arxiv : https://openreview.net/pdf?id=mhgm0IXtHw
code : https://github.com/hansam95/NMG
1. Introduction
- 논문이 다루는 task : text guided image editing
- Input : image
- Output : (text guidance를 통해 condition된) image
- 해당 task에서 기존 연구 한계점

DDIM inversion의 image reconstruction은 원래 이미지로 복원하지 못하고, 전혀 다른 이미지로 reconstruct되는 문제점이 있다.
(Prompt-to-Prompt에서는 이러한 문제점의 원인이 CFG(classifier free guidance)에 있다고 말한다.)

Null Text Inversion(NTI)이 이러한 문제점을 null text("")를 optimization해서 해결(a 그림에서 alignment를 맞추는 것)하는 듯 했으나, image의 spatial context를 포착하지 못하고 optimization 과정에서 computation cost가 많이 필요하다.

Noise Map Guidance(NMG)는 NTI와 다르게 최적화가 필요 없지만, editing quality는 유지한다.
2. Related Work
Inversion with Diffusion Models
- Null Text Inversion (NTI) : null text optimization을 통한 accurate image reconstruction, but need intensive computation
- Negative Prompt Inversion (NPI) : approximates the optimized null text embedding(optimization-free) but cannot maintain spatial context of the original image
- ProxNPI : retaining spatial context and follow the original inversion trajectory but adhere closely to the original context
Editing with Inversion methods
- Prompt-to-Prompt : cross-attention maps to guide the editing sequence
- MasaCtrl : mutual self-attention to facilitate non-rigid editing (will read soon)
- pix2pix zero : cross-attention map guidance to perform zero-shot I2I translation
3. 제안 방법론
- Main Idea
score function(∇_{z_t} log p(z_t))으로 epsilon model을 표현해보면 아래와 같다.

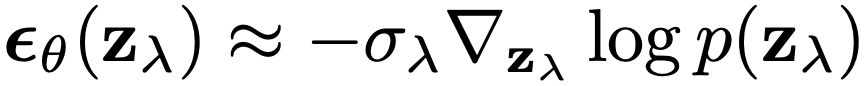
classifier free guidance paper에도 이렇게 된다고 나와있다. 다만 궁금한것은 sigma와 alpha의 등호가 이렇게 두면 성립하지 않는데, 아마 노테이션이 조금 다른것 뿐이지 않을까 생각하고 넘어갔다.
여기에 p(z_t)를 구하는 과정에서 condition c를 주면 아래와 같이 조건부로 표현할 수 있고,
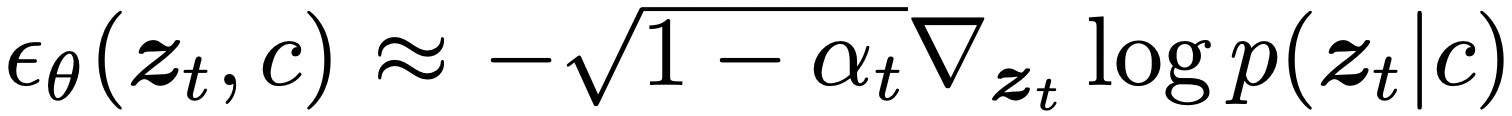
log p(z_t|c)를 bayes rule로 아래와 같이 두 term으로 쪼갤 수 있다.

EGSDE라는 논문(energy guidance를 소개한 paper, 읽어 볼 예정)에 의해 우측 log p(c|z_t)는 아래은 energy function E를 사용하여 나타낼 수 있다.

그리고 이 energy function E는 매 timestep마다의 noise map z_{t-1}의 L1 loss를 이용해 아래 9번식과 같이 표현할 수 있고, gradient scale을 조절하는 s_g를 앞에 추가해준다.

s_g의 크기를 조절함으로서 DDIM inversion trajectory(위 figure 2의 a)를 얼마만큼 수정할지(즉, 원본 이미지를 얼마나 보존할지) 그 정도를 조절할 수 있다.
그 다음, 이렇게 구한 epsilon_theta model을 noise map guidance scale인 s_N을 이용해 계산한다.

그리고 이를 이용해 z_{t-1}^NM을 구한다.

또한 경험적으로 z_{t}^NM을 z_{t-1}^NM로 근사시킬 수 있다고 한다.
마지막으로 이렇게 만든 noise map은 다시한 번 text embedding에 의해 아래와 같이 다시 쓰일 수 있고, 여기서도 s_T는 text condition의 정도를 조절하는 text guidance scale이다. 이는 CFG의 guidance scale w와 같은데 notation의 통일성을 위해 s_T로 썼다.

최종적으로 t-1 step에서의 latent variable은 아래 수식을 통해 구할 수 있다.

위 수식 (10,11,13)을 figur위에다가 표시해보면 아래와 같다.

Contribution
- optimization free(fast speed) + spatial context를 보존하면서 inversion 가능
- 다양한 실험에서 좋은 성능
4. 실험 및 결과
- Baseline
DDIM, NTI, NPI, ProxNPI
- Results


이 외에도 NMG + MasaCtrl, NMG + pix2pix-zero도 실험.

CLIP score나 TIFA도 거의 대부분의 경우에 가장 좋은 성능을 냈다. 또한 optimization이 필요 없기때문에 시간도 가장 적게 걸린다.(약 20배 빠름)

Guidance scale 및 Gradient scale에 대한 ablation test.





댓글