목차
1. Self-Attention

예를 들어, Thinking과 Machines에 대한 Self-Attention을 계산한다고 해보자.
우선 Thinking의 embedding vector이 1x4 matrix라고 하면, 4x3 matrix인 Wq를 곱해 Thinking에 대한 Query값(1x3 matrix)을 얻을 수 있다. 이때, Machines 역시 같은 weight matrix(Wq)와 곱해져서 해당 단어들에 대한 query값을 모두 구할 수 있다.
그 후 Thinking에 대한 Attention만 먼저 살펴보면, Thinking에 대해 구한 query값(q1)은 고정으로 사용하고, 나머지 단어들에 대한 key값(k1,k2, ... )들과 내적(·)해서 Attention Score를 구한다.
아래 그림에서 q1·k1 = 112, q1·k2 = 96이라고 되어있는 것 처럼, Thinking과 Thinking의 Attention Score는 112, Thinking과 Machines의 Attention Score는 96이다.
이렇게 구한 Attention Score를 확률값으로 나타내기 위해 Softmax함수를 사용하는데, 그 전에 sqrt(dk)로 나눠줘서 정규화를 먼저 해준다. 이때 dk는 key vector의 크기를 나타낸다. (일반적으로 query, key, value 벡터의 크기는 모두 동일하다.)
정규화를 해주는 이유에 대해 생각해보면, 위에서 구한 Attention score는 query(key) vector의 크기가 커지면 점수도 커질 것이다.
"Thinking"에 대한 attention 확률을 다 구했으면, 그 다음 단어("Machines")에 대해서도 계속 진행해준다.
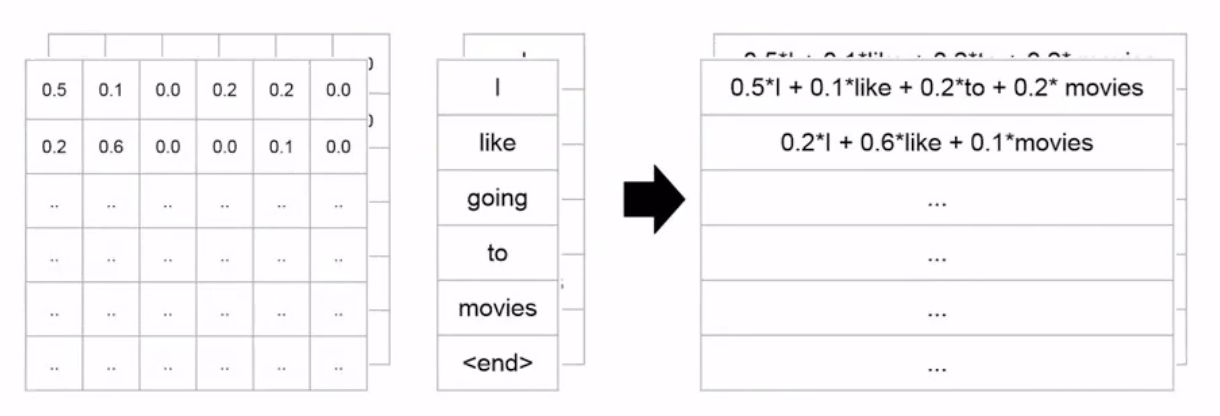
이렇게 구한 확률은 각각의 value와 곱해서 최종 결과인 z1을 구하는데, z1 = 0.88 * v1 + 0.12 * v2 로서 구할 수 있다. (z2도 마찬가지)
핵심은, 두개의 input(Thinking, Machines)이 들어오면 두 개의 output(z1,z2)이 나와야 한다는 것이다.
(당연히 output(z 벡터)의 크기 역시 query,key,value 벡터와 크기가 동일하다.)
위 과정을 모든 단어에 대해 반복해서 진행하는데, 이러면 for문을 활용하여 동일한 연산을 계속 반복 수행해야한다.
아래 그림은 Thinking과 Machines 벡터를 concat해서(열로 합침) 한번에 계산하는 과정을 나타낸다.
기존의 RNN은 input을 넣고 hidden state가 업데이트 되면 다음 input을 넣고 이런 과정이였는데, 이런 메커니즘은 병렬처리가 불가능하다. 그러나 transformer의 아래와 같은 방식은 반복문을 사용하지 않고 한번에 모든 단어들의 attention score를 구할 수 있다는 점에서 의의가 있다.
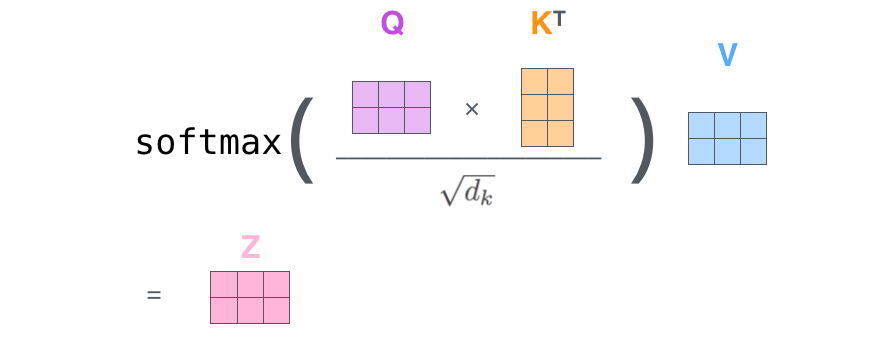
1-1. Multi-head Attention
Multi-head Attention은 두 개(혹은 그 이상의) Attention map을 사용하는 것이다.
이렇게 하는 이유는, 하나의 attention map만 사용하는 것 보다 여러개를 사용하면 더 다양한(예상치 못한) 특징을 뽑아 낼 수 있기 때문이다.
이때, 여러개의 Attention map이 모두 다른 가중치를 갖는다는 보장은 없다. 단지 한 번 사용하는 것 보다 두 번 사용하면, 미처 학습하지 못했던 특징들이 있을 수 있기 때문에 일반적으로 여러개의 map을 사용하면 좋은 것이다.
map(head)을 한 개 이용하는 것 보단 두 개 이용하는 것이 성능이 좋을 것이다. 그러나 16개에 비해 32개 사용했을때 성능이 엄청나게 좋아지진 않는다. (어차피 모든 attention map들은 test performace를 maximize 하는쪽으로 학습된다.)
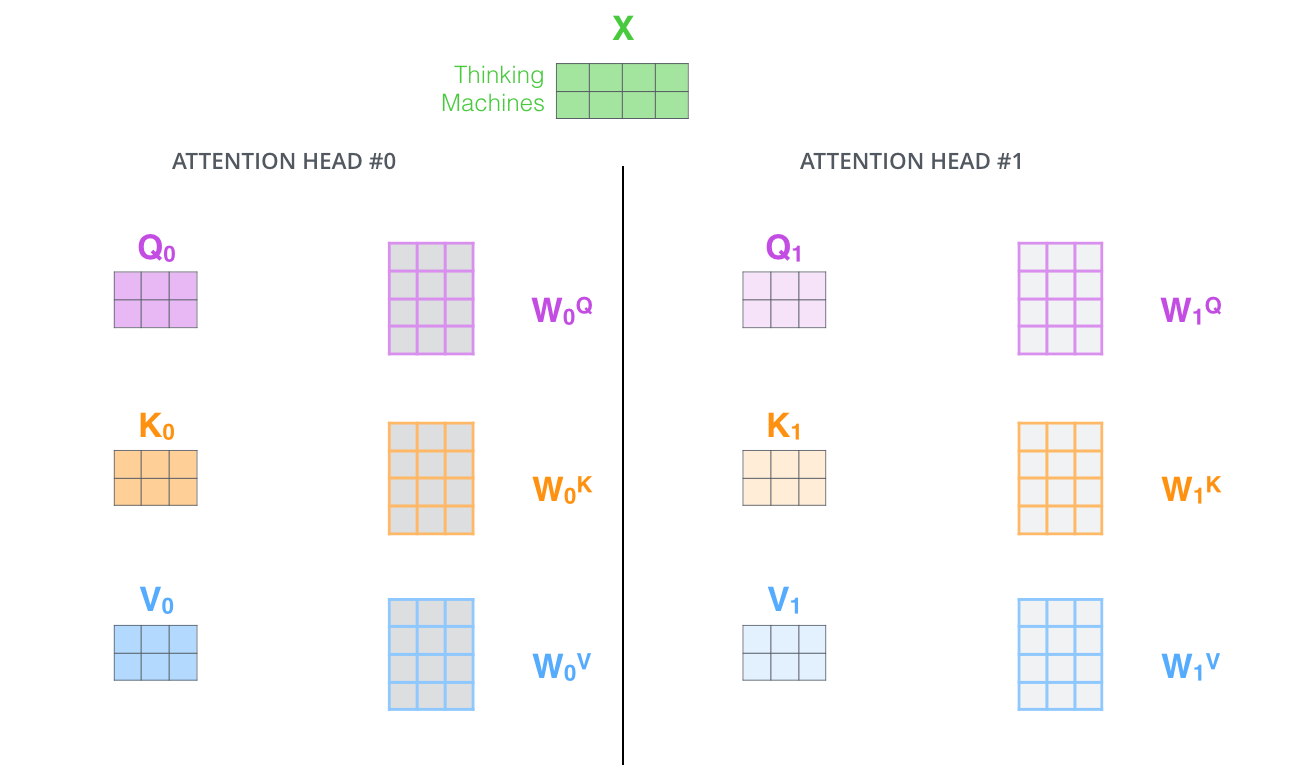
input인 x값은 동일하지만(단순 복사), W0q, W1q, W2q 등은 각각 다 다른 가중치를 갖고 이는 서로 다른 q1, q2, q3 ,.. 를 생성한다.
논문(Attention is all you need)에서는 총 8개의 Attention head를 사용한다.
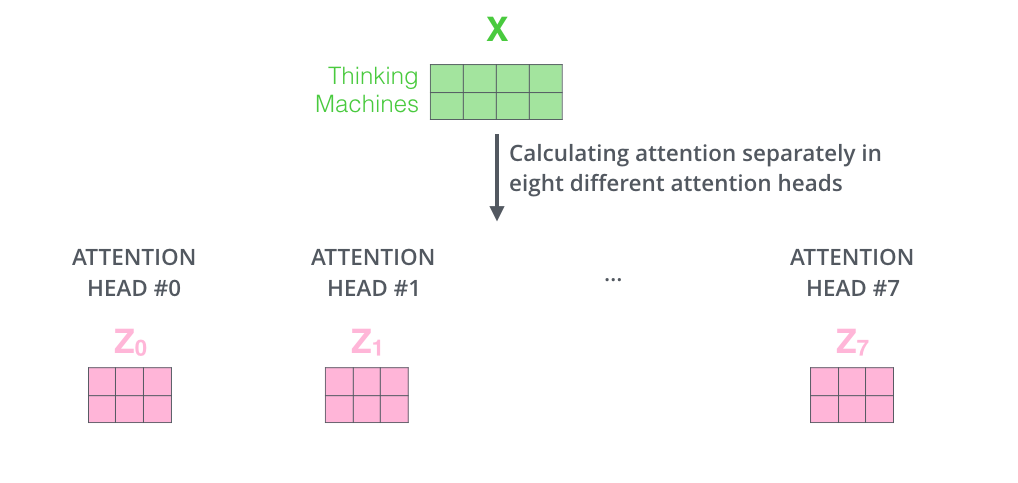
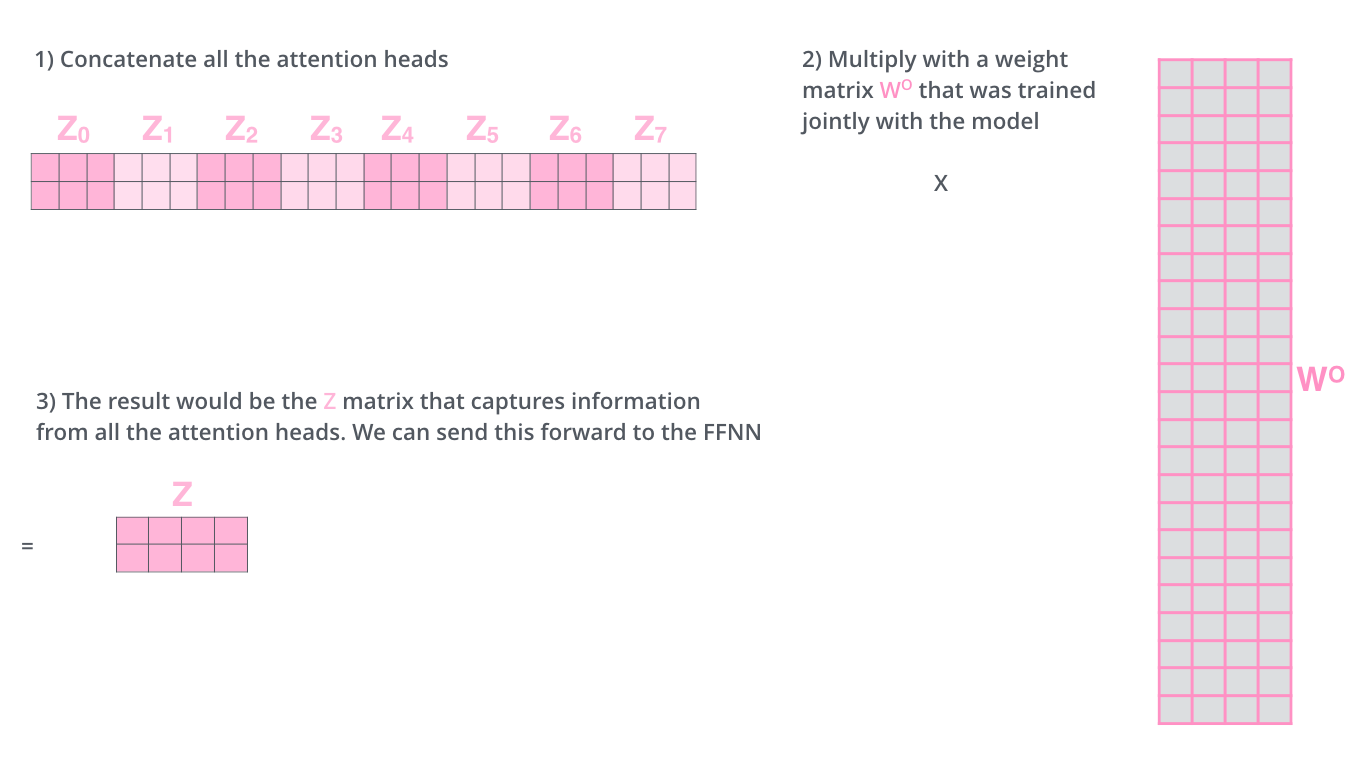
Multi-head attention을 통해 생성된 Z0 ~ Z7(head가 8개이므로 Z7까지)은 아래와 같이 행 끼리 concat된 후 다시 한번 새로운 가중치 벡터(W0)와 곱해져서 최종적인 output Z matrix를 만들어 낸다.
이때 아래 예시에서 가중치 벡터(W0)의 크기는 24x4인데 Z0~Z7까지 모두 concat 하면 2x24이 나오고, 맨 처음 input으로 들어온 Thinking과 Machines의 벡터가 4x2의 크기를 가지므로 이와 동일한 output을 만들어 내려면 24x4여야한다.
Self-Attention의 전체적인 흐름을 보면 아래와 같다.
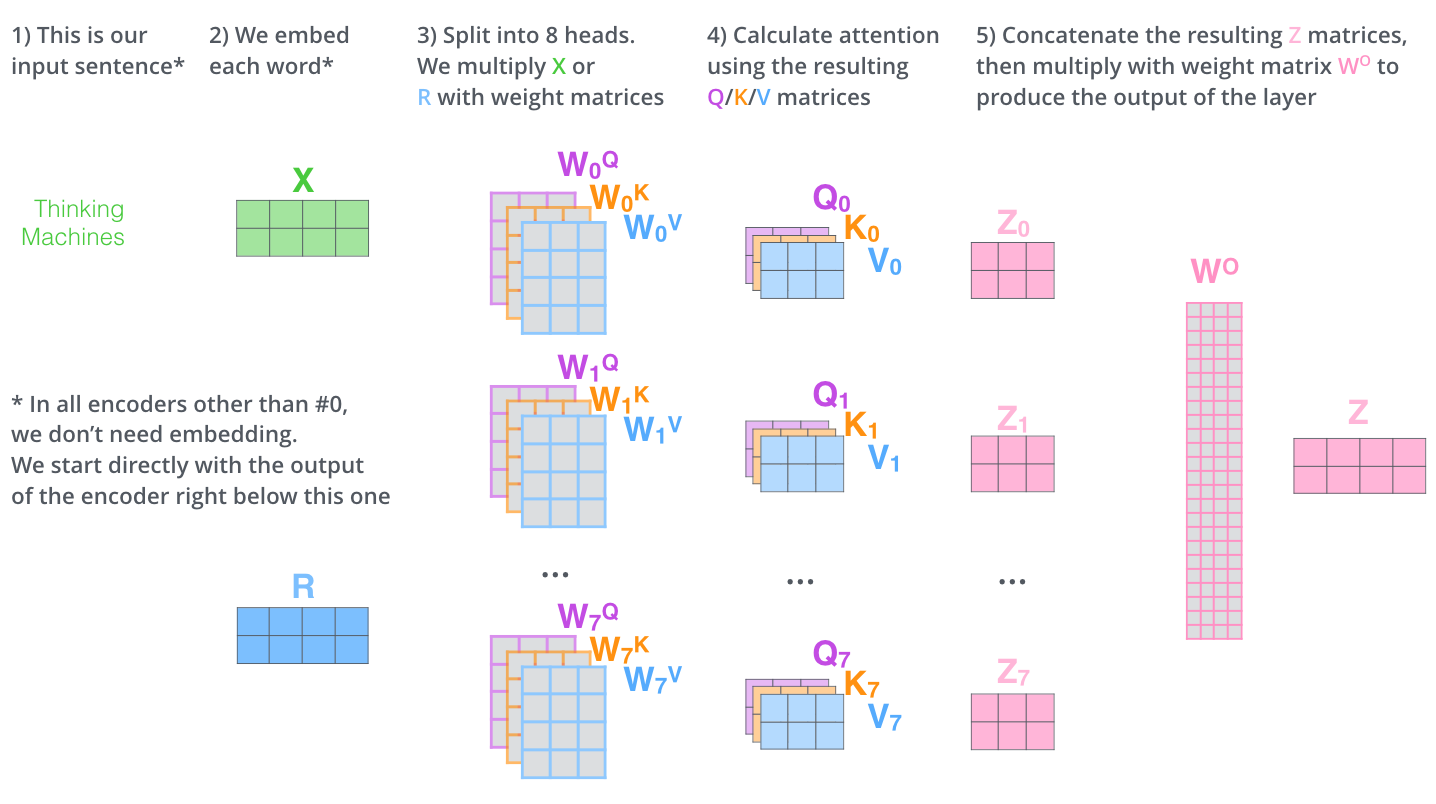
위 그림에서 벡터 R이 의미하는것은 첫번째 encoder를 제외한 나머지 7개의 encoder의 input을 의미한다. (또 다시 임베딩 벡터를 input으로 넣어 줄 이유가 없다.)
즉, Z0는 그 다음 encoder의 input인 R로서 들어가고, Z1을 output으로 return하고 Z1이 다시 R로서 들어가고 Z2 리턴하고 .. 이런 형태인 것이다.
이러한 과정이 가능한 이유는 encoder의 Input과 output의 size가 동일하기 때문이다.
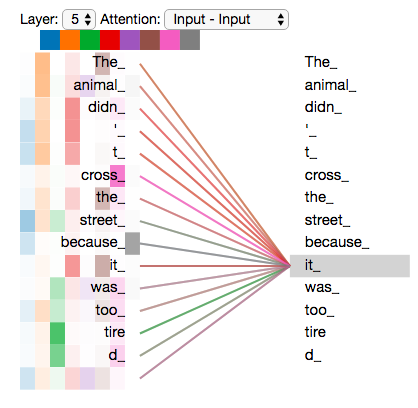
Attention map 개수에 따른 attention 과정을 시각화 해보면 다음과 같다.


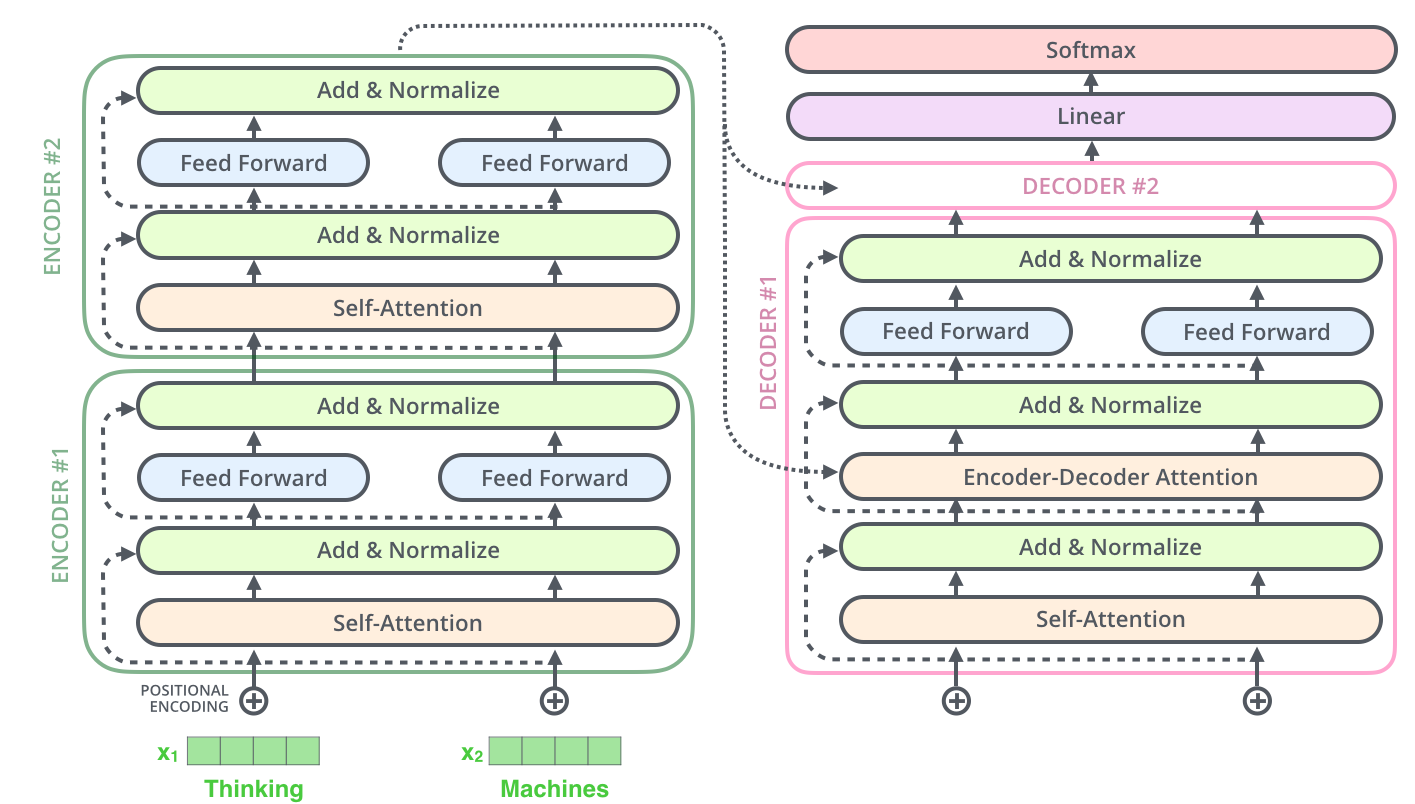
2. Encoder
트랜스포머(Transformer)는 원래 기계번역을 위해 설계된 아키텍쳐이다.

transformer는 아래와 같이 encoder와 decoder로 나뉜다.
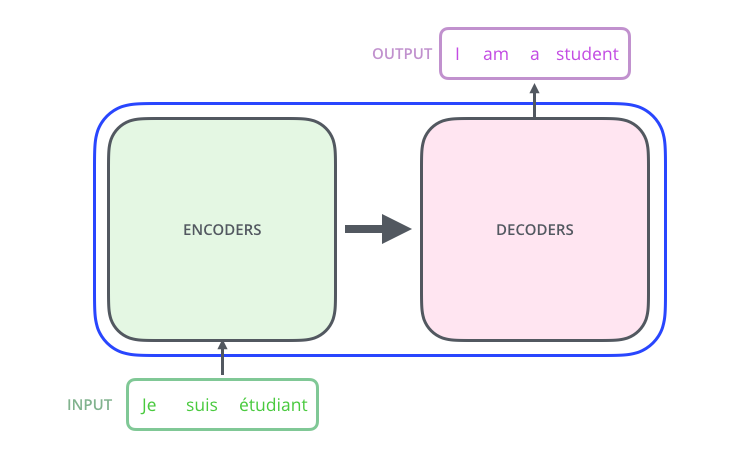
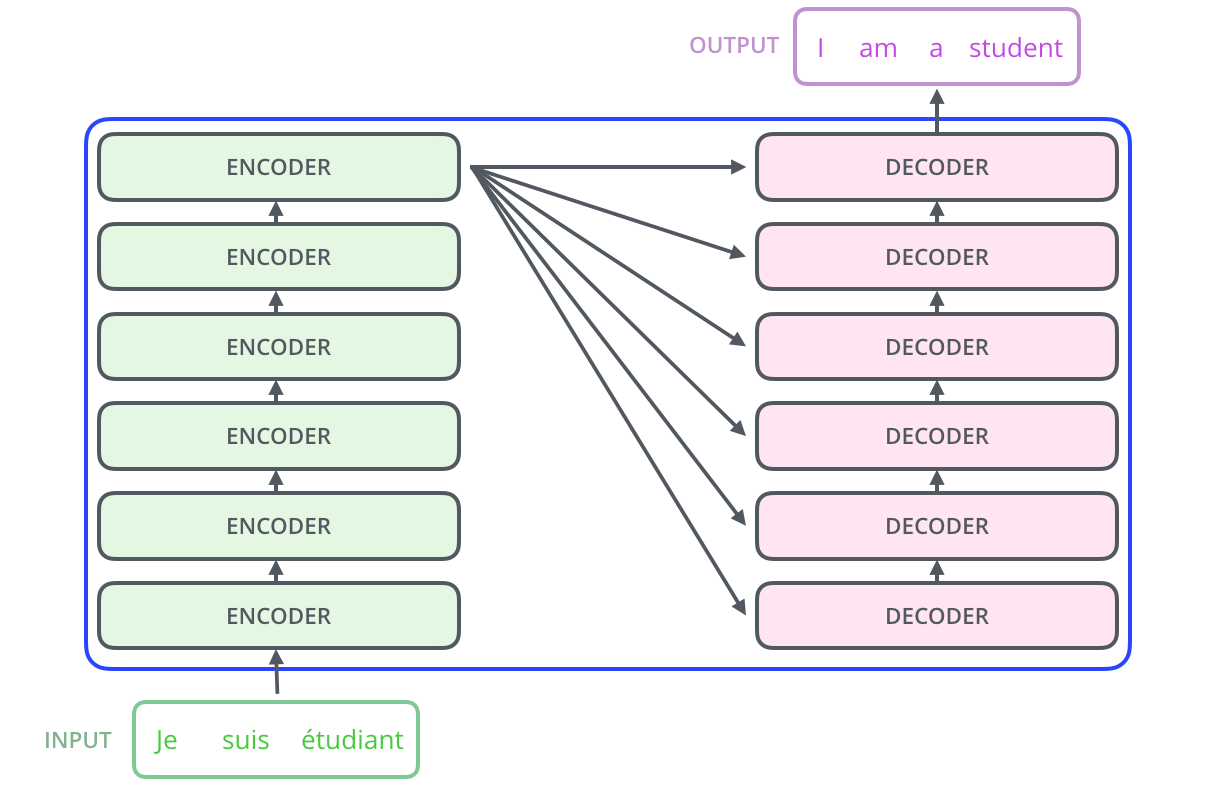
논문에서는 Encoder과 Decoder를 각각 6개씩 사용하는데 이것이 가능한 이유는 위에서 언급했듯이 encoder의 input과 output의 크기가 같기 때문이다.
우선의 Transformer의 Encoder 부분부터 자세히 살펴보자.
6개의 Encoder는 모두 같은 구조를 갖고 있으므로, 하나의 구조만 자세히 살펴봐보자.
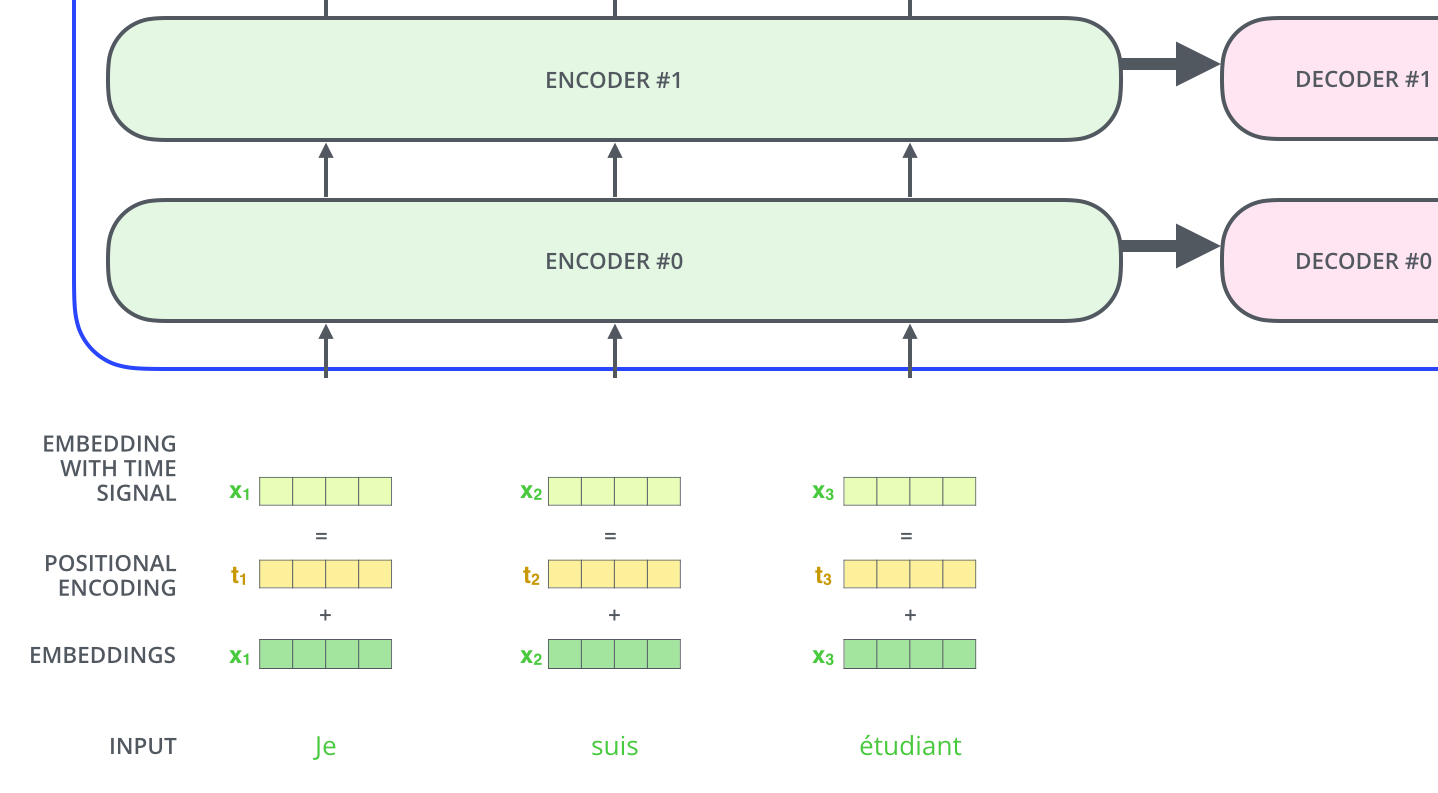
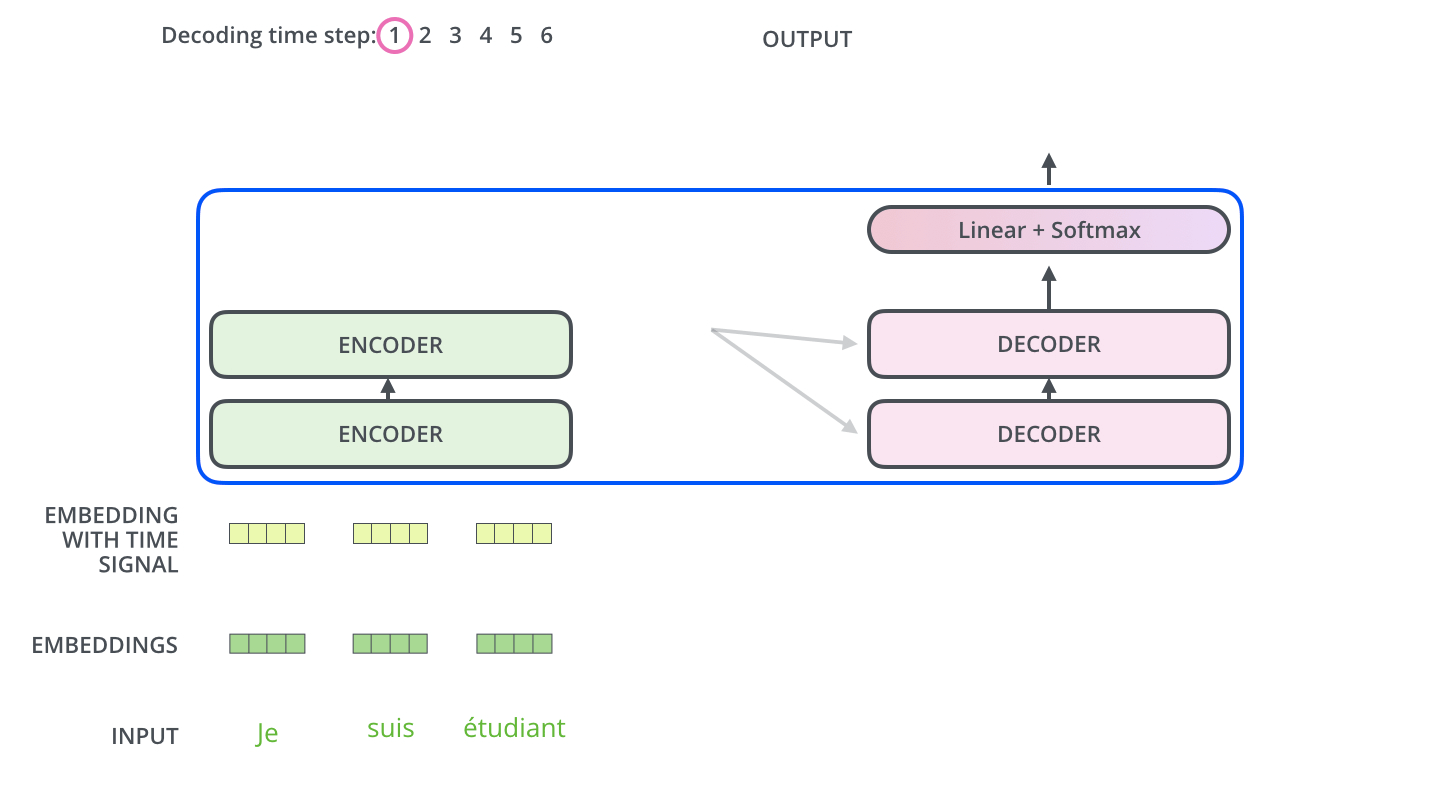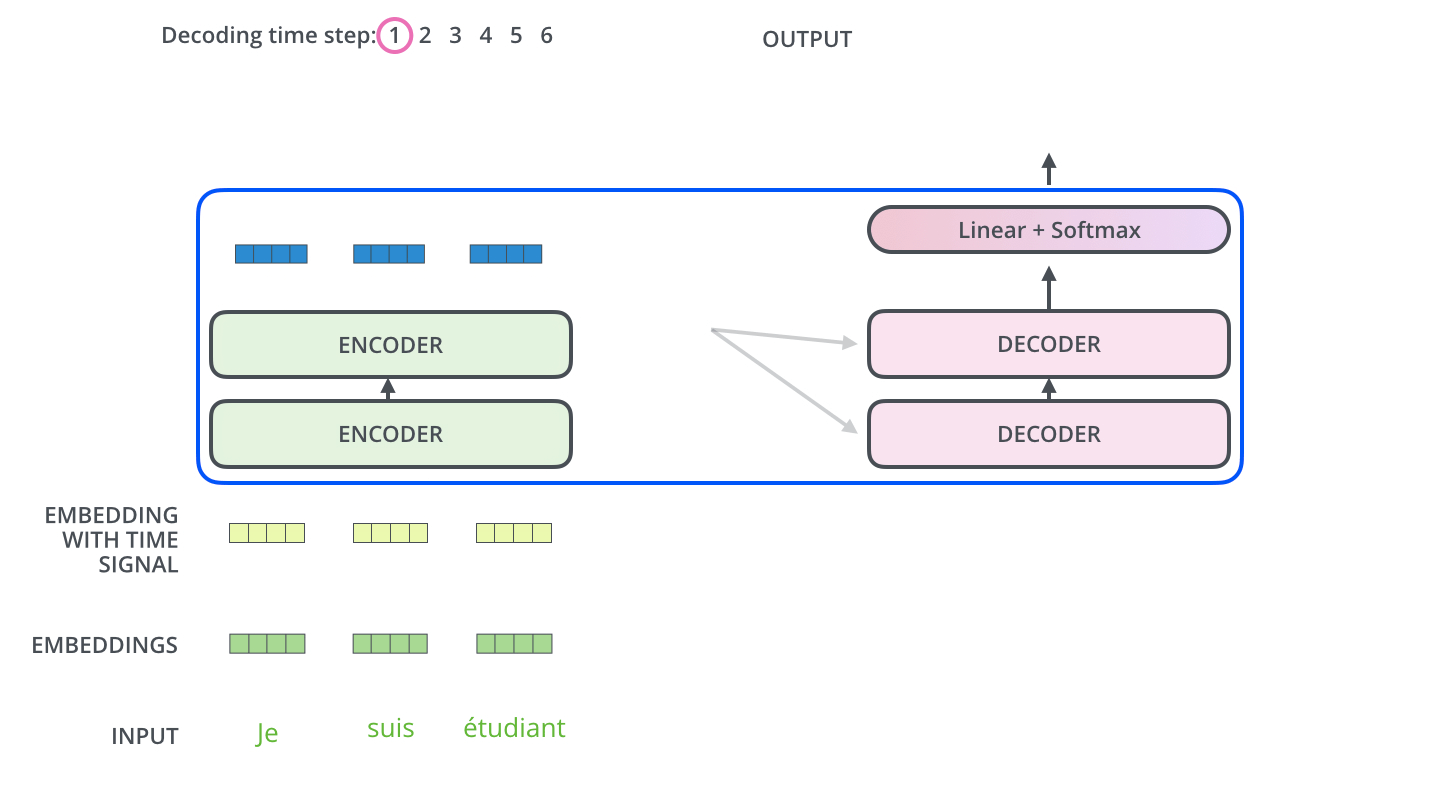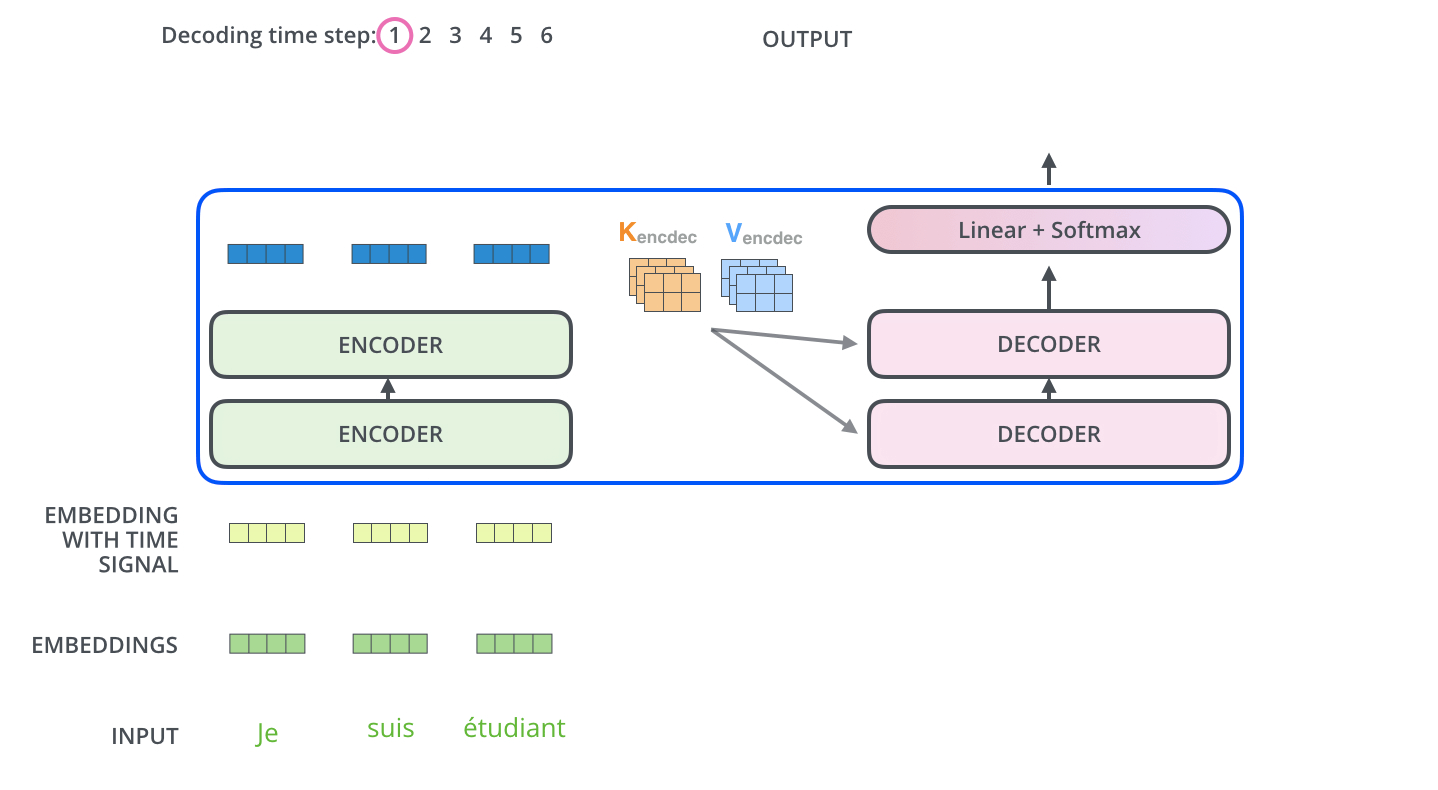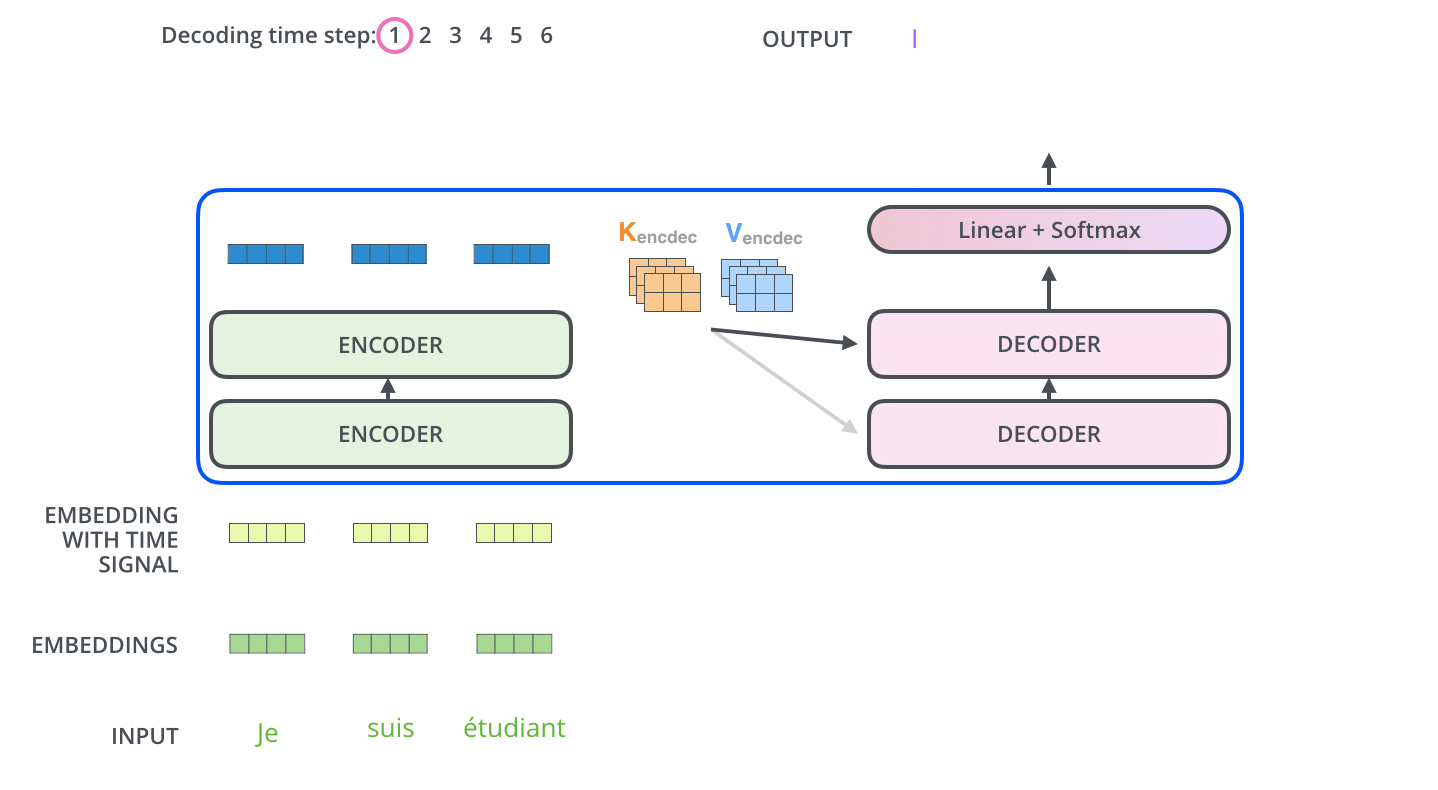
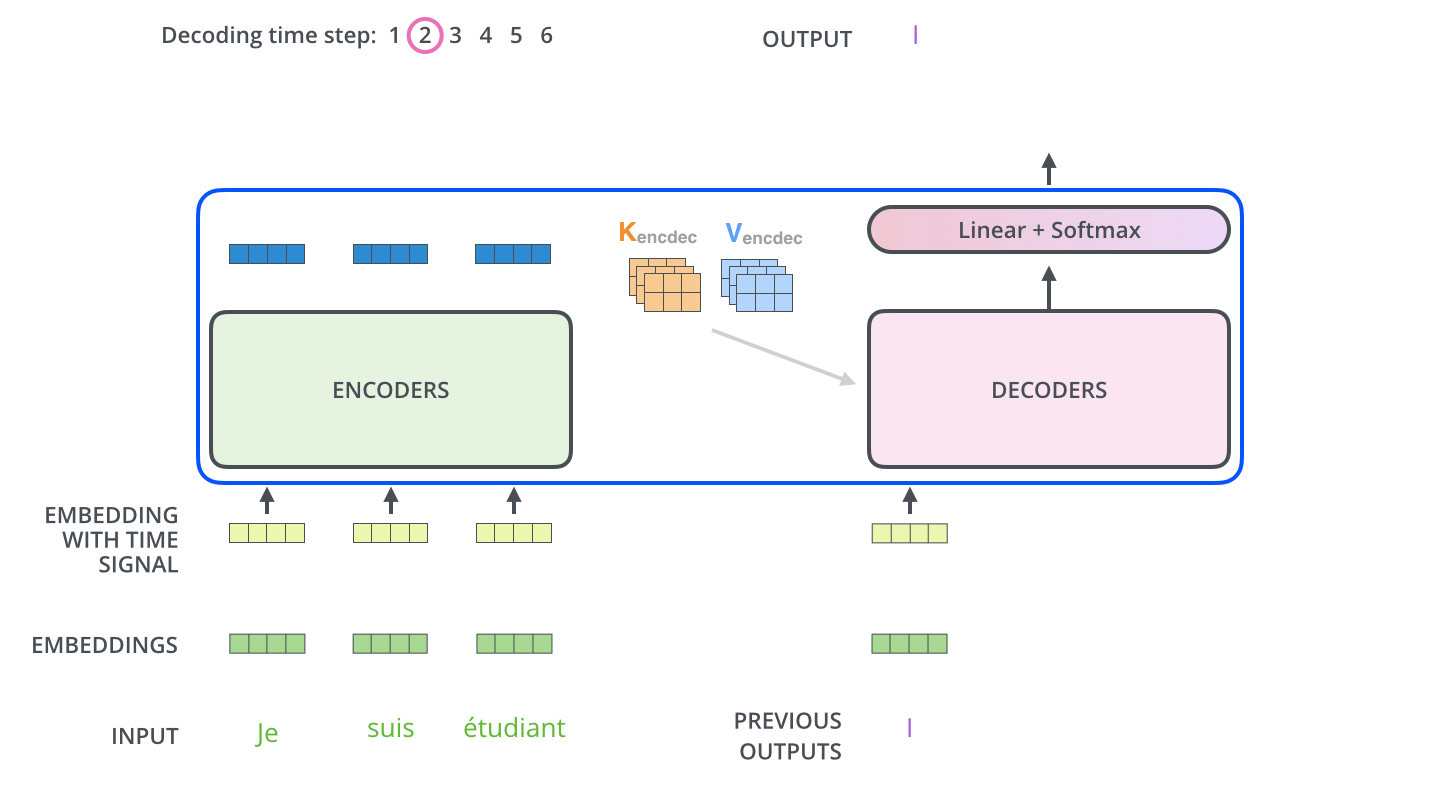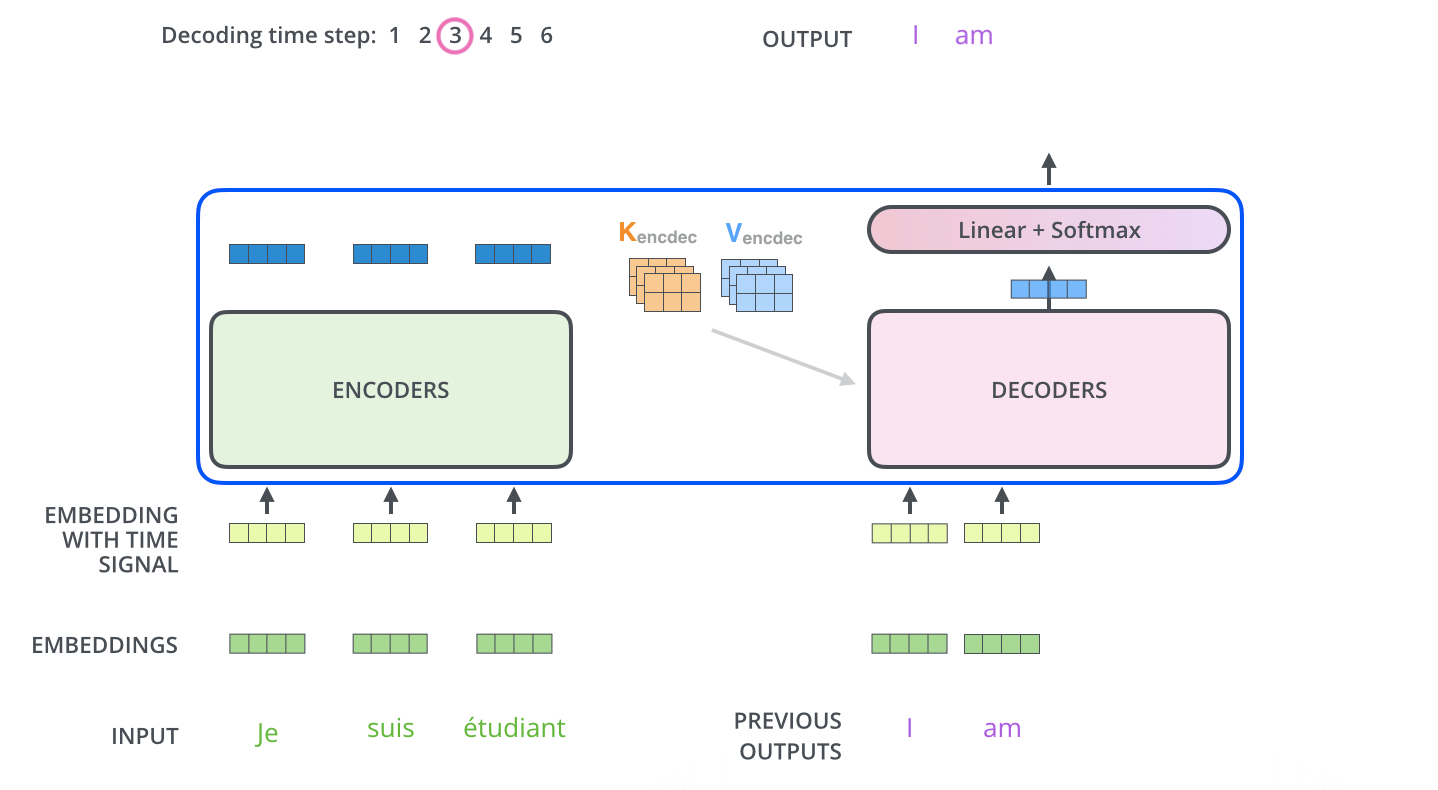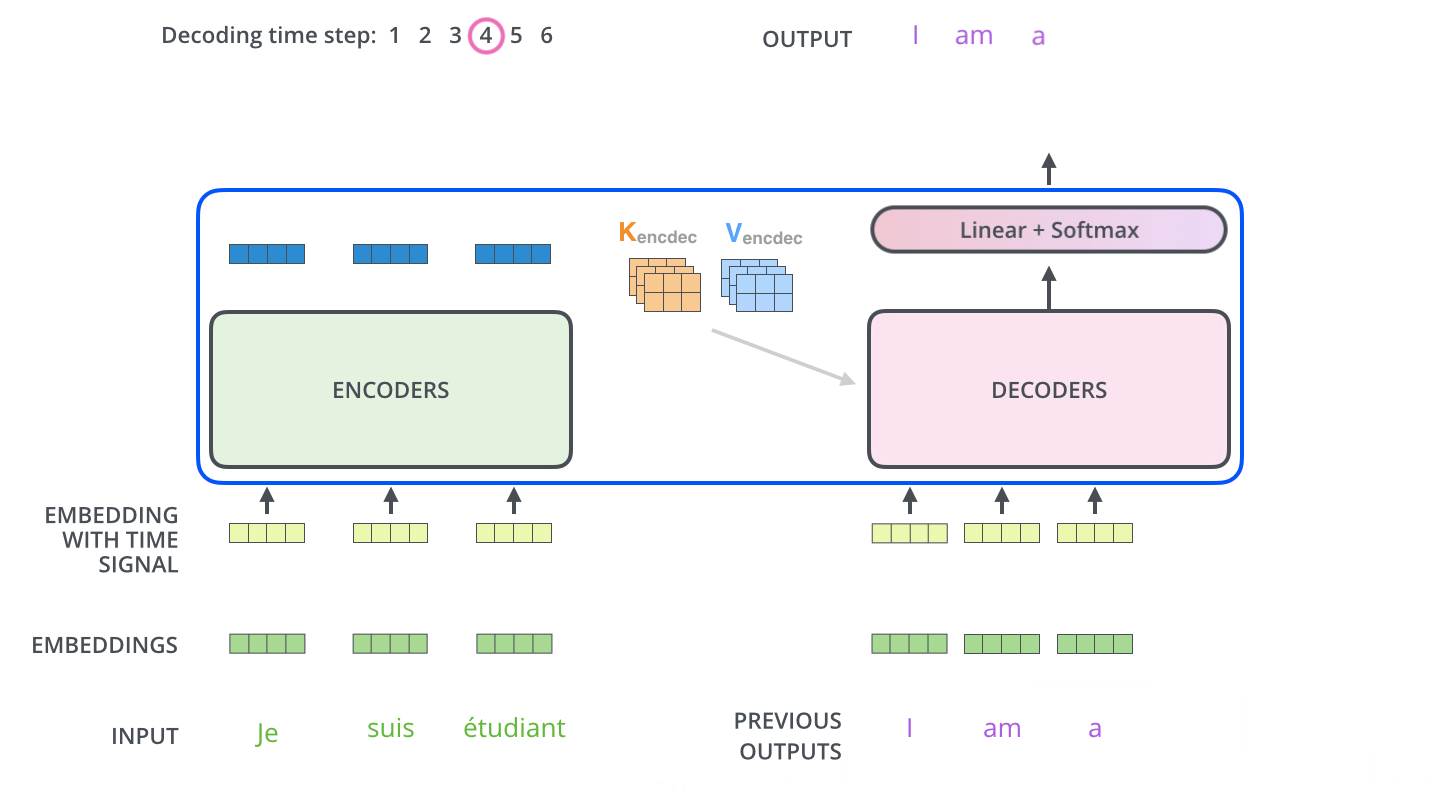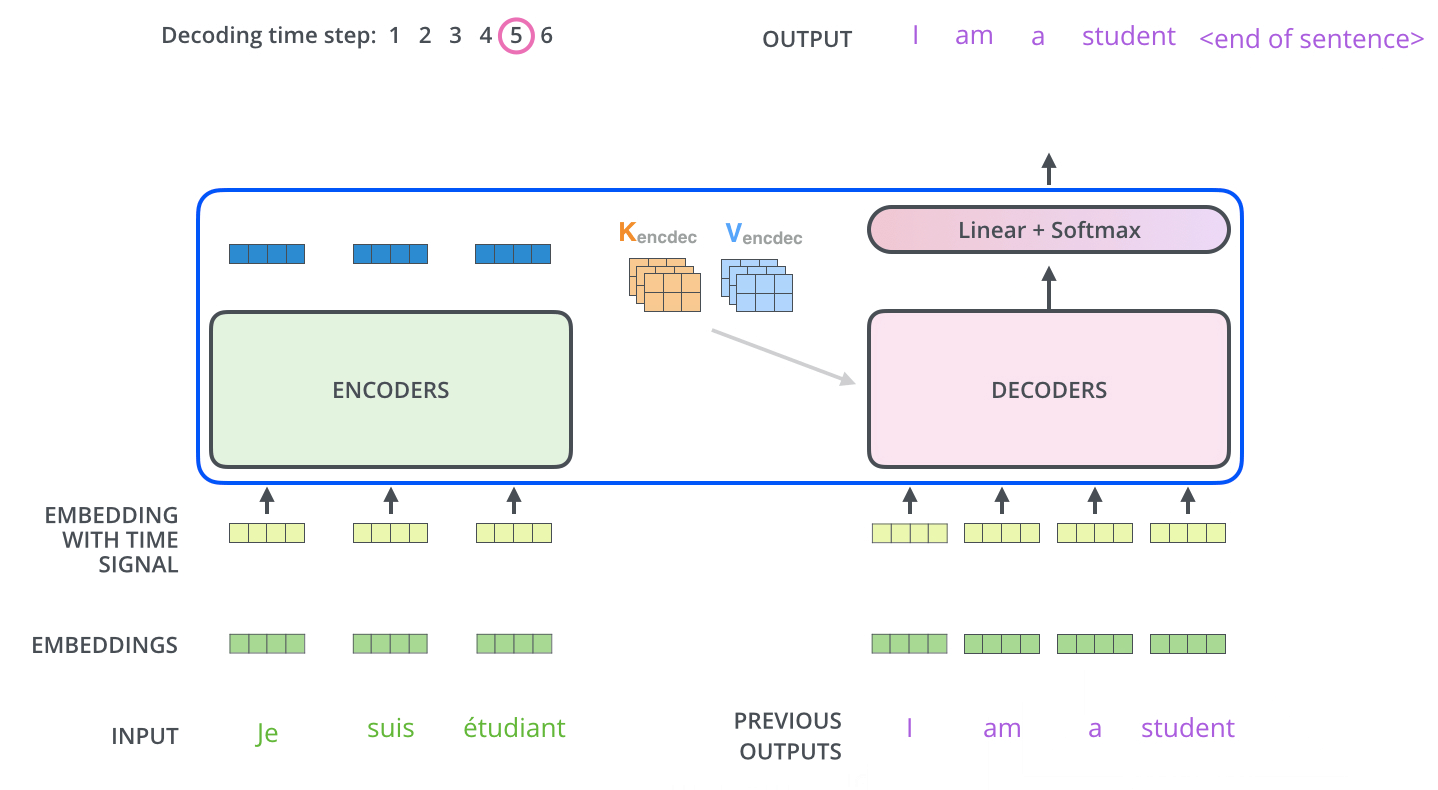
아래 그림과 같이 input으로 3개의 French 단어(Je suis etudiant)가 들어온다고 해보자.
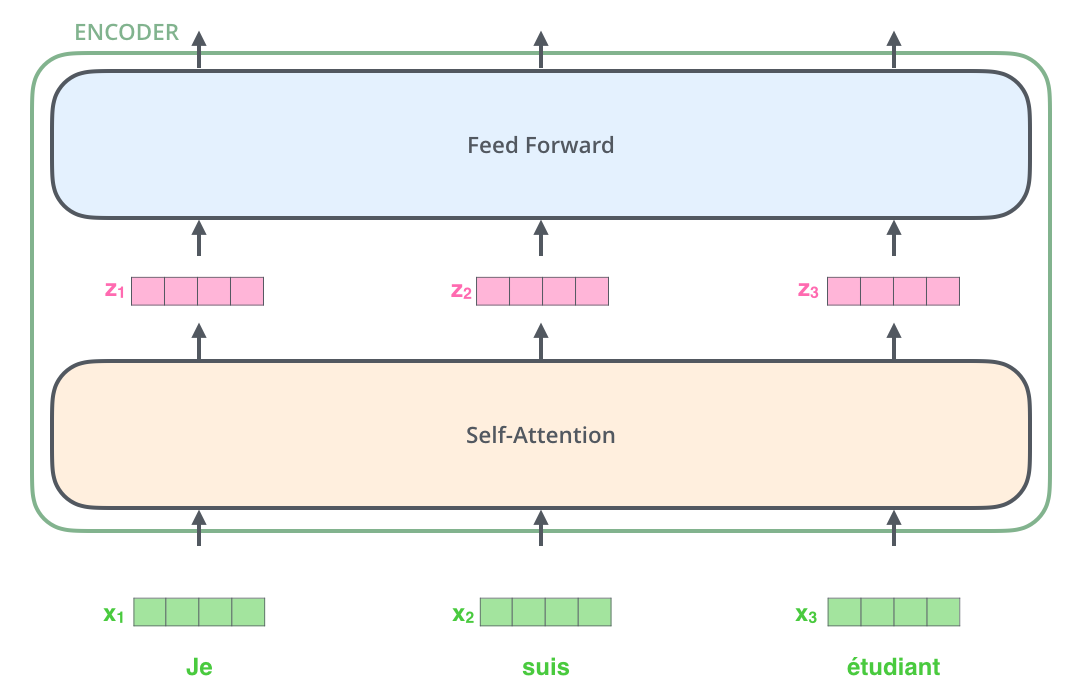
우선 input으로 들어온 3개의 단어는 Self-Attention 과정을 통해 각각 z1,z2,z3 벡터가 된다. 이는 z벡터들은 Feed Forward Network(MLP)를 거치면서 최종적인 encoder의 output이 되는데, 이때 각각의 z벡터들이 서로 다른 Feed Forward Network를 통과하는 것이 아닌 단 하나의 동일한 Feed Forward Network를 통과한다.
결과적으로 3개의 input이 들어왔으므로 3개의 output이 나오는 형태가 될 것이다.
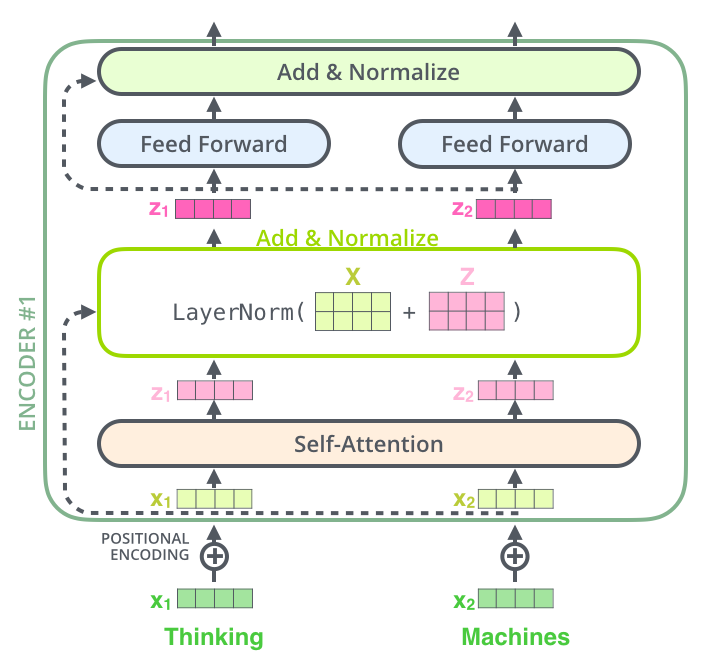
조금 더 구체적으로 보면, Self-Attention 과정이 끝난 후 나온 z벡터는 바로 Forward Network(MLP)를 통과하는 것이 아닌 Add & Normalize 과정을 거치게 된다.
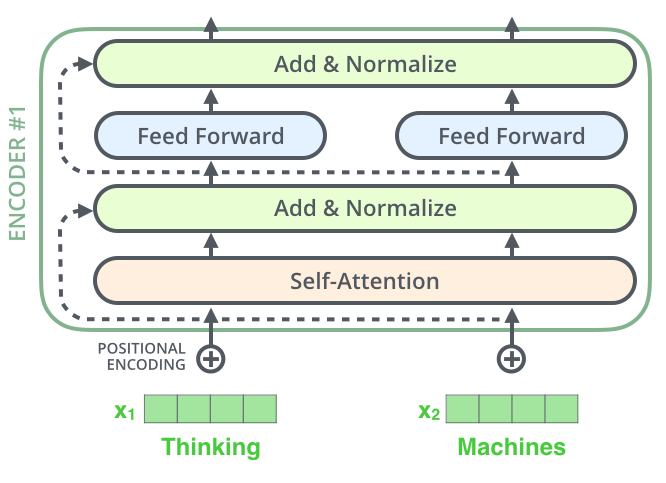
Add 과정은 input과 output을 residual connection으로 연결하는데, 이는 ResNet에서 skip connection으로 연결되는 것과 같은 구조이다.
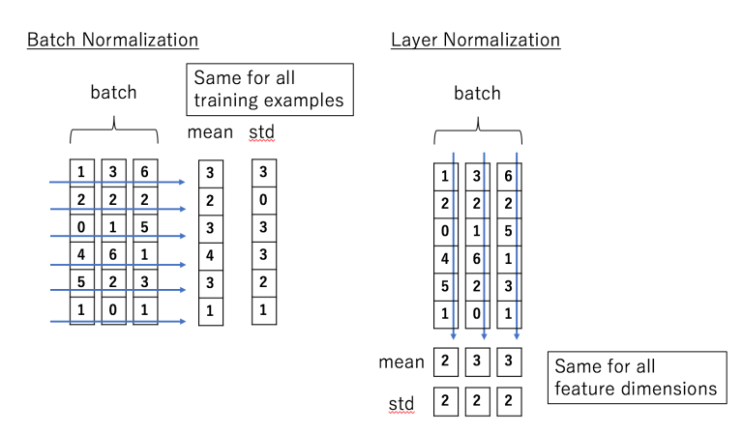
Normalize 과정은 LayerNorm을 통해 진행되는데, LayerNorm은 BatchNorm과 비교해보자.
3. Decoder
3-1. Positional Encoding
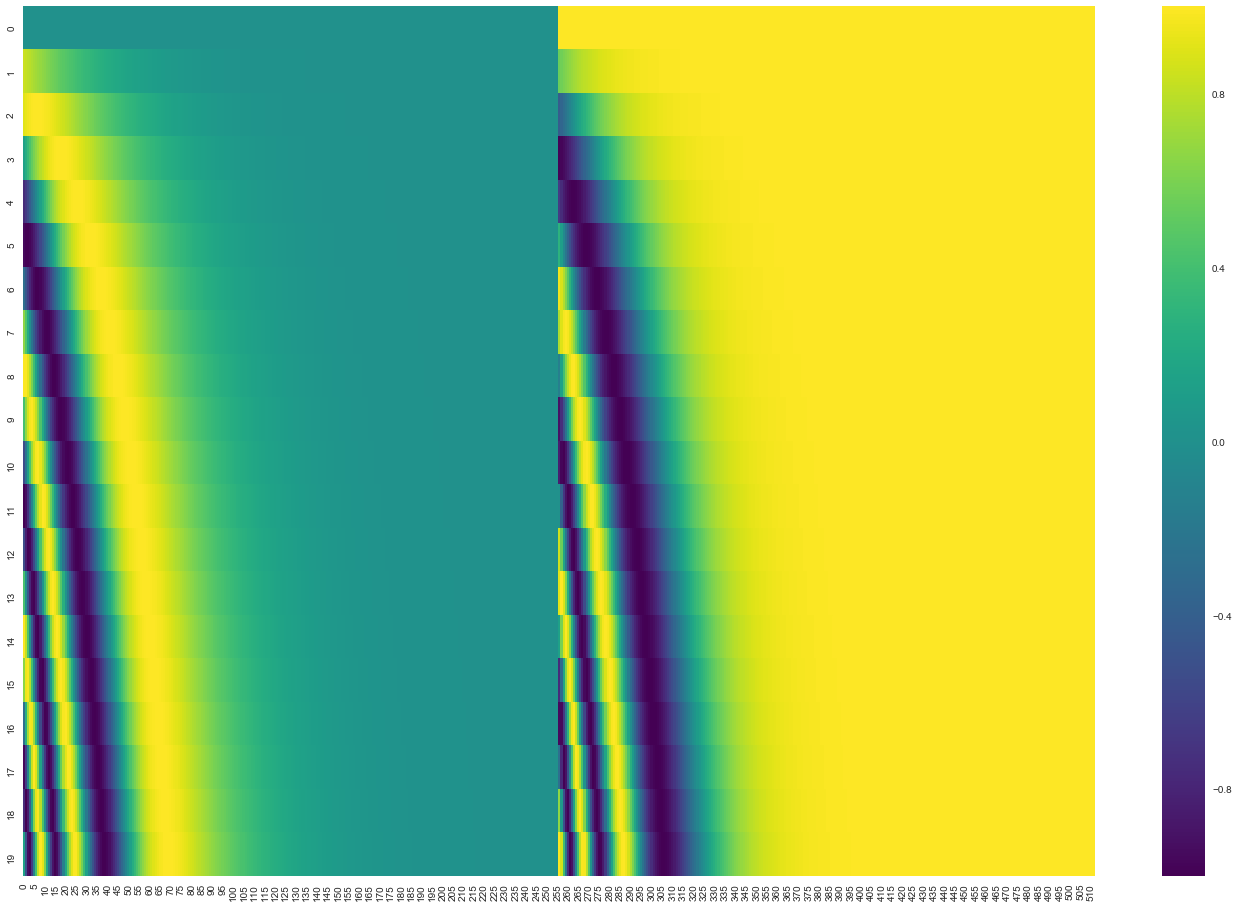
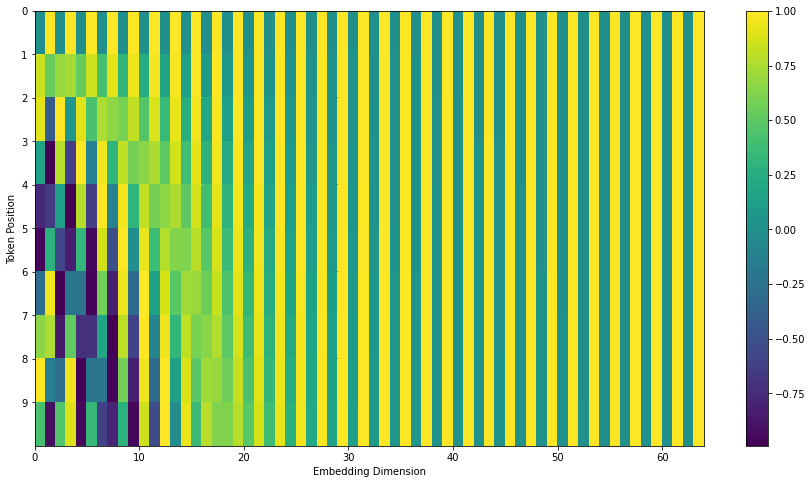
Transformer의 가장 중요한 특징 중 하나는 positional encoding을 통해 input의 위치 정보를 나타낸 다는 것이다.
RNN 계열의 모델들은 반복적으로 sequence가 input으로 들어오는 반면, Transformer는 모든 단어들이 input으로 한번에(세트로서) 들어온다.
따라서 이것의 순서정보를 고려해주는 positional encoding 방법을 통해 입력 시퀀스들의 순서정보를 반영할 수 있다.
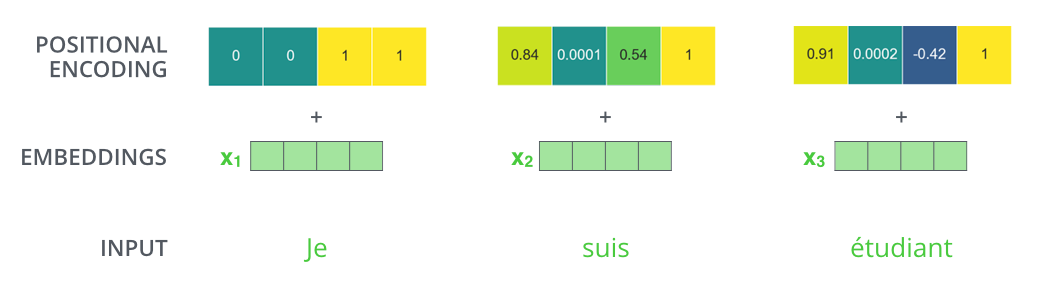
아래 사진에서 볼 수 있듯, 단순이 입력 단어의 임베딩 벡터를 encoder의 Input으로 넣어주는 것이 아닌, positional encoding을 추가하여 embedding with time signal 벡터를 최종적인 input으로 사용하는 것이다.
그렇다면 Positional Encoding은 어떤 방식으로 진행될까?
Positional Encoding은 아래 4가지의 조건을 만족해야한다.
- 각 time-step(문장에서 단어의 위치)에 대해 고유한 인코딩을 출력해야 합니다.
- 일정 time-step 사이의 거리는 길이가 다른 문장끼리 일정해야 한다.
- test data에서 train data에서보다 더 긴 시퀀스가 들어왔을때도 처리할 수 있어야 한다. (더 긴 문장도 일반화가 가능해야함)
- 상한(Upper bound)이 필요하다.
- 정확하게 위치를 결정할 수 있어야한다.(확률값 X)
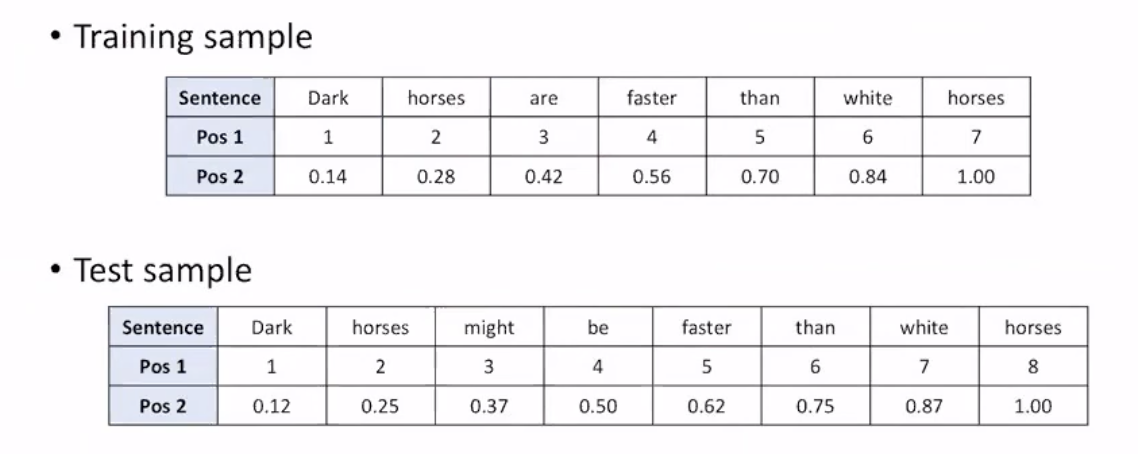
그렇다면 위와 같은 positional encoding을 사용하면 어떨까?
우선 Pos 1은 위의 조건 3을 만족하지 않는다.
Pos 2는 조건 2를 만족하지 않는다. training sample의 거리는 (time-step 1일때) 0.14인 반면, test sample의 거리는 0.13이다.
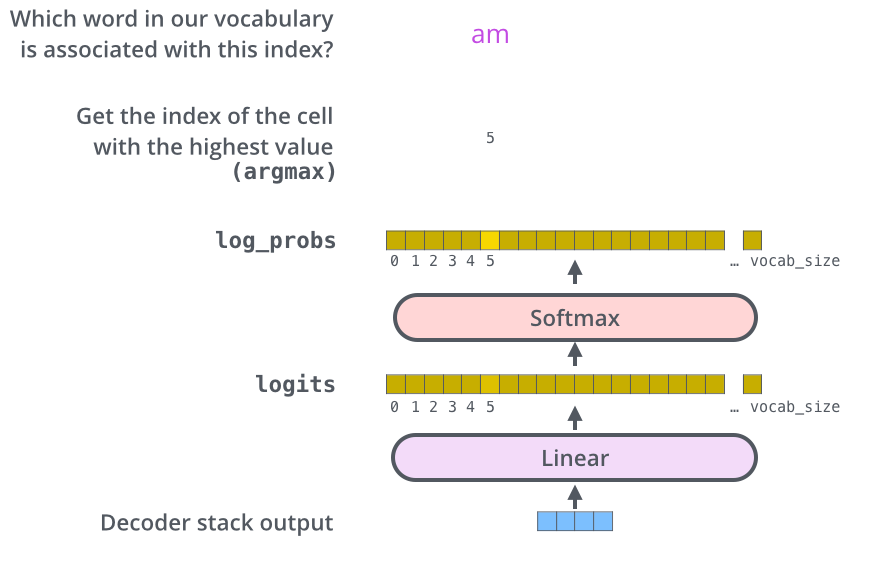
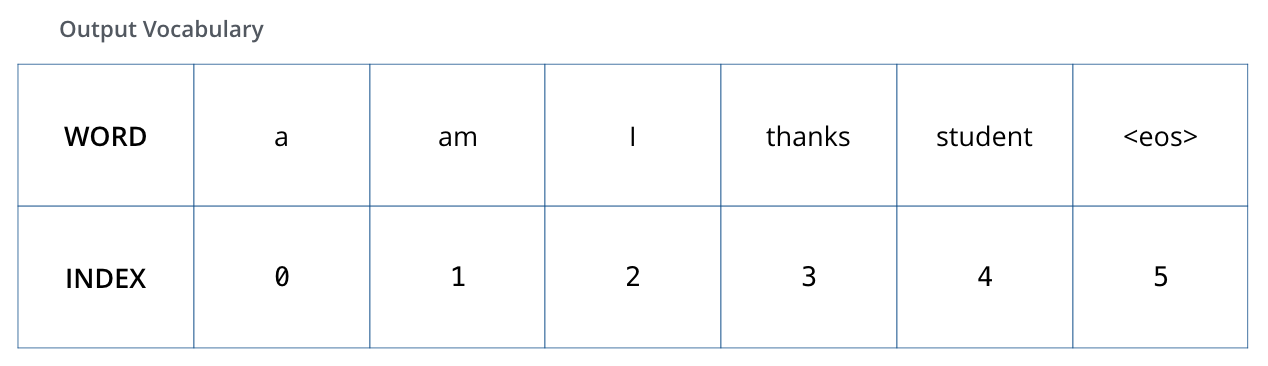
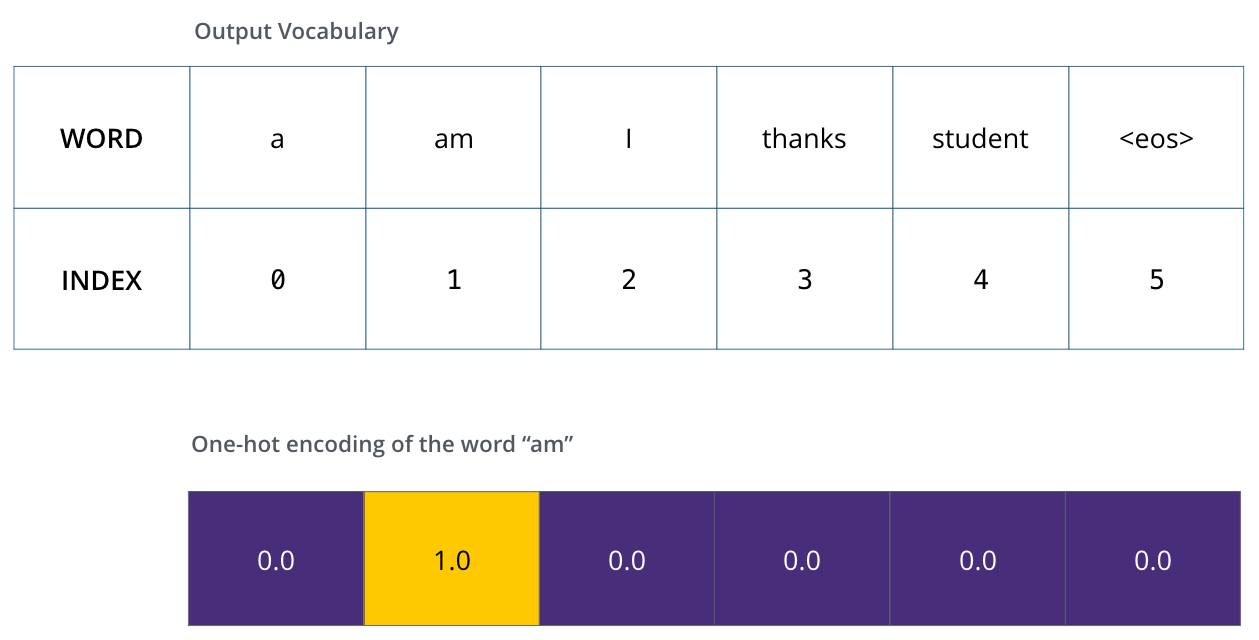
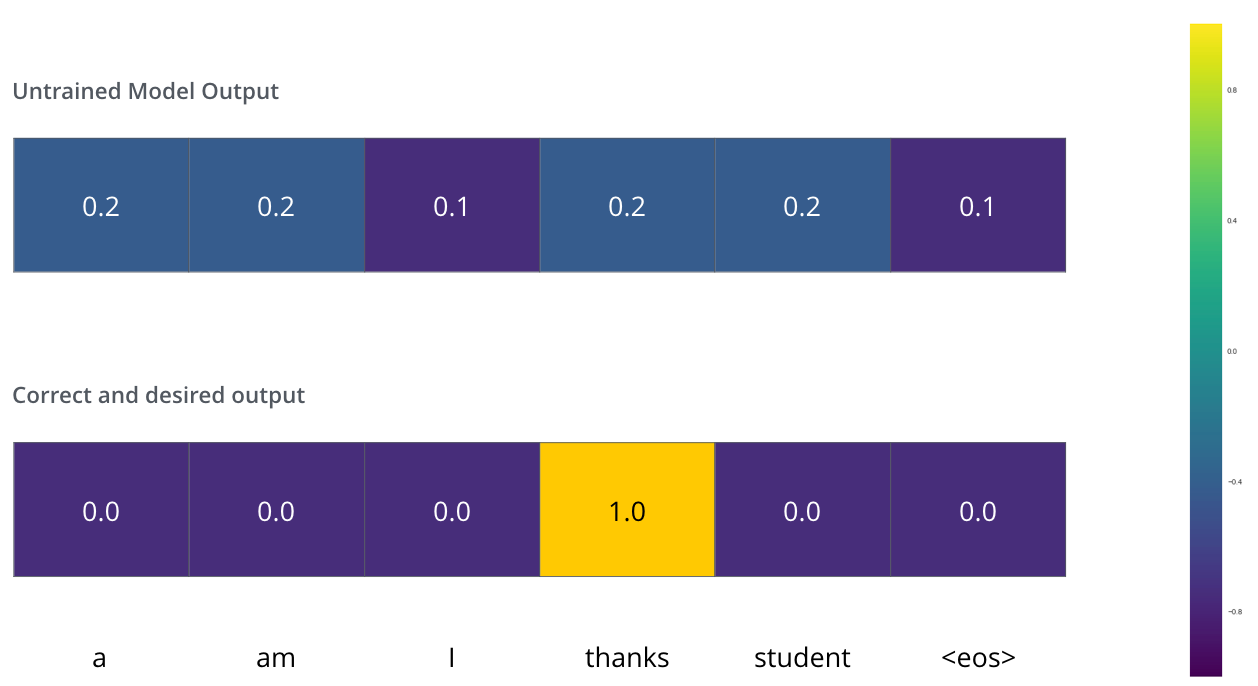
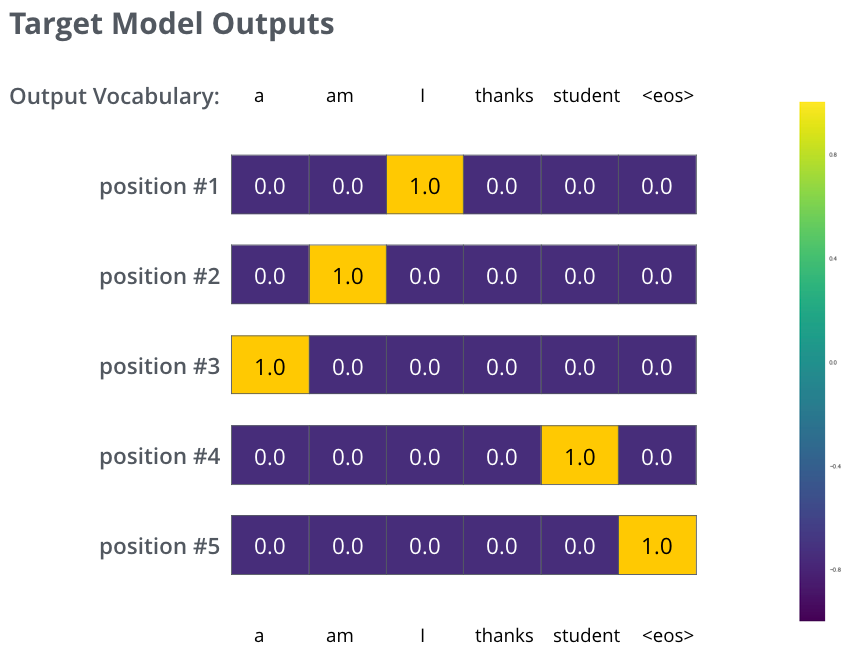
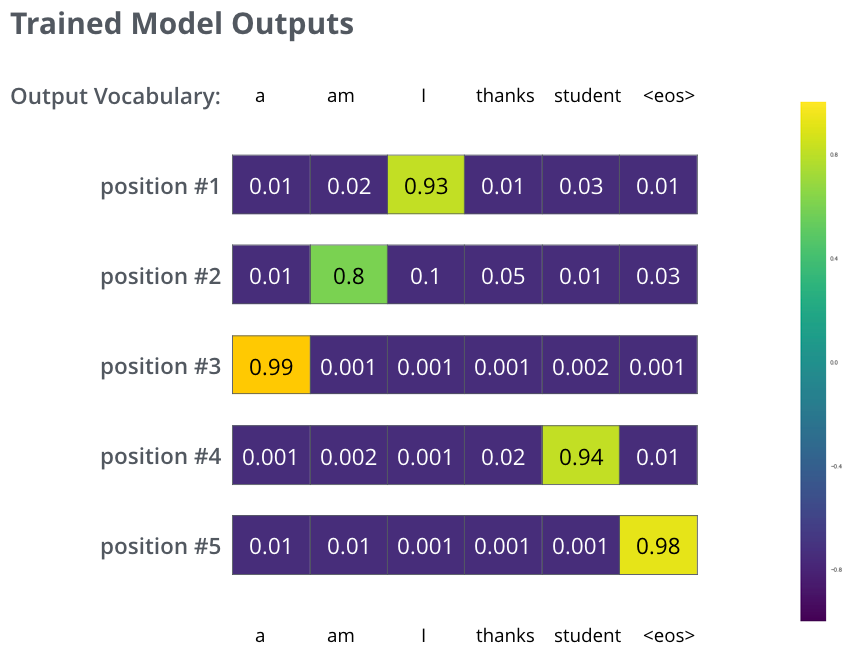
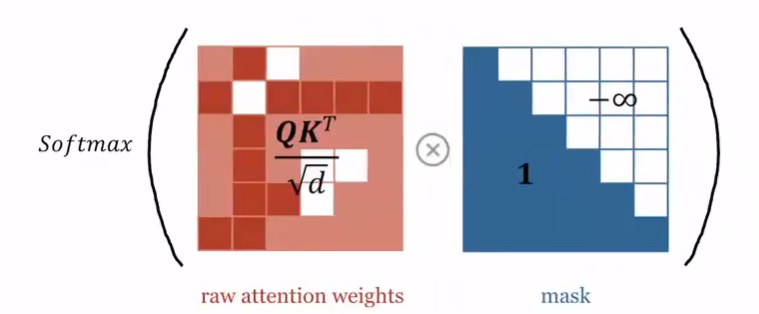
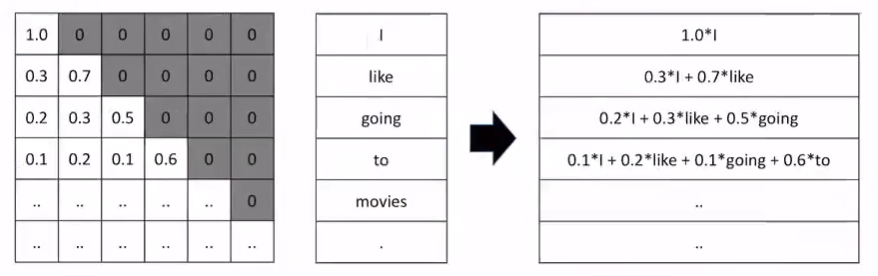
4. Masked Self-Attention

'AI Theory > NLP' 카테고리의 다른 글
| [NLP] RNN, LSTM, GRU를 비교해보자 (0) | 2022.05.09 |
|---|

댓글