arxiv : https://arxiv.org/abs/2309.06933
code : https://github.com/webtoon/dreamstyler
Before reading
- 논문 제목을 보고 해당 모델이 어떤 방법론을 바탕으로 할지 가설을 세워봅시다.
- Style Inversion이라는 것을 통해 style을 저장(?)한 뒤 그 style을 원하는 프롬프트 혹은 이미지에 입혀서 새로운 이미지를 생성하는 논문일 것 같다.
- 논문의 main figure를 보고 전체 흐름을 유추해봅시다.
- 이해되지 않는 파트가 있나요? 있다면 미리 표시해두고 집중적으로 읽어봅시다

figure만 보고 유추를 해보자면, Style을 BLIP-2를 이용해 captioning을 하고 그 정보 C_c와 prompt로 부터의 token C_o, S*를 합쳐서 text encoder에 넣는 방식인 것 같다. 이때 학습되는 것은 S* 토큰, 즉 style token이다.
Text Encoder를 통과해서 나온 embedding vector v_{t+1}*, v_{t}*, v_{t-1}*는 각각 unet의 t+1, t, t-1 step에 주입되고, 이를 활용해 x_0를 생성하는 것으로 보인다.
1. Introduction
- 논문이 다루는 task : image editing
- Input : query image(바꾸고자하는), 원하는 style들의 images(train용)
- Output : new image (=query image + train용 image들의 style)
- 해당 task에서 기존 연구 한계점
- style transfer에서 Gogh style? 이라고 하면 구체적으로 어떤 스타일인지 애매함 -> image conditioned style transfer의 필요 이유
- Dreambooth나 textual inversion에서 특정 토큰 한 개에 object나 style 등을 잡으려하는데, embedding space가 충분히 이를 담지 못함.
2. Related Work
- Personalized text-to-image synthesis
대부분 읽어본 논문들 .. P+ 정도 읽어볼 것
- Paint by style
AdaIN, AdaAttn, AesPA-Net, StyTr^2, InST 등등 ..
3. 제안 방법론
- Main Idea
크게 Multi-Stage Textual Inversion, Context-Aware Text Prompt, Style and Context Guidance 이렇게 세 가지임.
우선 training에서는 위 그림에서 처럼 painting과 <S*> style을 나눠서 encoding에 넣는다. -> 시도해볼만 함
(style과 object를 disentangle를 하는데 더욱 효과적이라고 주장)
그리고 Style image (1장)에서 BLIP-2로 뽑은 caption도 같이 text encoder에 넣는다.(이 부분이 Context-Aware Text Prompt)
(BLIP-2가 잘 뽑지 못하는 caption에 대해서는 human feedback활용 -> BLIP-2가 과연 captioning을 잘 하려나 .. 싶었는데 역시나 ..)
참고로 이때 S* token은 복사해서 여러개(n개)를 만들고 이를 각각 n개의 stage들에 하나씩 주입
-> 이렇게 하면 각각의 S*들이 해당 process에 맞는 embedding을 더 잘 갖게된다고 주장 (Multi-Stage Textual Inversion)
그리고 sampling때는 이렇게 학습시킨 S*을 완전한 prompt에 넣어 image 생성.
Source image는 controlnet encoder 등을 활용해 encoding.
또한 이때 classifier guidance처럼 style and context guidance를 써주는데, 기존의 2 condition guidance와 식이 조금 다르다.

위 식에 대한 증명은 아래와 같다. bayes' rule 정도만 알면 어렵지 않게 따라갈 수 있고, 직관적으로 3번식을 classifier-free guidance term과 비교해봐도 쉽게 납득할 수 있다.

학습은 기존의 textual inversion과 동일하게 아래 식으로 학습

4. 실험 및 결과
- Dataset
trained with 32 artistic style images
evaluated for 40 text prompts
- Baseline

- Results

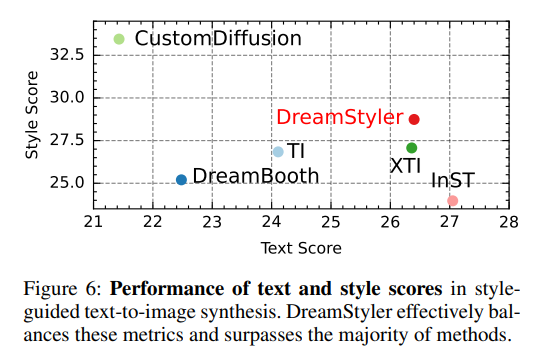
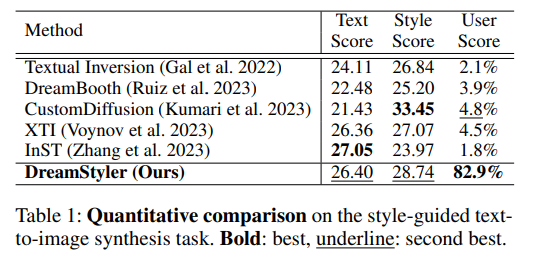
우측 Table 1을 보면, DreamStyler가 Text Score과 Style Score에서 1등은 아니지만, trade-off가 가능하다고 말하고 있다. 그래도 조금 정량평가 자체는 아쉬운 것 같다.

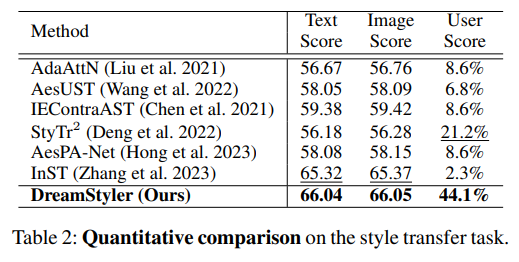
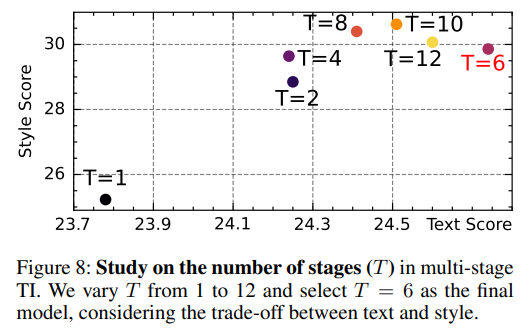

Stage 수 (T)를 무조건 크게하는 것이 좋지는 않다. 6일때가 optimal.

guidance 계수를 통해 각각의 세기 조절 및 style mixing도 가능(내 연구와 연결?))
- Conclusion (What I learned)
네이버 웹툰에서 낸 논문이라 재밌게 읽었던 것 같다.
task가 워낙 애매(?)해서 정량평가나 BLIP-2등으로 captioning prompt를 뽑아줘야하는 등의 아쉬움은 있었지만, 배울점이 정말 많았고 textual inversion에 대해 고민을 많이 한 게 느껴졌다.




댓글