arxiv : https://arxiv.org/abs/2211.09794
code : https://github.com/google/prompt-to-prompt/#null-text-inversion-for-editing-real-images
1. Introduction

- 논문이 다루는 task : text guided image editing
- Input : image
- Output : (text guidance를 통해 condition된) image
- 해당 task에서 기존 연구 한계
Text-to-Image generation task에서 특정한 사람이나 사물을 보존하면서, condition하게 image를 생성하려면 DDIM Inversion process가 반드시 필요하다.
DDIM inversion이란 DDIM에서의 sampling 과정을 역으로 수행한 것으로 기존 sampling 과정이 x_T to x_0 즉 noise to image였다면, 이를 반대로 수행해 이미지가 입력으로 들어왔을때 이를 noise로 만드는 것(x_0 to x_T)이다.
수식으로 보면 아래와 같다.
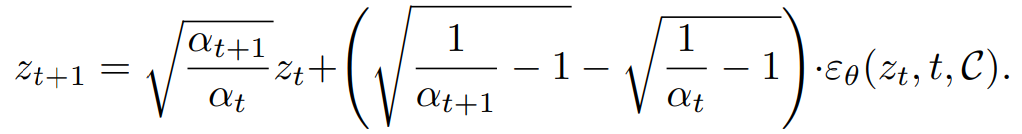
위 식을 통해 image(x_0)를 noise(x_T)로 바꾸고 해당 noise로부터 conditional generation을 하면(아래식), 원하는 object는 고정한 채로 새로운 이미지를 생성할 수 있다.
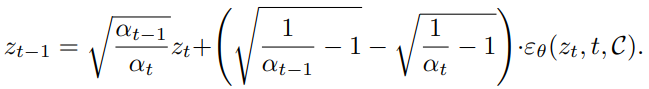
Unconditional generation의 경우 위와 같은 inversion process에는 약간의 error가 존재하지만, 그 크기가 무시할 수 있을 정도로 작고 실제로 이미지를 reconstruct해봐도 성공적으로 할 수 있다.
그러나 본 논문의 저자들이 발견하기로는 conditional generation에서 classifier-free guidance(w > 1)를 적용하였을 때, 이 error가 증폭된다는 것이다.
이는 아래 그림과 같이 image -> noise -> image로 reconstruct 하였을 때 기존의 image와 많이 다른 image가 생성된다.

결론부터 말하자면, 본 논문에서는 Null-text Inverision을 사용하여 이러한 문제점을 해결했다고 볼 수 있다.
2. Related Work
위에서 설명한 DDIM inversion process 및 text-guided-image synthesis 연구들에는 아래의 선행 연구들이 있다.
Textual Inversion, DreamBooth, SDEdit, Blended Diffusion, GLIDE, DiffusionCLIP, CLIP Styler, Prompt2Prompt, KNN diffusion, DiffEdit, Imagic, UniTune
(대부분 이전에 포스팅한 논문들이라 설명은 생략하겠다.)
3. 제안 방법론


- Main Idea
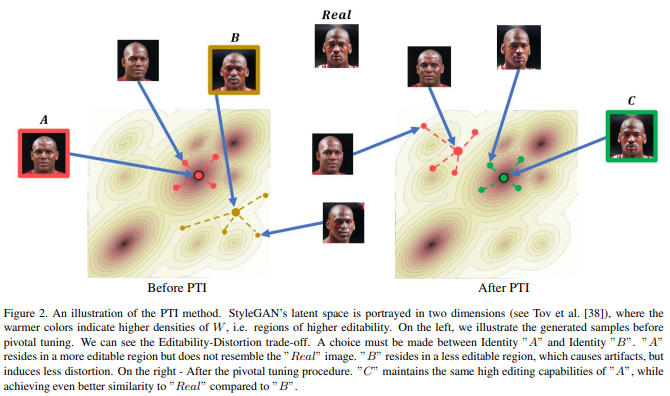
핵심 아이디어는 Figure 3에 아래 그림과 같다.
Figure 3의 상단 그림은 기존의 DDIM inversion(pivotal inversion)을 나타낸 것이고, 아래는 이 논문에서 제안한 Null-text Optimization이다.
기존의 DDIM inversion은 noise X_T로 부터 sampling을 하면 원래의 trajectory와는 다르게 결과가 생성된다.
이를 Null-text Optimization을 통해 Pivotal tuning을 해주면서 올바른 z_{T-1}, z_{T-2}, ... , Z_{1} 의 trajectory를 유도할 수 있게 한다.
그렇다면 자연스럽게 드는 의문은 이러한 pivotal tuning을 할 때 왜 Null-text Optimization을 사용했냐는 것이다.
-> 사실 Controlnet에서 zero convolution을 사용하는 것과 비슷한 의미이지 않을까 생각한다. 확실하지는 않고 아직 정확한 이유를 찾지는 못한 것 같다.
- Contribution
null-text optimization을 통한 pivotal tuning으로 high-fidelity editing 가능
4. 실험 및 결과
- Dataset
100 images and captions pairs, randomly selected from the COCO validation set
- Baseline
pretrained Stable Diffusion, Prompt-to-Prompt
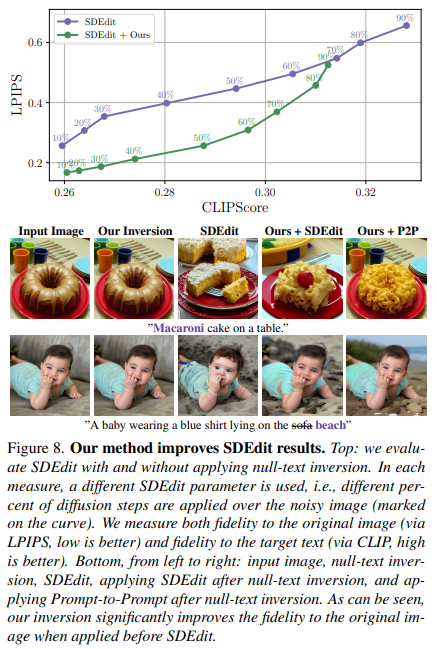
- Results



- Conclusion (What I learned)
condition을 어떻게 넣어야하는지에 대한 감이 잡힌 것 같다. 본 논문을 base로 image-condition을 준 논문은 없는지 찾아봐야겠다.




댓글