ImageBrush의 후속 연구.
ImageBrush 저자들한테 코드 공개 계획에 대해 메일을 보내봤지만 연락이 없었다. 그러던 중 후속 연구로 이 논문을 발견하게 되었는데, 코드가 공개되어 있었다.
arxiv : https://arxiv.org/abs/2405.10316
code : https://github.com/edward3862/Analogist
1. Introduction
- 논문이 다루는 task : ICL + diffusion model
- Input : A, A', B (three images)
- Output : B' (one image)
- 해당 task에서 기존 연구 한계점
ICL + diffusion model들은 디테일한 부분까지 잡지는 못함.
학습 시간도 오래걸리고 training-based methods의 경우 in-context task들을 지정해 데이터셋도 구성해야함 -> cost가 많이 듦
2. Related Work
2.1 Visual In-Context Learning
- Training-based methods
Painter, ImageBrush, SegGPT, PromptDiffusion, ImageBrush
- Inference-based methods
MAEVQGAN, VISII
2.2 Image Analogies
-> A:A' = B:??? 에서 ??? 즉 B'를 유추하는 task를 image analogies task라고 함.
DIA : investigates the image analogies task with diffusion model
2.3 Prompt-based Image editing
InstructPix2Pix, MasaCtrl, zero-shot I2I translation
3. 제안 방법론
- Main Idea

- 우선 4개의 이미지(A,A',B,???)를 GRID 형식으로 붙여서 Input I를 만든다.
- B를 ??? 자리에 그대로 복사해 I'를 만든다.
- I와 I'를 각각 frozen Encoder에 태워 E(I), E(I')를 만들고, E(I)에는 마스킹을 씌워 이를 E(I')와 concat해 x_t를 만든다.
- 이렇게 만든 x_t를 Unet에 넣어 x_{t-1}을 만드는데, 이를 반복해 x_0(real image)를 만든다.
- Unet 안에서는 SAC와 CAM이 일어나는데, 각각에 대한 설명은 아래와 같다.


SAC는 Self-Attention Cloning으로 쉽게 말해서 A와 B사이의 Self attention map M_s(A,B)를 clone해서 A'와 B' 사이의 Self attention map M_s(A',B')로 사용하는 것이다. 아마 A->B의 realtion이 A'->B'에도 적용되어야 하기 때문에 이를 attention map cloning으로 해결한 듯 보인다.
Q. hw / 4는 왜 해주는 것인가...?

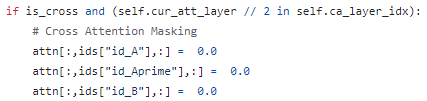
CAM은 GPT-4v로 추출한 textual prompt를 B'에만 주입하기 위해 A,A',B의 cross-attention map에 masking 처리를 하는 것이다.
- Contribution
- pretrained diffusion (inpainting) model을 활용해 visual in-context learning을 가능하게 했다.
- fine-grained contextual information을 주기 위해 SAC(Self-Attention Cloning) 제안
- textual guidance를 주기 위해 GPT-4V를 사용해 textual prompts를 주는 CAM(Cross-Attention Masking) 제안
4. 실험 및 결과
- Dataset
Low-level task, Manipulation task, Vision task 세개로 나누고 각각의 task는
- Low-level task(image colorization, deblurring, denoising, enhancement) (100 samples each)
- Manipulation task (image editing, translation, style transfer) (200 samples each)
- Vision task (skeleton-to-image generation, mask-to-image generation, image inpainting) (200 samples each)
로 구성된다.
- Baseline



Quantitative Comparision에는 주로 Clip score를 그리고 FID와 user study를 활용하였다.
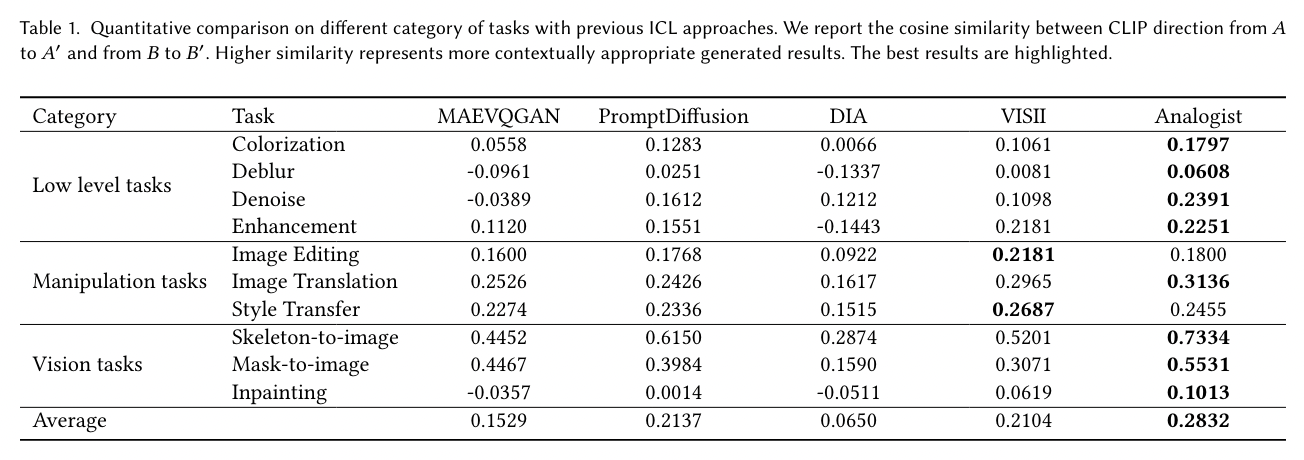
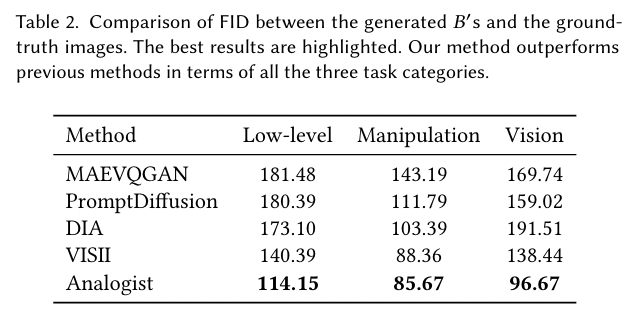
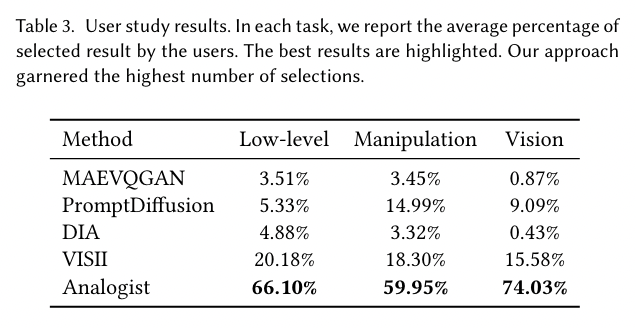
Ablation test



위 instruction의 이미지부분에 나와있듯이 GPT-4v를 사용할 때 image grid I에 각각의 image에 대한 notation인 A,A',B,B'를 표시하고(좌측 상단), 빨간색 화살표로 A->A', B->B'를 표시했다. 이를 안하면 GPT가 prompt를 잘 생성하지 못한다고 한다.

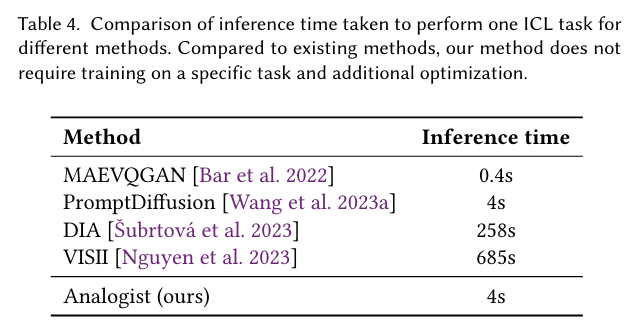

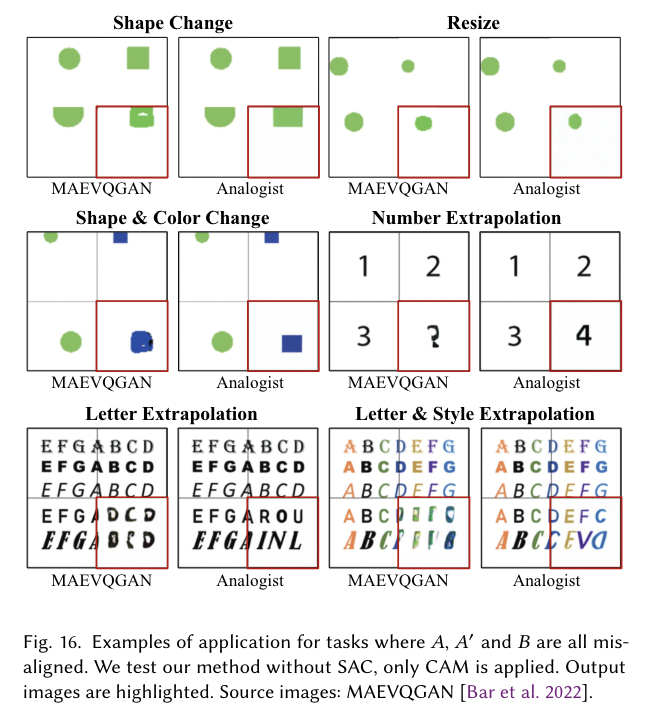
- Conclusion (What I learned)
우선 코드가 공개되어있어서 정말 감사한 것 같다. 코드 공개를 하는게 거의 업계 국룰(?)인데, 여러가지 이유에서 아직도 많은 논문들의 코드가 공개되어있지 않은 것 같다. 개인적으로 학회에 accept된 paper는 코드를 무조건 공개하는게 맞지 않나 싶다..
논문적으로는 성능이 여전히 아쉬운 것 같다. 추론도 잘 못하고, relation을 주입하는 것이 attention cloning이 전부인데 이걸로 두 이미지들의 detail한 정보까지 전달하기는 어렵다고 생각한다.(물론 논문에서는 그래서 gpt를 써서 textual prompt도 준다고 하지만, gpt를 쓰는 것 자체가 별로..)
무엇보다 ICL이라고 하면, LLM에서는 최대 입력 토큰 수가 허락하는 한 n개의 ICL example을 입력으로 줄 수 있고, 이에 따른 성능도 점차 향상하는데, GRID 형식으로 이미지들을 붙여서 ICL을 수행하는 것이 맞는 방식인지에 대한 고민도 있다. (굉장히 마음에 안드는 방식이다.)
그치만! 굉장히 배울점이 많은 논문이였고, 실험도 되게 많이 했고 고민의 흔적이 느껴져서 좋은 논문이라고는 생각한다.




댓글