AID: Attention Interpolation of Text-to-Image Diffusion 논문과 비슷하게 image interpolation task(여기서는 image morphing task)를 수행한 연구다.
실험부분에 AID와의 비교가 없어서 찾아보니, 이 논문이 선행연구여서 AID의 Appendix E에 본 논문(IMPUS)과 DiffMorpher(CVPR 2024)과의 비교가 있었다. 본 논문에서는 AID 이전에 있었던 diffusion interpolation 논문인 Interpolating between Images with Diffusion Models (ICMLW 2023)하고만 비교한다. 선행연구인 Interpolating ~ 이 논문이 real image에 대한 interpolation을 잘 못해서(직접 돌려봤을때) 실험 비교에서는 좀 재미가 없긴했다. 또 AID는 내가 아는 한 real image interpolation이 불가능한데(최소한 공개된 코드만으로는), AID와의 비교도 있었으면 좋겠다는 생각을 했다. 개인적으로 diffusion model을 활용한 interpolation / image morphing 연구는 좀 더 일찍 나올만 했던 것 같은데, 상당히 늦게(요즘 많이) 나오는 것 같다. AID를 비롯해서 이 논문, DiffMorpher(이건 아직 안봤지만) 등 보다 더 좋은 메소드가 있을 것 같은데, 보기엔 쉬워보여도 방법론을 구축하는 직관은 역시 쉽게 생기지 않는 것 같다.
그럼에도 이 논문은 나한테 정말 큰 의미가 있었는데, 우선 diffusion model + optimal transport를 제안한 논문(Understanding DDPM Latent Codes Through Optimal Transport, ICLR 2023)을 알려주고, diffusion model을 (꼭 image morphing task가 아니더라도) optimal transport와 연관지어 생각해볼 수 있다는 것을 알려줬다.
요즘 기대수 해석학과 함께 optimal transport를 찍먹하려는 나에게는 매우 흥미로운 직관이였다. 논문 자체가 "왜 잘되는지"에 대한 설명은 좀 부족했지만, 이건 많은 AI 논문들이 이 정도로 넘어가는 것 같고, method 구축까지의 과정이 꽤나 참신해서 배울점이 많았던 것 같다.
arxiv : https://arxiv.org/abs/2311.06792
code : https://github.com/GoL2022/IMPUS
Before reading
- 논문 제목을 보고 해당 모델이 어떤 방법론을 바탕으로 할지 가설을 세워봅시다.
- PERCEPTUALLY UNIFORM SAMPLING을 이용해 image morphing을 한다는데, 제목이 본 논문의 내용을 잘 대표하고 있지 못하는 것 같다. LoRA 얘기를 해야하는 거 아닌가...?
1. Introduction
- 논문이 다루는 task : Image morphing task(image interpolation)
- Input : 2 images
- Output : (some) interpolated images
- 해당 task에서 기존 연구 한계점

Interpolating between Images with Diffusion Models (ICMLW 2023) : 그냥 image interpolation을 잘 못한다.
2. Related Work
Text-to-image Generation
Glide, SD, Textual Inversion
Image Editing
SDEdit, Imagic, Instructpix2pix, P2P, NTI
Image-to-image Translation
plug-and-play Diffusion, VCT
<to read>
Dual Diffusion Implicit Bridges for Image-to-Image Translation (ICLR 2023)
Unpaired Image-to-Image Translation via Neural Schrödinger Bridge (ICLR 2024)
Image Morphing
-> uses neural networks to learn the morph map between two images (interpolation과 매우 유사)
-> 보통은 사람의 개입이 필요 or 매우 좁은 도메인에서만 가능 -> 본 논문은 X
3. 제안 방법론
- Desiderata for Image Morphing
image morphing problem은 constrained Wasserstein barycenter problem으로 나타낼 수 있다. (논문 참고)
쉽게 말하면 두 이미지의 distribution을 각각 ξ_0과 ξ_1로 나타냈을때, 이를 이용해 α-parameterized distribution ξ_α를 찾는 것이다.

그러나 위 수식을 real word에서 잘 모델링하는것은 매우 어렵다. (image의 dimension이 매우 높기 때문에)
따라서 본 논문에서는 아래 세 가지 특성에 (특히) 초점을 맞춤
- Smoothness:
- 생성된 이미지 변환 시퀀스의 두 연속 이미지 간의 원활한 전환 (not stringent constraint but perceptually smooth path)
- Realism:
- high-density region에 위치한 시각적으로 현실적인 이미지 생성
- Directness:
- 최소한의 변형으로 효율적인 변환 경로 구현 (optimal transport)
- Main Idea
INTERPOLATION IN OPTIMIZED TEXT-EMBEDDING AND LATENT-STATE SPACE
- Interpolating Text Embeddings
- CLIP feature space is densely concentrated and locally linear (이미 발견된 사실)
- 본 논문에서는 두 image의 CLIP text embeddings e(0)과 e(1) 사이를 linearly interpolate(아래 수식)
- 이때 text prompt를 <An image of [token]> 등으로 하는데, [token] 자리에는 (예를들어) flamingo, ostrich의 경우 root class인 "bird"를 하거나, beetle과 car처럼 root class가 다르면 "beetle car"을 대입.

- e(0), e(1) 각각에 대한 조건부 확률 pθ(x|e(0)),(1)로 표현하고 이를 interpolate하면 pθ(x|e(α)) = pθ(x|(1 − α)e(0) + αe(1))
- Interpolating Latent States
- pθ(x|e(α))를 계산하기 위해, 두 이미지 x_0와 x_1의 latent를 interpolate
- vanilla interpolation(image 자체로) -> 잘 안됨
- Probability flow ODE로 N(xT ; 0, I)으로 mapping을 한 뒤 interpolate (latent interpolation을 잘해야 -> image interpolation을 잘함)
- info diffusion에서와 같이 slerp(spherical linear interpolation)을 활용해서 interpolate

이때,

MODEL ADAPTATION WITH A HEURISTIC BOTTLENECK CONSTRAINT
image pair가 의미적으로 다를 경우 심각한 artifact가 발생
-> direct & intuitive interpolation을 하기 위해 image pair에 model adaptation 적용
-> 주어진 이미지와 관련 없는 high-density regions을 억제하므로서 morphing process의 variation을 제한할 수 있다.
standard approach는 아래 수식처럼 finetuning 하는 것인데, 이렇게하면 image detail의 손실이 생김(-> mode collapse)

따라서 본 논문에서는 LoRA(low-rank adaptation)를 채택하여 heuristic bottleneck constraint를 둔다. (아래 수식)

💡 LoRA의 low-rank bottleneck 덕분에 mode coverage를 유지하고, catastrophic forgetting의 위험을 줄일 수 있음
이때, LoRA rank가 크면 image divesity를 억제하여 morphs의 directness가 강화되지만, fidelity가 낮은 결과가 나올 수 있으므로 적절한 trade-off를 찾아내야함. (보통 2,4 등을 사용하는 것 같음)
- Relative Perceptual Path Diversity
Relative Perceptual Path Diversity (rPPD) : 이미지 모핑 과정에서 연속된 이미지들 사이의 다양성을 측정
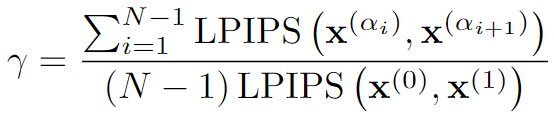
(Empirically) 이렇게 구한 gamma γ를 이용해 LoRA의 rank r_e를 구해준다.
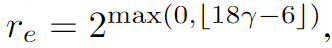
- Unconditional Bias Correction
여기서도 역시 CFG를 활용하는데, CFG를 활용하면 unet의 파라미터가 conditional일때와 unconditional일때 공유되므로, unconditional distribution도 변경되어 예상치 못한 bias가 발생할 수 있음
해결 방법으로는 아래 두가지를 고려
1) randomly discard conditioning (like CFG)
2) separate LoRA parameters for fine-tuning the unconditional branch on x0 and x1
후자가 좀 더 효율적(bias correction에 더 robust함)
즉 아래 수식과 같이 x0와 x1의 unconditional branch에 대해서도 LoRA 파라미터를 분리하여 fine-tuning하는 것이다.
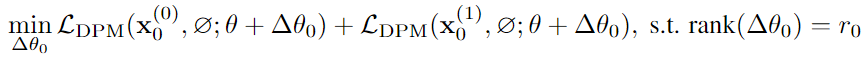
Inference 시에는, 위 conditional, unconditional part를 w, (1-w)를 곱하여 더해 noise prediction을 수행한다.
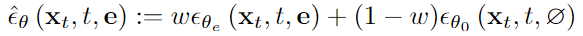
PERCEPTUALLY-UNIFORM SAMPLING
매끄러운 image morphing sequence를 생성하기 위해 연속 샘플들이 유사한 perceptual difference를 가지도록 해야함(AID에서는 beta distribution을 활용해 해결)
-> Uniform sampling으로는 부족 -> adaptive interpolation parameters {α_i}를 통해 해결
핵심은 binary search를 통해 일정한 LPIPS 차이를 갖는 interpolation parameters α_i를 근사.
- Contribution
제목에 PERCEPTUALLY UNIFORM SAMPLING이 들어간 것 치고, 이 부분에 대한 설명은 굉장히 미미하다.
오히려 LoRA에 대한 설명이 많은데, Low Rank adaptation을 통해 image pair가 의미적으로 달라도 morphing을 자연스럽게 할 수 있게 한 건 신기한 것 같다.
4. 실험 및 결과
- Dataset
1) benchmark datasets for image generation (CelebA-HQ, AFHQ, LSUN)
2) internet images
3) 25 image pairs from " Interpolating between Images with Diffusion Models (ICMLW 2023)"
- Baseline
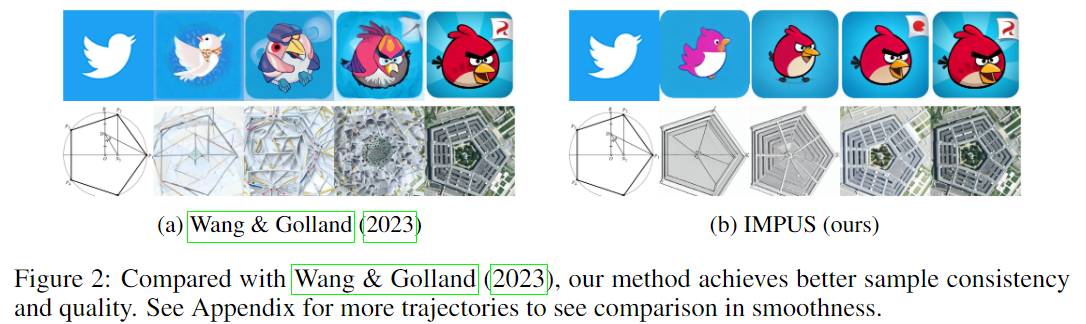
- Results
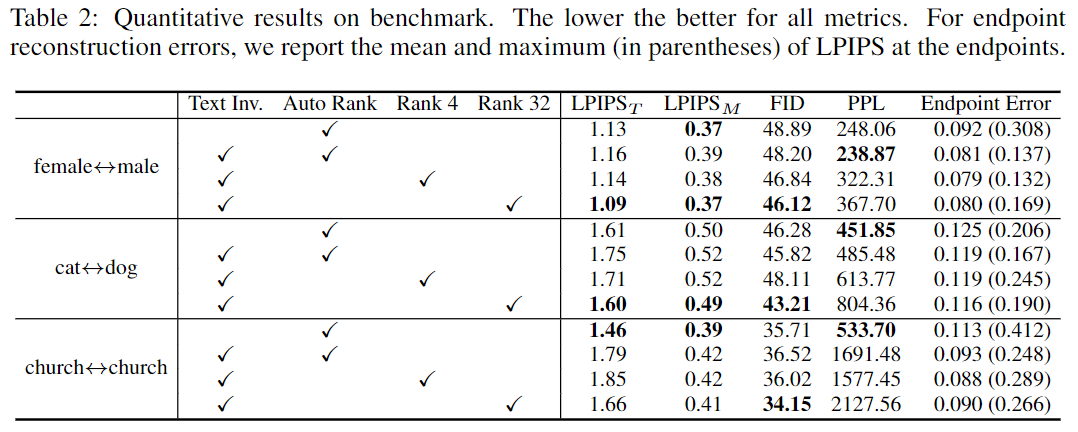

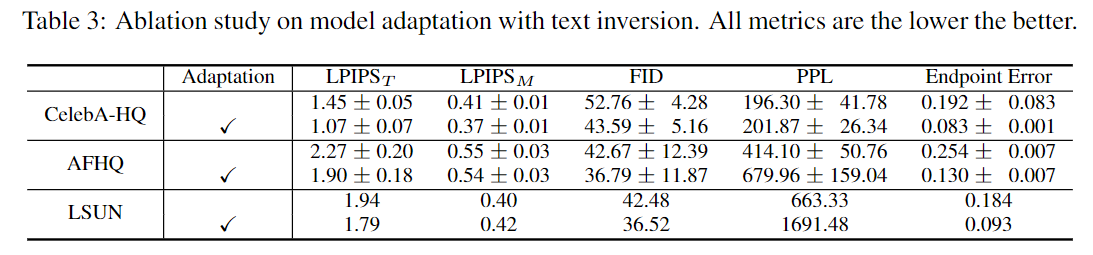

- Conclusion (What I learned)
Image Morphing이 잘 안되던 것을 LoRA로 푼게 인상적이였다. 실험도 되게 많이 한 것 같고 연결짓기가 어려웠을텐데 설득력 있는 논문이였다.




댓글