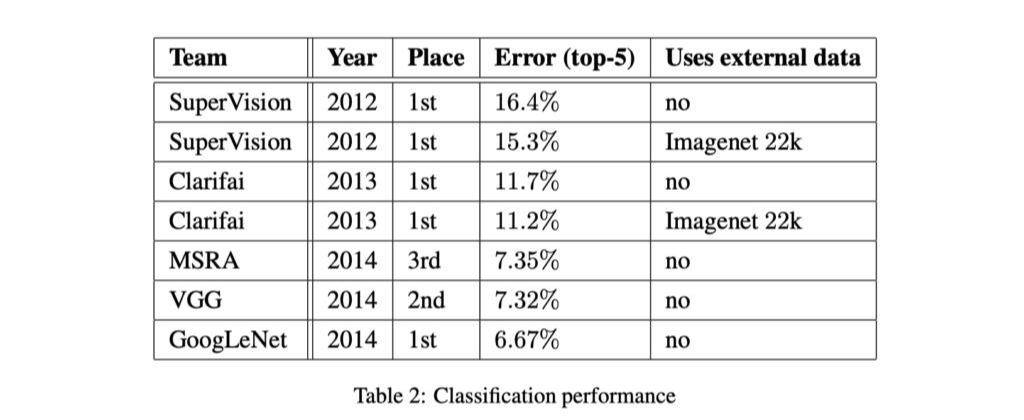
그러나 구글에서는 "다른 모델들로도 GoogLeNet과 비슷한 depth와 width를 만들어 비슷한 성능을 낼 수 있을지 모르나, 훨씬 무겁고 학습하기 힘들 것이다" 라고 말하고 있다.
2. Inception V2, V3
2-1. Inception V2
Inception V2 모델에서는 기존 GoogLeNet(Inception V1)에서 연산량을 더 줄여보기 위해 기존 Filter를 나누어 사용했다.
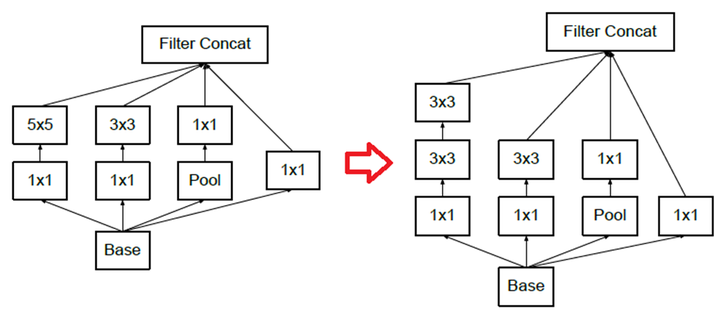
기존의 5x5 Conv layer 를 2개의 3x3 Conv layer로 대체해서 파라미터 수를 5x5 = 25개에서 3x3x2 = 18로 줄였고,
7x7 Conv layer 역시 3개의 3x3 Conv layer로 대체해서 7x7 = 49개에서 3x3x3 = 27로 약 45%나 줄였다.
또한 nxn Conv layer 역시 1xn과 nx1 Conv layer를 이용해 나눠주었는데, 최종적인 Inception module의 구조는 다음과 같다.
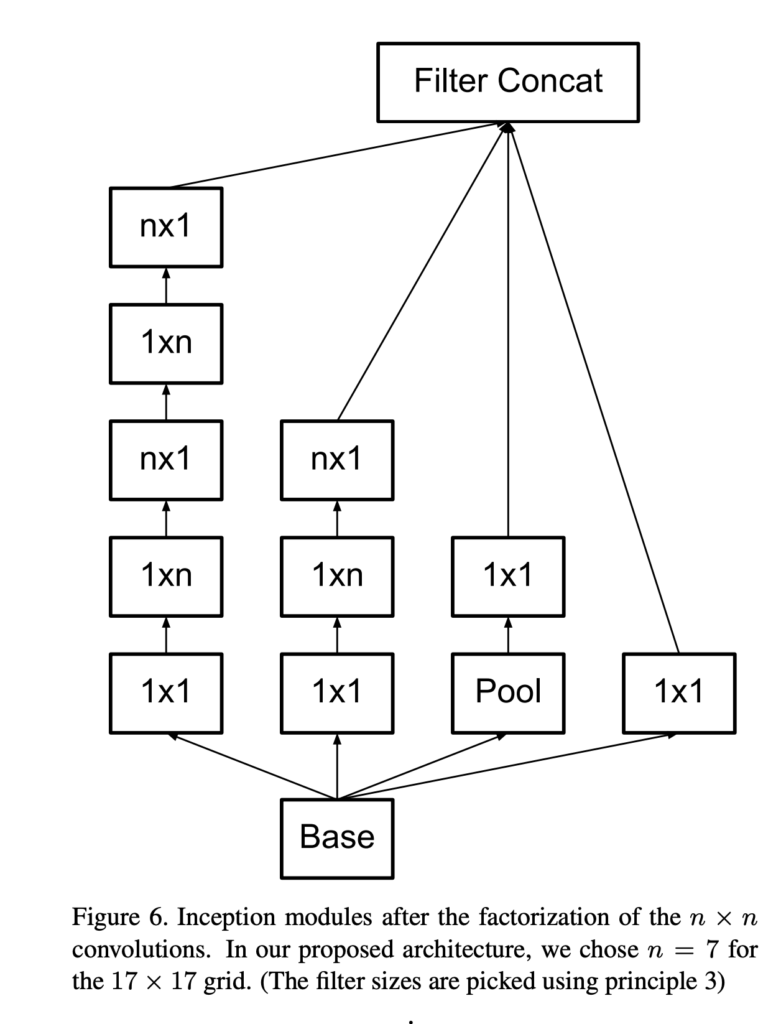
또한 Inception v2의 구조를 보면 GoogLeNet에서 사용되던 Auxiliary Classifier 2개중 하나가 사라진 것을 볼 수 있다.
(모델의 초반에 있던 Auxiliary Classifier는 쓸모없다는게 밝혀지면서 없애버렸다.)
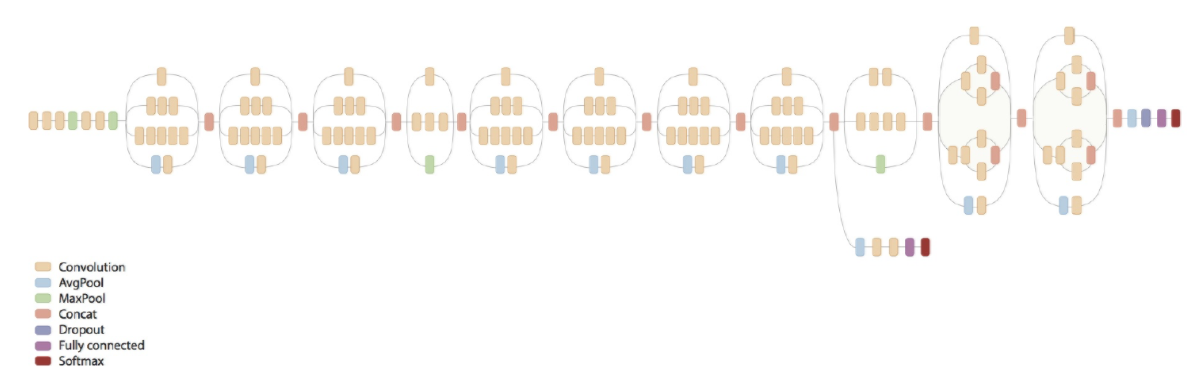
2-2. Inception V3
V3 모델은 V2를 만들고 여러 파라미터를 수정해보다가 결과가 더 좋게 나온 것을 합친 모델이다.
변경 사항은 다음과 같다.
- Optimizer 변경
- RMSProp으로 변경
- Label Smoothing
- Target 값을 one-hot encoding을 사용 X -> 오버피팅방지
- 값이 0 인 레이블에 대해서도 아주 작은 값 ee 를 배분
- 정답은 1−(n−1)×e1−(n−1)×e 로 값을 반영하여 사용
- BN-auxiliary
- 마지막 Fully Conntected layer에 Batch Normalization (BN) 적용
2-3. 결론
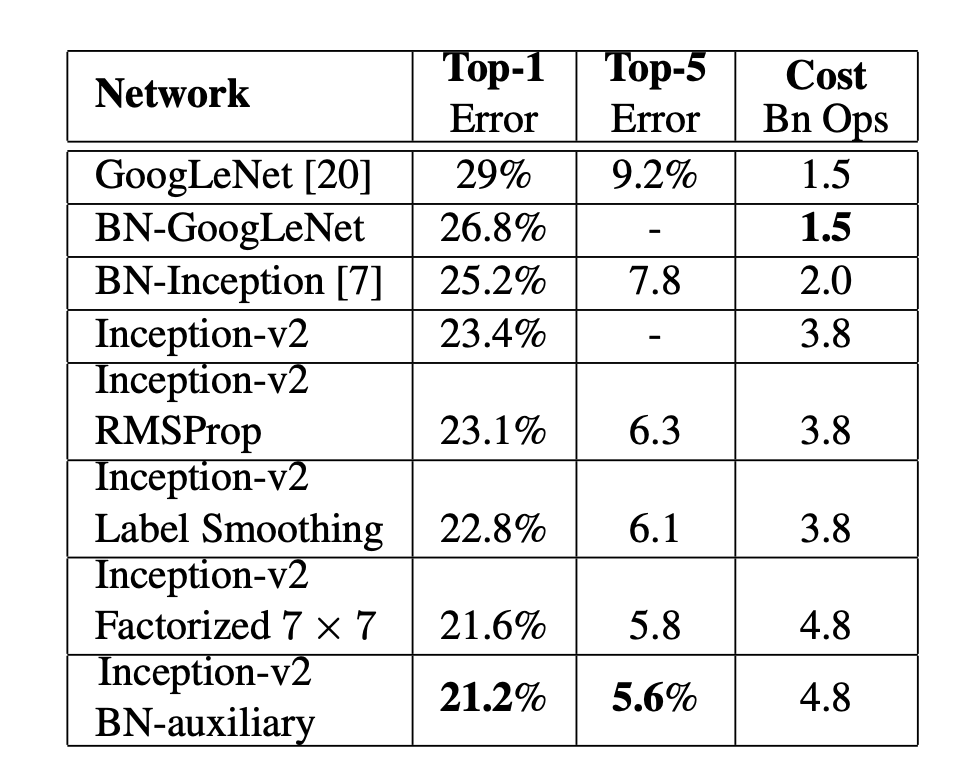
위에 보이는 표는 Inception-v2에서 한 칸 내려갈 수록 추가되는 기법만 명시하고 이전의 기법들은 기본적으로 사용하고있다. 성능이 제일 좋은(제일 아래에 있는) Inception-v2 BN-auxiliary는 RMSProp + Label Smoothing Factorized 7 x 7 + BN-auxiliary을 다 사용한 것이고 이 모델을 Inception v3라고 부른다.
3. Inception V4
3-1. Inception-v4의 구조
기존의 Inception 모델들(~V3)은 뛰어난 성능은 인정받았지만 모델의 구조가 너무 복잡하다는 평가를 받았다.
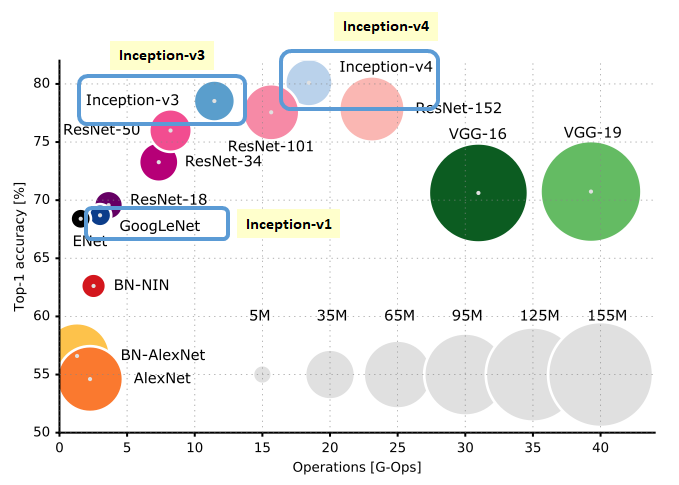
이 복잡성 때문에 이미지 분류 대회에서 좋은 성적을 거두던 Inception 계열의 모델들 보다 VGGnet이 더 흔하게 사용되었다.
이에 2017년, Inception-v3보다 단순하고 획일화된 구조와 더 많은 Inception module을 사용한 Inception V4가 등장하였다.
아래는 Inception V4의 기본 구조이다.

Stem, Inception-A, inception-B, inception-C, reduction-A, reduction-B의 각 모듈별로 구조를 살펴보자.
V표시가 되어있는 것은 padding을 적용하지 않은 것이다. (output의 크기가 달라짐)
V표시가 없다면, zero-padding을 적용해 입력과 출력의 feature map 크기를 같게 만들어 준 것이다.
stem
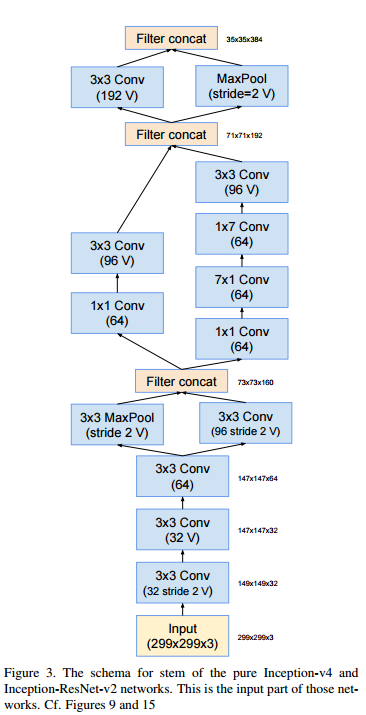
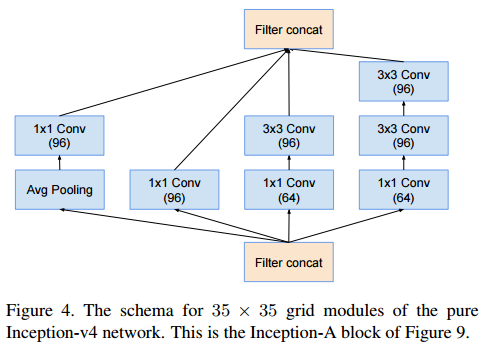
Inception-A
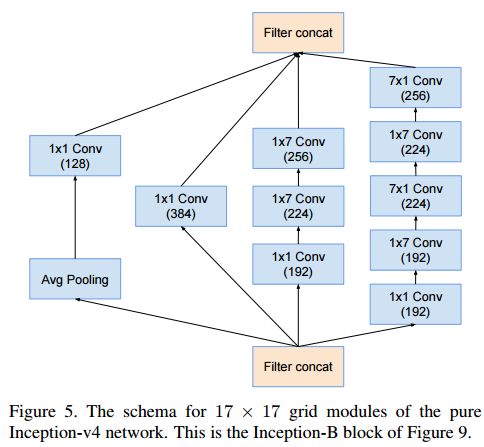
Inception-B
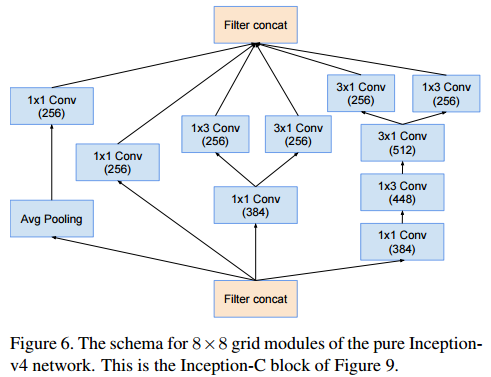
Inception-C
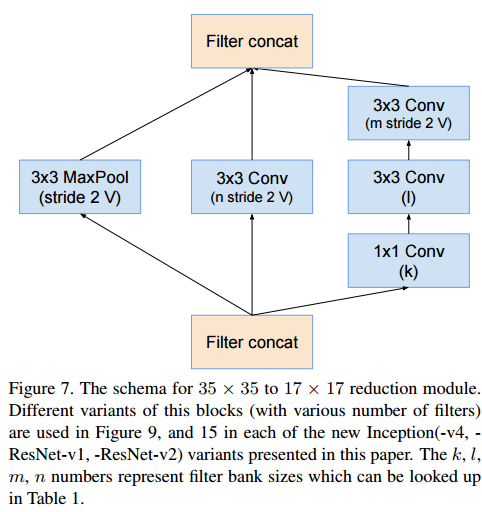
Reduction-A
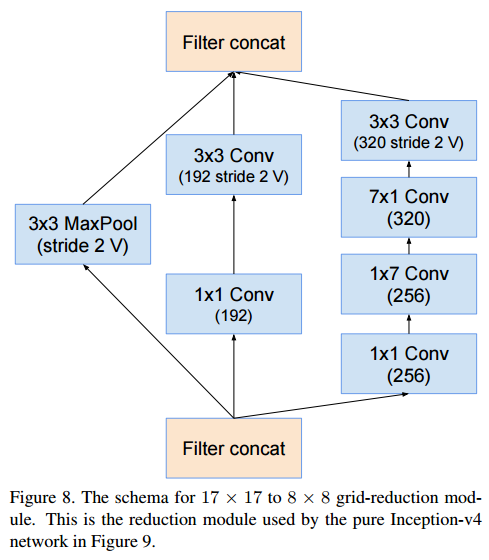
Reduction-B
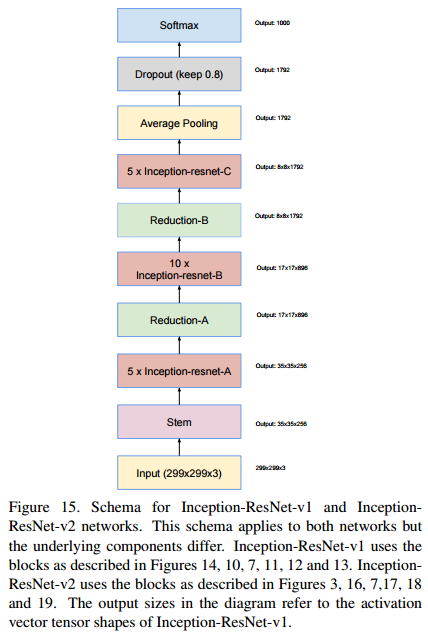
3-2. Inception + ResNet
기존의 Inception model에 residual connections을 결합해 더 빠른 학습을 가능하게 하였다.

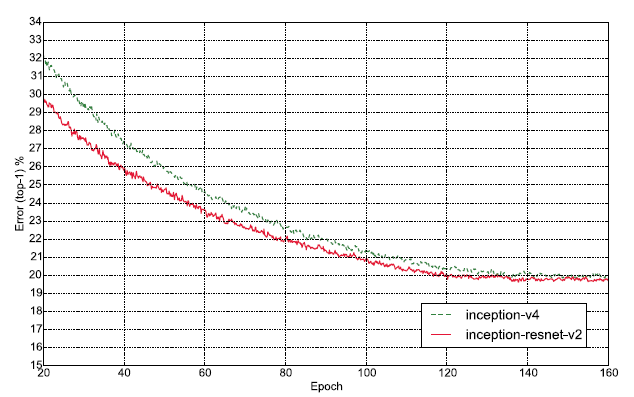
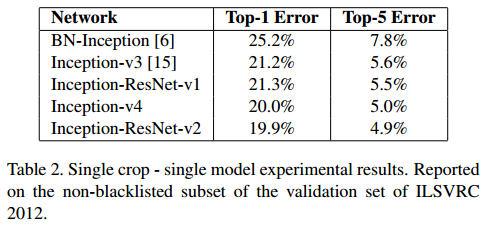
3-3. 결론
'AI Theory > DL Basic' 카테고리의 다른 글
| [Pytorch] torch.nn.Module에는 어떤 method가 있을까? (0) | 2022.09.29 |
|---|---|
| [Pytorch] torch.gather vs torch.Tensor.scatter_ (pytorch 인덱싱 방법) (0) | 2022.09.29 |
| 딥러닝을 위한 경사하강법(Gradient Descent) (1) | 2022.09.23 |
| [딥러닝기초] 머신러닝 흐름 파악하기 (0) | 2022.03.16 |
| 딥러닝을 위한 Window10 Docker 설치 방법 (윈도우 도커 설치 방법) (1) | 2022.03.11 |




댓글