arxiv : https://arxiv.org/abs/2307.14352
code : https://github.com/CrystalNeuro/visual-concept-translator

1. Introduction
- 논문이 다루는 task : image2image translation, style transfer
- Input : 2 images (reference image, source image)
- Output : image (source image의 structure는 보존하고, reference image의 concept(style)을 적용한 new image)
2. Related Work
GAN
Image2Image translation task에서 기존의 GAN 기반 방법론들은 학습이 어렵고, mode collapse가 발생할 수 있으며, 새로운 도메인에 적용하기도 쉽지 않다.
특히 TuiGAN은 한 쌍의 이미지만으로도 image2image translation을 할 수 있는 장점이 있지만, 각각의 input pair에 대해 전체 full training을 시켜야해서 cost가 많이 든다는 단점이 있다.
Diffusion models
기존의 conditional diffusion model은 대부분 text-to-image와 같이 text가 instruction으로 들어오면 이를 source image에 반영한 target image를 output으로 출력하는 형태로 작동했다.
그러나 때로는 text instruction보다 image instruction이 더 직관적이고 디테일한 condition을 줄 수 있다.
이에 본 논문은 단 한 장의 image만으로 condition을 주어, source image에 reference image의 concept을 적용하는 Visual Concept Translator (VCT) framework를 제안하고 있다.
3. 제안 방법론
- Main Idea
VCT framerwork는 크게 두 부분으로 나뉜다.
a) Content-Concept Inversion
b) Content-Contcept Fusion

a) Content-Concept Inversion
Content-Concept inversion은 두 개의 input 이미지(source,reference)를 learnable text embedding(v^ref, v^src)으로 만들어주는 과정이다.
이때, source image를 embedding으로 바꿔줄 때는 Pivot Tuning inversion이 적용되고, reference image를 embedding으로 바꿔줄 때는 Multi-concept inversion이 적용된다.
(한가지 궁금한 사항은 ddim inversion은 image(224x224)를 noise(224x224)로 만들어주는 것 아닌가? 이것이 어떻게 text embedding으로 되어서 추후에 text encoder로 들어간다는 것인지 헷갈렸다.)
-> 해결 : 본 논문의 문제 세팅에서는 정확한 text prompt를 모르기 때문에 null-text inversion에서 제시되었던 unconditional DDIM inversion을 사용하여 v^src를 optimize했다고 한다. (아래 식 참고)

이때 z_0^hat은 Tweedie's formula(?)를 이용해 아래와 같이 쓸 수 있다.

b) Content-Concept Fusion
Content-Concept Fusion은 조금 더 복잡하다.
크게 (1) epsilon Space Fusion, (2) Dual-stream denosing architectrure 그리고 (3) Attention Control로 나뉘는데,
(1) epsilon Space Fusion부터 살펴보자.

epsilon space fusion은 쉽게 말해서 a) Content-Concept Inversion에서 추출한 두 텍스트 임베딩 벡터 v^src와 v^ref 를 fusion하는 것이다.

(Text Encoder에 v를 넣는것인가 .. ? 안 넣는 것 같은데 figure가 논문의 내용과는 조금 다른 것 같다.)
이때 입력으로 z_t, t, v 가 들어가고 epsilon_theta 즉 모델은 동일한 모델을 사용한다.
이렇게 model을 통과해 나온 각각의 epsilon들을 classifier-free guidance에서 처럼 w라는 guidance scale을 이용해 fusion해준다. 최종적으로는 아래 식과 같은 형태가 된다.
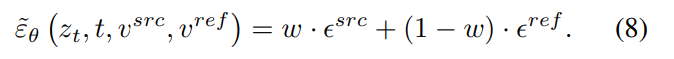
(본 논문의 저자들은 classifier-free guidance가 (8) 식의 특수한 경우라고 말한다.)
그 다음은 (2) Dual-stream denoising architectrure이다.
여기서는 본격적으로 image translation task를 진행한다.
x^src를 DDIM inversion한 initial noise를 x_T라고 하자.
x_T에서 시작하여 두개의 denoising process가 동시에 진행되는데,
하나는 main branch B이고, 다른 하나는 content matching branch B*이다.

content matching branch B*은 초기에 주어졌던 x^src를 완벽하게 reconstruct하는 것을 목표로 하고, (reconstruction task)
main branch B에서는 image2image translation을 수행하도록 denoising process가 진행된다. (I2I task)
조금 더 구체적으로, t시점에서 content matching branch B*는 text embedding v^src와 attention map M*을 추출한다.
이렇게 추출한 v^src와 M*은 main branch에서의 denoising step에 병렬적으로 이용된다.
x^src의 정보를 잘 주입하기 위해, 두 diffusion process는 거의 동일한 파이프라인으로 구성된다.
(epsilon fusion에서 v^none이 쓰이냐, v^ref가 쓰이냐가 주요한 차이)
위에서 (8)식에서 설명한 epsilon fusion은 content matching branch에서 아래와 같이 수행된다.
(즉, (8)식은 main branch의 epsilon fusion이고 (10)식은 content matching branch에서의 epsilon fusion)

이때, (8)과 (10)에서 w는 동일한 값을 사용한다.
마지막으로 (3) Attention Control에서는 prompt2prompt와 마찬가지로, cross attention map과 self attention map (둘 다 M으로 표기)을 통해 해준다.
특정 time stamp t 이전일때는, content matching branch의 attention map인 M*을 이용하고,
t 시점 이후에는 main branch의 attention map인 M을 이용한다.
식으로 보면 아래와 같다.

- Contribution
general I2I with image guidance by proposing a novel framework named VCT. (single reference image)
4. 실험 및 결과
- Dataset
LAION 5B
- Baseline
Stable Diffusion (https://huggingface.co/runwayml/stable-diffusion-v1-5)
- Results



Figure 6 : reference image는 다 다르게, content image는 fix
Figure 7 : one shot baseline들과의 비교 (Paint-by-example, ControlNet)


Figure 8 : Style transfer 실험 (P2P도 충분히 좋은 성능을 내지만, reference를 더 잘 따르는 것은 VCT이다.)

Figure 9 : reference와 content를 각각 고정시키고 바꿔가며 실험

Figure 10 : 제시한 각 아키텍쳐에 대한 ablation test
MCI : Multi-concept inversion
PTI : Pivotal turning inversion
AC : Attention Control
(사실 Attention Control은 P2P에서 처음 제시한 것 아닌가 ... ?)
- Conclusion (What I learned)
결국 내가 원했던 image를 vit 등의 transformer encoder를 활용해 직접 embedding으로 만드는 것은 아니고, null- text-inversion을 활용하는 방식이였다.
그래도 image instruction의 필요성에 대해 언급하면서 p2p등의 기존 모델들에 비해 가장 좋은 LPIPS score, CLIP score를 냈다는 것에 좋은 contribution이 있다고 생각한다.
(+ 논문에서 inversion관련해서 자주 나왔던 dreamartist도 읽어야겠다)




댓글