이번주에 읽으려고 계획했던 논문은 아래 7편의 논문이다.
[읽음]
Adding Conditional Control to Text-to-Image Diffusion Models (10 Feb 2023) - ICCV 2023
Visual Instruction Inversion: Image Editing via Visual Prompting (26 Jul 2023) - Neurips 2023
InstructPix2Pix: Learning to Follow Image Editing Instructions (17 Nov 2022) - CVPR 2023
Prompt-to-Prompt Image Editing with Cross Attention Control (2 Aug 2022) - ICLR 2023 (Oral)
[못읽음]
An image is worth one word: Personalizing text-to-image generation using textual inversion - ICLR 2023 (Oral)
InstructDiffusion: A Generalist Modeling Interface for Vision Tasks
Prompt-Free Diffusion: Taking “Text” out of Text-to-Image Diffusion Models
읽은 논문들은 전체적으로 diffusion에 prompt(visual prompt)를 어떻게 적용할지와 관련된 논문들이고 특히 선행연구, 후행연구 관계인 paper들이여서 한번에 읽으면서 연구 흐름을 파악하기 좋았다.
논문을 읽은 순서는 위와 같지만, 흐름의 자연스러움을 위해 arxiv에 submission된 순서로 리뷰해보겠다.
1. Prompt-to-Prompt Image Editing with Cross Attention Control
기존 연구(GLIDE, SDEdit 등)는 image inpainting을 할 때 masking을 해서 고정시키고자 하는 부분을 condition으로 주는 경우가 많았다.


다만 editing을 할 때 마다 마스킹을 제공하는 것은 상당히 번거롭고, 빠르고 직관적인 text-driven editing은 어렵다는 단점이 있다.
본 논문에서는 cross attention을 활용해 specific object는 고정한 상태로, prompt에 맞는 inpainting을 수행하였다.
diffusion model의 최근 연구 흐름은 이와 같이 specific object는 바뀌지 않으면서, 원하는 부분만 prompt로 잘 수정하게 하는 쪽으로 흘러가는 것 같다. 무엇보다 이런 방식으로는 특정 object의 texture를 수정하는 것은 할 수 없다.(사람 얼굴을 웃게 만든다던지)

논문에서 제시한 figure인데, 결국 random seed만을 고정하는 것만으로는(위 그림의 점선 아래 부분) specific object(네모난 케이크의 형태)를 보존할 수 없고, text prompt에만 적합한 이미지가 나온다.
이를 위해 image pixel과 prompt text token 사이의 internal cross-attention maps을 diffusion process 때 적절하게 injecting 해야한다. 결론적으로 아래 세 가지를 할 수 있다.
1. change a single token's value in the prompt, while fixing the cross-attention maps, to preserve the scene composition. (배경은 유지한 상태로 대상 변경)
2. globally edit an image, by adding new words to the prompt and freezing the attention on previous tokens, while allowing new attention to flow to the new tokens. (대상은 유지한채로 전체적인 이미지 수정)
3. amplify or attenuate the semantic effect of the word in the generated image. (editing 효과의 강도 조절)
그리고 무엇보다 이 논문 역시 추가적인 training, fine-tuning, extra data, or optimization이 전혀 필요 없다.
💡 본 논문과 Asyrp 혹은 plug-and-play diffusion과의 차이는 무엇일까?
본 논문에서 말하고 있는 attention을 잘 활용하는 것은 이미 plug-and-play diffusion(22 Nov 2022)에서 보여준 적이 있고,
Asyrp(20 Oct 2022)에서 제시한 h-space 역시 cross-attention map과 비슷한 역할을 한다.
내가 생각하는 차이점은 아래와 같다.
- plug-and-play diffusion은 DDIM inversion 후 이를 denoising하는 과정에서의 spatial feature 및 self-attention query, key를 inject한다. 즉, cross-attention은 활용되지 않는 것이다.
- Asyrp의 h-space는 U-net의 가장 깊순한 layer로 이를 잘 조작해서 DDIM process를 개선한 논문이다. 즉, injecting되는 attention map은 존재하지 않는다.
논문의 알고리즘 및 핵심 method는 다음과 같다.


input으로 들어가는 것은 prompt P와 P* 그리고 random seed s다.
prompt P를 통해 생성한 이미지 I를 prompt P*를 사용해 I*로 바꾸는 것이 최종 목표다.
(source, target image 둘 다 결국 Imagen(backbone)이 생성하는 것이다. => real image도 가능함, input에 Image I 추가)
-> 기존에는 "a handsome guy wearing a cap"과 "a handsome guy wearing a blue cap"하면 아예 서로 다른 남자가 나왔는데, cap만 blue cap으로 바꾸고 나머지는 모두 유지하고 싶은 것이다.
우선, attention map을 만들기 위해 query, key, value matrix를 만들어야하는데, 학습된 linear projection l_Q, l_K, l_V를 사용한다.
query는 noisy feature φ(z_t)f를 l_Q에 넣어 만들고, key와 value는 prompt P의 textual embedding(ψ(P))을 각각 l_K, l_V에 넣어 key, value matrix로 만든다.
이렇게 만든 Q, K, V를 이용해 아래와 같은 식으로 attention map을 구성할 수 있다.

이때, M_ij는 i번째 픽셀의 j번째 토큰의 value 가중치이다.
attention map을 시각화해보면 아래와 같다.(논문에서는 expressiveness를 위해 multi-head attention 사용)
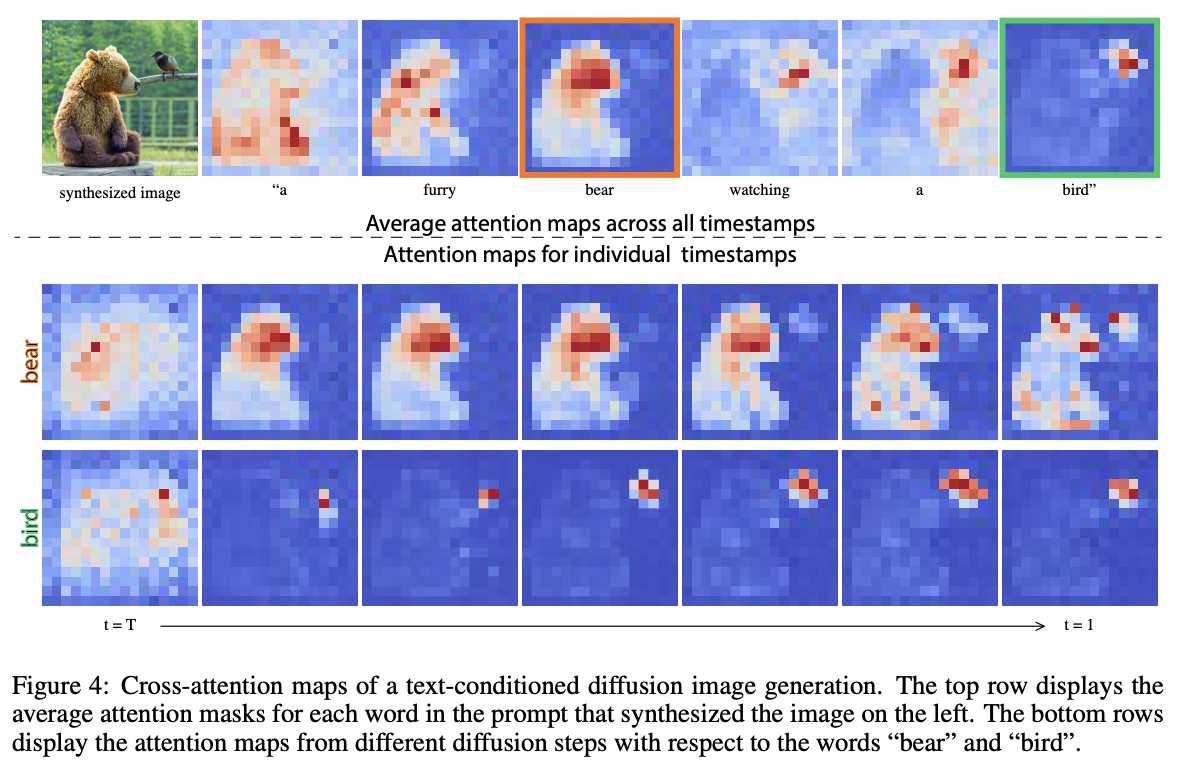
이렇게 뽑은 attention map은 edited prompt P*로 이미지를 생성하는 과정에 주입시켜준다.
이를 통해, 원래 이미지 I의 structure는 보존하면서 edited prompt에 따라 image manipulationd이 가능해진다.

다시 알고리즘을 보며 정리해보자면 DM(Diffusion Model)에 P와 z_t를 넣어 만든 attention map M_t와 P*와 z_t*를 넣어 만든 attention map M_t*을 Edit process에 넣어 새로운 attention map \hat M_t을 만든다. (Edit process는 아래에서 설명 예정)
이 \hat M_t을 DM에 넣어 z_{t-1}*를 만들어준다. 최종적으로 z_0가 우리가 만들고 싶어하는 이미지 I가 되는 것이다.
그럼 이제 구체적으로 Edit process가 어떻게 \hat M_t을 만드는지 살펴보자.
(이 논문을 통해 할 수 있는 task들과 matching되는 3가지 case로 나누어 생각해보자.)
1. Word Swap. (배경은 유지한 상태로 대상 변경)

2. Adding a New Phrase. (대상은 유지한채로 전체적인 이미지 수정)

3. Attention Re-weightning. (editing 효과의 강도 조절)

1은 time step τ에 따라 M_t* 혹은 M_t를 선택하게 하는 것인데, process의 초반에는 원본 attention map인 M_t를, τ 이후에는 edited attention map인 M_t*를 선택한다.
2는 추가적인 alignment function A를 사용해서, "children drawing of a castle next to a river", "castle next to a river"의 경우 castle next to a river는 j번째 토큰이 없을때는(A(j) = None) M_t*를, j번째 토큰이 둘 다에 있을때는 M_t를 선택한다.
3은 editing effect의 정도를 조절할 수 있게 하는 방식인데, j = j* 일때 상수 c를 통해 (-2<c<2) attention map의 정도를 조절해준다.
각 task에 대한 결과는 아래와 같다.



2. InstructPix2Pix: Learning to Follow Image Editing Instructions
위 Prompt-to-Prompt Diffusion에서 real image에 대한 instruction을 확장시킨게 InstructPix2Pix다.
InstructPix2Pix는 입력으로 real image와 이를 어떻게 바꾸고자 하는지에 대한 text prompt가 들어간다.
이를 잘 하게 하기 위해 본 논문에서는 GPT3와 StableDiffusion을 활용해 직접 학습 데이터셋도 구축한다.

학습 데이터셋 구축 및 학습은 아래의 순서로 진행된다. (위 그림의 a,b,c,d 순서)
(a) Generate text edits
우선 Input Caption이 주어지면, GPT3를 활용해 Instruction과 Edited Caption을 만들어낸다. 아래 코드의 빨간색 밑줄 친 부분 처럼 captions은 이미 dataset에 존재하고, openai의 gpt3를 활용해 edit(instruction)과 output(edited caption)을 생성해낸다.

(b) Generate paired images
그리고 난 후 각각의 input caption, edited caption을 가지고 두 장의 이미지를 생성한다.

(c) Generated training examples
마지막으로 두 장의 이미지와 instruction을 합쳐 데이터셋을 구축한다.

(d) Inference on real images
이렇게 구축한 데이터셋을 가지고 Stable Diffusion을 학습시키고, 이를 이용해 real image와 새로운 instruction prompt가 들어왔을때 이를 잘 반영하는 edited image를 생성해낸다.

본 논문에서도, Classifier-Free Guidance를 사용하고 있는데 condition이 두개라 아래와 같은 방식으로 구현했다.

또한 이 논문의 핵심 contribution중 하나가 real image에 대한 zero-shot generalization 가능해졌다라고 저자들은 주장하고있다.
3. Adding Conditional Control to Text-to-Image Diffusion Models
일명 ControlNet. 정말 많이 쓰이고 있고, 많은 사람들이 한번쯤은 들어봤을 모델이다.
ControlNet은 Prompt-to-Prompt 혹은 InstructPix2Pix와 같은 prompt based editing 뿐만 아니라 prompt가 없는 unconditional generation에서도 매우 그럴싸한 이미지를 생성해낸다.
예를 들어, 아래의 사진과 같은 것들이 가능한데, 논문에는 훨씬 더 많은 결과들이 있으니 참고해보면 좋을 것 같다.



ControlNet의 아키텍쳐는 아래와 같다.

위 아키텍쳐를 식으로 나타내면 아래와 같다.

아키텍쳐의 핵심은 1) trainable copy layer과 2) zero convolution layer이다.
좀 더 자세히 살펴보면 아래와 같은 흐름으로 되어있다.

1) trainable copy layer의 역할은 large pretrained model(SD)를 backbone으로 잘 활용하되, 다양한 conditional control를 가능하게 하기 위함이다. pre-trained model은 freeze시켜놓고 학습 시키지 않는데, 이 둘은 zero convolution layer로 연결되어 있다.
2) zero convolution layer는 모든 layer들의 가중치가 0으로 초기화되어있는 layer이다.(1x1 conv layer 사용)
가중치를 0으로 초기화 시킨 이유는 학습 초기에 deep layer features에 harmful noise가 추가되지 않게 하고, large-scale pretrained backbone을 보호하기 위해서이다.(harmful noise로 부터)
또한 학습을 시킬때 text prompt의 50%를 empty string으로 교체한다고 하는데, 이렇게 하는 것이 ContolNet으로 하여금 conditional image의 semantic 정보를 더 잘 학습할 수 있다고 한다.
4. Visual Instruction Inversion: Image Editing via Visual Prompting
마지막으로 visii는 InstructPix2Pix를 backbone으로, visual prompting을 가능하게 하는 paper다.
in-context learning in diffusion이란 주제로 고민하다가 떠올랐던 아이디어인데 (대충 이런게 가능하지 않을까?), 이 논문이 정확히 똑같은 task를 수행했고, Neurips 2023에 accept되었다. 아쉬움보다는 생성모델의 트렌드를 잘 follow up 하고 있구나 하는 생각때문에, 뿌듯한 마음이 더 크다.
문제 정의는 아래와 같다.
아래 그림과 같이 Before, After, Test image 3장의 이미지를 input으로 넣으면, output은 Before->After 이미지의 relation을 학습해 이를 Test image에 적용한 image가 나온다.

기존의 InstructPix2Pix는 아래와 같이 text instruction이 꼭 필요했는데, 이제는 image들 만으로도 prompting을 할 수 있는 것이다.

image(visual) prompting이 필요한 motivation이나 이유에 대해서는, 저자들은 텍스트만으로 prompt를 주는 애매함 및 어려움을 말하고 있고, 이미지 프롬프팅이 훨씬 직관적이고 간결하다고 말하고있다.

visual prompting을 활용해서 before-after 이미지의 relation을 학습하는 알고리즘은 아래 그림과 같다.

loss를 크게 두가지를 사용하는데 아래와 같다.
- InstructPix2Pix를 활용하여 before image와 after image를 동일하게 만들어줄 learned instruction을 학습하는 mse loss(기존의 epsilon 예측)
- delta(x->y)와 learned instruction c_T의 cosine distance를 작게 만드는 cosine loss

코드로 보면 좀 더 잘 이해가 될 것이다.

결과는 아래와 같다.

Before - After image의 관계 처럼 test 이미지를 잘 editing하는 것으로 보인다.
그러나 이 논문의 마지막에 저자들은 limitation에 대해 간략히 언급하는데, 아무래도 pre-trained model(InstructPix2Pix)에 많이 의존하기 때문에, 잘 수행하지 못하거나 특히 segmentation 등 computer vision의 여러 downstream task를 수행하기엔 성능이 조금 부족하다는 것이다.

이렇게 총 4편의 논문을 읽었다. 7편을 추석주간에 읽으려했지만, 4편의 논문의 흐름을 이해하고 정리하다보니 최소 이틀정도는 포스팅에 시간을 할애한 것 같다. 다음주에도 5편을 목표로 잡고, 주말 이틀은 스스로 정리를 해봐야겠다.
다음주에는 논문도 논문이지만 오늘 포스팅의 마지막 논문이였던 visii를 개선시킬 아이디어 고민 및 코딩을 1순위로 해야겠다.
+ 수리통계학2와 시계열분석 시험 공부



댓글