목차
arxiv : https://arxiv.org/abs/2210.00939
code : https://github.com/KU-CVLAB/Self-Attention-Guidance
cfg에 대한 깊은 고민을 하다가 관련 연구들을 좀 찾아보았다.
김승룡 교수님 연구실에서 낸 SAG와 PAG를 읽고, 몇 개의 다른 guidance 관련 논문들을 읽어보려한다.
(https://arxiv.org/abs/2401.02847, https://arxiv.org/abs/2301.12334, https://arxiv.org/abs/2404.07724, https://arxiv.org/abs/2312.02150, https://arxiv.org/abs/2302.07121, https://arxiv.org/abs/2306.00986)
cfg에 대해 좀 더 잘 알게되면 Inverse problem으로 넘어가야겠다.
Before reading
- 논문 제목을 보고 해당 모델이 어떤 방법론을 바탕으로 할지 가설을 세워봅시다
- Self-Attention Guidance를 준다는 것 같다.(당연히)
- 논문의 main figure를 보고 전체 흐름을 유추해봅시다.
- 이해되지 않는 파트가 있나요? 있다면 미리 표시해두고 집중적으로 읽어봅시다.

박사님께서 랩미팅때 cfg에 대한 얘기를 하신적이 있으셨는데, 그때 나온 문제점들을 개선한 것 같다. unconditional unet과 conditional unet을 이용해 guidance를 주는게 아니라(cfg) blurred(perturbed) image x^_t와 original image x_t를 이용해 guidance를 주는 것 같다.
1. Introduction
- 논문이 다루는 task : diffusion guidance method
- 해당 task에서 기존 연구 한계점
cfg / cg의 문제 : external condition(label)을 얻기가 어려움 -> conditional generation settings에서만 가능
SAG(본 논문) : Gaussian Blur를 통해 conditional setting이 아니여도(extenal condition이 없어도) guidance를 줄 수 있는 cfg의 좀 더 general한 방식을 제안했다.
2. Related Work
Diffusion models, CG / CFG, Self attention in generative models, Internal representations of diffusion models
3. 제안 방법론
- Main Idea
SAG는 Gaussian Blur를 활용해서 구한 x^~_0를 이용해 x^~_t를 구하고, 이를 이용해 classifier guidance 처럼 guiding을 준다.
이때, M_t라는 mask를 활용해 self attention의 특정 부분에만 guiding을 주는데, 알고리즘은 위 그림의 좌측과 같다.
만약에 이때 guidance scale을 5보다 큰 값을 사용한다면( + mask를 사용하지 않는다면), 아래 figure의 윗 줄 처럼 noisy한 image가 생성된다. (아래 줄은 applying SAG)

따라서 masking을 해주기 위해 self-attention map 활용
self attention map은 아래 식처럼 Attention map에 GAP(global average pooling)을 해주고, reshape과 upsample을 통해 구해준다. 그 후 threshold phi값을 활용해 masking을 해준다. 아래 흐름과 같다.
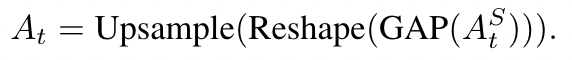
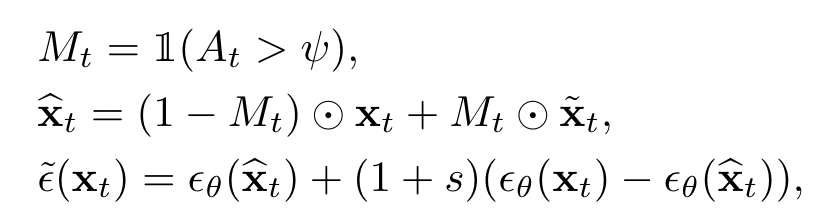
요약하자면, 본 논문은 classifier free guidance의 식과 유사하게 guidance를 주는데, x_t를 x_0로 approximate하고, x_0를 gaussian blur를 적용해 x_0^~로 만든다. 그 후 다시 noise를 주입한 뒤 x_t^~를 만들고 attention map M_t를 이용해 cfg처럼 guidance를 준다.
4. 실험 및 결과
3090 8대
- Baseline
ADM, IDDPM, StableDiffusion, DiT
- Results


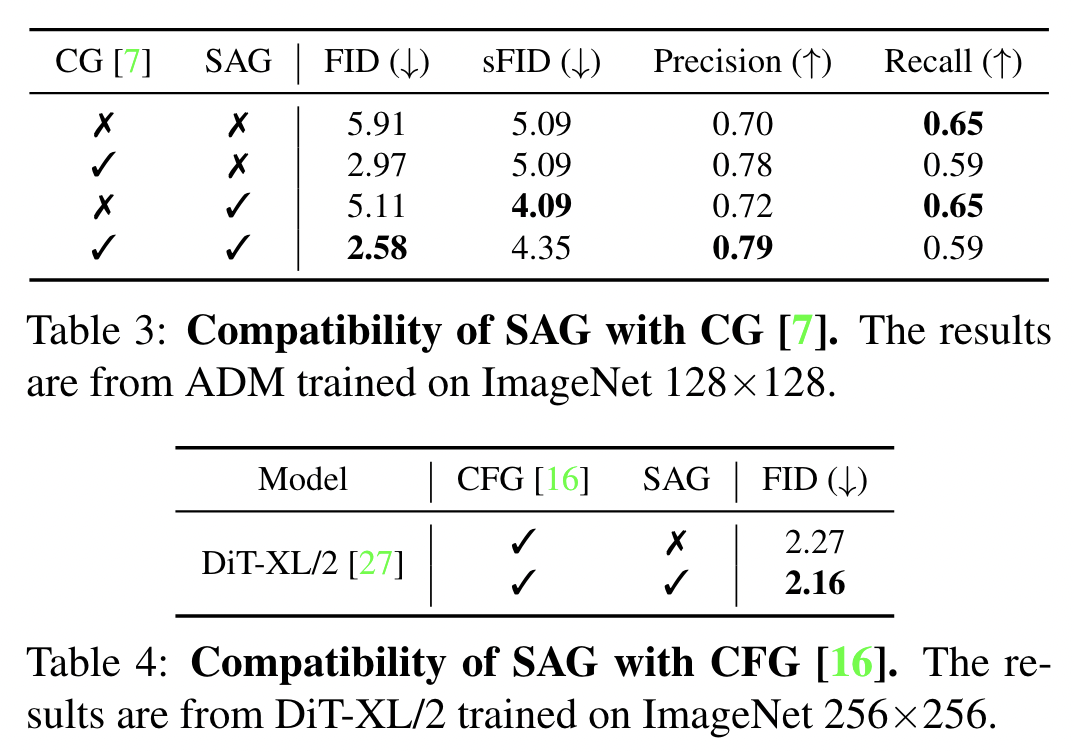
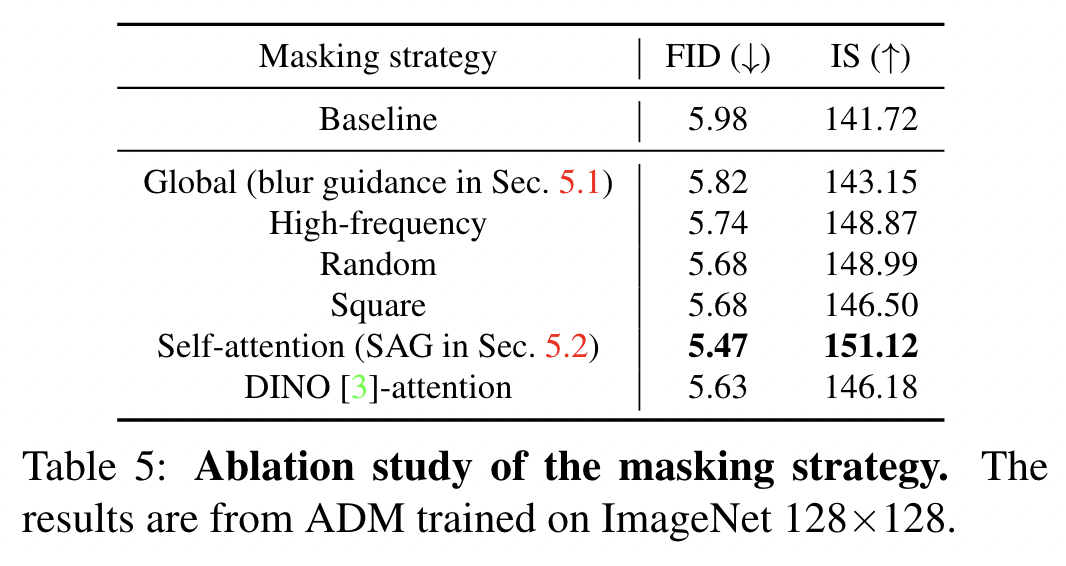
신기한 점은 random mask(40% of all pixels)가 global masking보다 성능이 좋다. (Table 5)
- Conclusion (What I learned)
guidance에 대해서 좀 더 깊게 고민해볼 수 있었다. (아이디어도 두개정도 떠올라서 굉장히 기분이 좋다)




댓글