- Reference
Kaist Edward Choi 교수님의 Programming for AI(AI 504, Fall2020)
딥 러닝을 이용한 자연어 처리 입문(Wikidocs)
0. 들어가기에 앞서
이미지 데이터를 분석하는 기존의 컴퓨터 비전(CV)과 텍스트 데이터를 분석하는 자연어 처리(NLP)는 어떤 차이점이 있을까?
컴퓨터 비전은 image - to - label task(Input size is fixed)를, 자연어 처리는 sentence - to - label task(Input size varies by sample)를 주로 수행하는 것이 일반적이다.
우리가 자연어 처리에서 RNN을 사용하는 이유는 RNN계열의 모델은 이런 input size가 매번 바뀌는 task에 적합한 구조를 갖고있기 때문이다.
Bag-Of-Words
단어의 등장 빈도수를 담는 매우 sparse한 matrix
I gave the ball to John, who gave it to Mary
I gave the ball to Mary, who gave it to John
=> 이 두 문장은 다른 의미지만 빈도수는 서로 동일하다(같은 Bag-Of-Words)
=> 문장의 순서를 고려하지 못한다는게 BOW의 가장 큰 문제점
1. RNN
1-1. RNN의 등장

RNN은 hidden layer에서 활성화 함수를 거쳐 나온 output을 다시 새로운 hidden layer의 Input으로 보내는 구조를 띄고 있다.

이때 hidden layer를 구하는 식은 위와 같다.
W와 U는 학습이 진행됨에 따라 업데이트 되는 가중치이고, xt는 t번째 input, b는 bias를 의미한다.
식을 자세히 보면 ht가 ht-1에 영향을 받는 점화식 형태임을 알 수 있다.
각 벡터들의 크기를 살펴보면 우선 xt는 단어벡터로 그 크기는 d로, hidden layer h의 크기는 Dh라고 하자.
이때 각 벡터의 크기는 다음과 같다.
W : (Dh*d)
xt : (d*1)
U : (Dh*Dh)
ht-1 : (Dh*1)
b : (Dh*1)
이때 output으로 출력된 ht의 크기는 (Dh*1) 차원일 것이다.
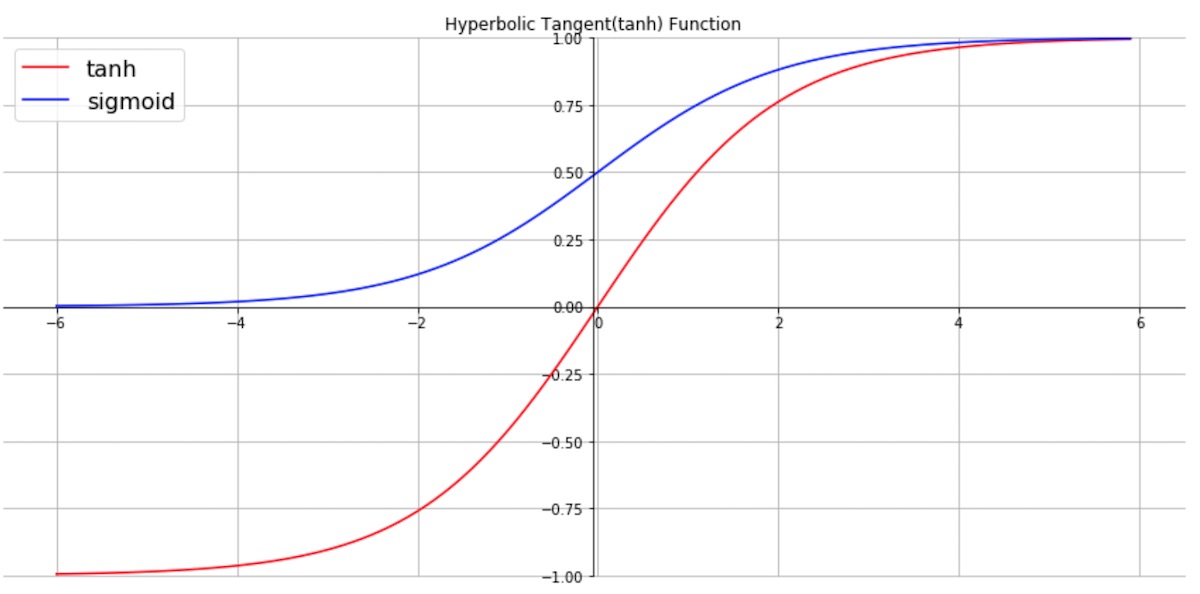
f함수 즉 activation function으로는 주로 tanh를 사용한다.
Sigmoid와 ReLU도 사용하긴 하지만, sigmoid는 gradient vanishing problem이, ReLU는 이전 step의 값을 재귀적으로 가져와서 사용하는 RNN의 특성 상 이전 값이 커지면 전체적인 출력이 발산하는 문제가 생길 수 있기 때문이다.
일반적인 feed forward neural network에서 다음 layer로 갈때마다 새로운 W matrix를 사용한다..
그러나 RNN에서는 하나의 W와 U matrix를 계속 반복해서 업데이트 해가며 사용한다.
만약 output의 크기가 1이 아니라면 RNN의 구조는 다음과 같을 것이다.

1-2. RNN은 어디에 쓰이나
RNN 모델의 형태는 어떤 task를 수행하느냐에 따라 다음과 같이 달라진다.

일 대 다(one-to-many) 구조 : 하나의 이미지 입력에 대해 사진의 제목을 출력하는 이미지 캡셔닝
다 대 일(many-to-one) 구조 : 감성분류(Sentiment classification), 스팸 메일 분류
다 대 다(many-to-many) 구조 : 챗봇, 번역기, 개체명 인식 및 품사 태깅
RNN은 아래와 같은 다양한 자연어처리(NLP) 혹은 시계열 데이터 예측(Time Series data forecasting)에 쓰일 수 있는다.
<RNN의 쓰임 예시>
- Sequence-level classification / regression
- Sentiment classification -> binary
- Topic Classification -> multiclass
- Classification/regression at each step
- Language modeling
- Part-of-speech tagging
- Sequence-to-sequence
- Translation
- Question answering
1-2-1. Example 1 : Sequence-level Sentiment classification
Sequence-level Sentiment classification(문장 수준의 감성 분류)를 한다고 할때 다음과 같은 문장이 있다고 해보자.
"This movie is as impressive as a preschool Christmas play"
이 문장이 긍정(positive)인지 부정(negative)인지 판단하는 모델을 만든다고 해보자.
우선 전통적인 Bag-Of-Words 방법를 사용하면 굉장히 큰 차원의 sparse matrix를 만든 후 SVM 혹은 Logistic regression을 통해 분류할 것이다.
그러나 "This movie is as impressive as a preschool Christmas play"와 "A preschool Christmas play is as impressive as this movie"는 같은 matrix를 갖을 것이고, 이는 문장의 순서정보를 고려하지 못한 방법이므로 예측이 정확하게 이루어지지 않을 것이다.
RNN을 사용하면 [0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, .... , 0] ( = This) 이런 This에 해당하는 원 핫 벡터를 첫 input(x1)으로 받고 h1을 만들고 이후 x2, x3 등의 값을 순차적으로 받아 최종적인 h10을 생성한다.

이때 h(hidden layer)의 차원의 크기는 hyperparmeter로 사용자가 설정하는 것이다. (120,256,1024 차원 등)
Wh와 Wi의 차원의 크기를 생각해보면 h가 128 차원이라 가정했을때 Wh는 128*128의 정사각행렬이 될 것이고, Wi는 x10이 100k 차원이라면 128*100k의 굉장히 가로로 긴 형태의 matrix가 될 것이다.
이렇게 생성된 h10을 logistic regression이나 SVM에 넣어서 분류를 진행해 주는 것이다. (yhat 생성)
이때 생성된 yhat과 원래의 y값(lablel값)을 CrossEntropy loss function 이용해 오차를 구하고 이것을 줄여주는 방향으로 업데이트 해 주면서 학습되는 것이다.
여담으로, "This movie is as impressive as a preschool Christmas play"는 부정적인 문장이다.
한국어로 해석하면, "이 영화는 유치원 크리스마스 학예회만큼 인상적이였어" 정도가 된다.
1-2-2. Example 2 : Language modeling
Language modeling이란 언어라는 현상을 모델링하고자 단어 시퀀스(문장)에 확률을 구하는 것이다.
예를 들어, P(This is a sentence)를 구해본다고 해보자.
이 세상에는 무수히 많은 단어와 문장들이 존재하므로 위 확률은 0에 가까운 정말정말 작은 수 일 것이다.
그렇지만 정말 작은 수여도 분명히 확률값은 존재 할 것이고 조건부 확률을 이용해 위 식을 바꿔서 계산해보자.
즉, P(This movie is as impressive as a preschool Christmas play)
= P(This) * P(movie | This) * P(is | This, movie) * ... * P(play | This, movie, ... , Christmas) 가 될것이다.
이를 계산하기 위해 전통적인 N-gram 방식을 이용해본다 해보자.
n-gram은 n개의 연속적인 단어 나열을 끊어서 이를 하나의 토큰으로 보는 방식이다.

그러나 n-gram 모델은 n을 어떻게 설정하냐에 따른 한계가 있다.
(기본적으로 n을 크게 설정해야 여러 단어 정보들을 바탕으로 다음 단어를 예측하기 때문에 모델의 성능은 좋아진다.)
만약, n을 너무 크게 설정한다면, 실제 corpus(사전)에서 해당 n-gram을 카운트 할 확률이 매우 작아질 것이다.
반대로, n을 작게 설정한다면, 카운트는 잘 되겠지만, 언어모델의 성능은 낮아질 것이다.
따라서 우리는 RNN을 활용하여 이러한 문제를 해결 할 수 있다.

위 구조를 간단하게 설명해보면, 처음에 x0로는 <SOS>(Start of Sequence) 토큰을 입력으로 받는다.
그 후 <SOS> 토큰이 무수히 많은 단어 중 "This"라는 단어를 고를 확률을 구한다. 그리고 그 "This"를 다시 입력으로 받아 "movie"라는 단어가 나올 확률을 계속해서 구해간다. 위와 같은 방법을 <EOS>라는 토큰이 output으로 나올때까지 반복해 정말 작지만 분명히 존재하는 P(This movie is as impressive as a preschool Christmas play)를 구할 수 있는 것이다.

학습이 진행 될때는 Softmax를 통하면서 나온 확률 추정값(yhat)과 실제 true label인 y값의 loss를 구해 이를 최소화 하는 방식으로 가중치가 계속 업데이트된다.
이때, 역전파 과정에서 h10은 한 번, h9은 두 번(h10,h9) ,... , h1은 총 10번의 loss signal을 받는다.
1-3. Bidirectional RNN
기본적으로 RNN은 이전의 단어들을 바탕으로 다음 단어를 예측하는 형태이다.
그러나 "운동이 끝난 후 나는 ____을 마셨다." 라는 문장에서 "운동이 끝난 후 나는" 을 바탕으로 정답 레이블인 "물"을 예측 할 수도 있지만, 그 이후에 등장하는 "마셨다"라는 정보를 알 수 있다면, "물"을 더욱 더 쉽게 예측 할 수 있을 것이다.
Bidirectional RNN은 위와 같이 정답 레이블에 대한 추론(혹은 확률값 계산)을 할 때 앞의 정보 뿐만아니라 뒤의 정보도 학습 할 수 있도록 RNN 모델을 양방향으로 구현한 것이다.

위 그림과 같이 Forward states와 Backward states 각각의 상태 정보를 갖고 있는 hidden layer가 있고 이 둘은 서로 연결되어있지 않다.

각 layer에서 나온 output을 합쳐서 최종 output을 만든 후 그 output을 정답과 비교하여 loss를 계산하고 가중치를 업데이트한다.
1-4. RNN의 한계
- Vanishing gradient still exists. # 기울기 소실
- Long sequence means long backpropagation chain
- Input from a distant past forgotten # 장기의존성 문제
- ex) Jane walked into the room. John walked in too. It was late in the day. Jane said hi to ____. (John)

💡기울기 소실은 왜 특히 RNN에서 발생한다는 것일까?
RNN에서 사용하는 f함수(activation function)은 주로 tanh를 사용하는데 이러한 tanh는 output으로 (-1,1)사이의 값을 내보낸다.
RNN의 구조적 특성상 ht가 반복적으로 계산될때 계속해서 1보다 작은 값들이 곱해진다면 feed-forward 관점에서 뒤로 갈 수록 앞의 정보를 충분히 전달 할 수 없고, back-propagation의 관점에서는 gradient vanishing 문제가 발생할 수 있는 것이다.
2. LSTM
2-1. LSTM의 등장
이런 바닐라 RNN의 한계(장기의존성 문제)를 극복하기 위해 나온것이 바로 LSTM(Long Short-Term Memory)이다.
장기의존성 문제란 한 마디로 문장이 길어질 경우 앞부분에 있던 정보를 RNN의 시점이 길어질수록 보존하지 못하는 것을 의미한다.
기존의 RNN의 구조를 다시한번 살펴보자.


RNN의 문제를 해결하기 위해 LSTM에서는 hidden layer의 메모리 셀에 입력 게이트, 망각 게이트, 출력 게이트를 추가하였다.
위 그림에서는 t시점의 셀 상태인 Ct가 추가되었다고 생각하면 된다.
LSTM은 한 마디로 이 Ct 덕분에 RNN과 비교했을 때 긴 시퀀스의 입력을 처리하는데 효율적이게 된 것이다.

LSTM에서의 셀 상태는 RNN의 hidden layer과 마찬가지로 이전 output이 다음 셀의 새로운 input으로 사용된다.
ht(hidden layer)와 Ct(셀 상태)의 값을 구하기 위해 3개의 게이트가 필요한다.
이 세개의 게이트가 바로 위에서 말한 입력 게이트, 삭제(망각) 게이트, 출력 게이트다.
각 게이트는 공통적으로 Sigmoid 함수가 존재하고 이 함수를 통과하면서 나오는 0과 1 사이의 값으로 각 게이트들을 조절하는 것이다. (-> Sigmoid가 여러번 등장하는 이유 : 각 게이트의 가중치로서 역할)
그렇다면 이제 LSTM의 Ct가 구체적으로 어떤식으로 초기 입력의 정보를 저장하는지 살펴보자.
(이하 식에서 σ는 시그모이드 함수를 의미한다.)
(Wxi, Wxg, Wxf, Wxo 는 xt와, Whi, Whg, Whf, Who는 ht-1과 함께 사용되는 가중치를 의미한다.)
2-2. LSTM의 삭제 게이트
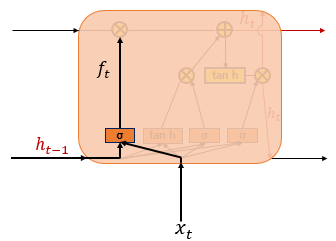
LSTM의 첫 단계는 삭제(망각) 게이트로 이전 hidden layer(ht-1)의 정보를 얼마나 삭제할 지 결정하는 게이트다.

셀 상태의 수식은 다음과 같은데, 시그모이드 함수를 통과해 0과 1사이의 값을 리턴하고, 그 값이 0에 가까울수록 정보를 많이 삭제하고, 1에 가까울수록 정보를 온전히 기억한다.
2-3. LSTM의 입력 게이트


입력 게이트는 현재 정보를 기억하기 위한 게이트다.
입력 게이트에서는 it(얼마나 중요한지)와 gt(실제 정보)라는 두개의 값이 계산되는데,
it는 xt(현재 시점(t시점)의 x값)와 Wxi(가중치)의 곱 + ht-1(이전 시점의 h값)와 Whi(가중치)의 곱 + bias를 σ 함수에 넣어서 계산한다.
gt는 Wxg(가중치)와 xt 값 + Whg와 ht-1의 곱 + bias를 tanh 함수에 넣어 계산한다.
RNN이나 LSTM에서 셀 상태를 계산할 때 활성화 함수로 tanh(-1~1)를 사용하면 실제 정보라고,
σ(시그모이드,0~1)를 사용하면 그 정보가 얼마나 중요한지(얼마나 기억할지)라고 생각하면 편하다.
2-4. LSTM의 셀 상태

삭제게이트와 입력게이트에서 만들어진 ft(중요도),Ct-1(과거의 정보)와 it(중요도),gt(현재의 정보)는 각각 원소별 곱을 통해 Ct(현재 셀 상태 정보)를 구하는데 사용된다.
즉, 과거 정보(Ct-1)는 삭제 게이트에서 계산한 만큼(ft) 지우고, 현재 정보(gt)는 입력 게이트에서 계산한 만큼(it)

2-5. LSTM의 출력 게이트와 은닉 상태


출력 게이트에서는 Ot를 계산해주는데, 이는 현 시점의 은닉층(ht)로 출력할 양을 결정하는 것이다.
이때도 역시 xt와 ht-1을 사용하는데 LSTM의 삭제, 입력, 출력게이트 모두에서 xt와 ht-1 그리고 bias까지 항상 이렇게 세가지를 기본적으로 이용한다.
hidden state(은닉 상태)는 출력 게이트의 output인 Ot와 현재의 셀 상태 Ct에 tanh를 통과시킨 값을 곱해서 계산된다.
이는 output으로 나감과 동시에 다음 state의 input으로 들어간다.
3. GRU
GRU는 LSTM의 장점인 장기 의존성 문제 해결책은 살리면서, hidden state를 업데이트하는 연산을 줄여 그 구조를 훨씬 단순화시켰다.


LSTM에서는 출력, 입력, 삭제 게이트 이렇게 총 3개의 게이트가 있었다.
GRU는 리셋 게이트, 업데이트 게이트 이렇게 2개의 게이트만이 존재한다.
3-1. GRU의 리셋 게이트
GRU의 리셋 게이트(Reset gate)는 이전 정보들을 적당히 리셋 시키는 것이 목적으로 activation function으로는 simoid함수를 사용해서 구현한다.
이렇게 생성된 rt는 이전 hidden state의 값(ht-1)을 얼마나 활용할 것인지(얼마나 리셋 할지)에 대한 정보로 이해하면 된다.
(rt는 gt를 구할때 다시 사용된다.)
3-2. GRU의 업데이트 게이트
업데이트 게이트(Update gate)는 이전, 현재 정보를 각각 얼마만큼 반영할지 비율을 구하는 역할(zt)을 한다.
(LSTM의 input, forget gate와 비슷한 역할을 한다.)
gt를 구할때는 이전 정보인 ht-1를 그대로 사용하지 않고 리셋 게이트에서 구한 rt를 곱하여 이용한다.
(이때 gt는 hidden layer의 중간 단계(후보군) 정도로 생각하면 된다.)
위 식에서 구한 zt는 과거 정보를 얼만큼 사용할지에 대한 비율이고, (1-zt)는 현재 정보에 대한 비율을 나타낸다.
ht를 구할때는 이 두 비율을 각각의 과거,현재정보에 해당하는 ht-1와 gt에 곱해 최종적인 ht를 계산한다.
(http://colah.github.io/posts/2015-08-Understanding-LSTMs/)
(위 링크에는 zt가 현재 정보의 사용 비율로 기술되어 있는데 어차피 zt라는 하나의 weigth를 1-zt와 zt로 나눠서 해석하는 것이므로 딱히 상관 없다.)
4. 결론
RNN은 LSTM이나 GRU에 비해서는 단점이 분명 존재하고 성능이 안좋다고 하지만, 그 구조가 거의 비슷하니 우선 모델을 만들어보면서 판단하는게 가장 좋은 것 같다.
GRU는 LSTM과 비교했을때 구조상의 큰 차이는 없다. 분석 결과 역시 큰 차이가 없는데, 학습 시키려는 데이터 혹은 그 목적에 따라 LSTM, GRU 둘 다 사용해서 비교해 보고 더 좋은 모델을 사용하면 될 것이다.
'AI Theory > NLP' 카테고리의 다른 글
| [NLP] 최대한 쉽게 설명한 Transformer (0) | 2022.05.17 |
|---|

댓글