이번주에 원래 읽으려고 계획했던 논문은 아래 5편의 논문이다.
[읽음]
- IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
- In-Context Learning Unlocked for Diffusion Models (Prompt Diffusion)
- DIFFUSION MODELS ALREADY HAVE A SEMANTIC LATENT SPACE (asyrp)
- Hierarchical Text-Conditional Image Generation with CLIP Latents (DALL-E 2)
[못 읽음]
- Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding (Imagen)
1. IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
image prompt diffusion model과 관련하여 논문들을 찾아보다가 알게 된 논문이다.
내가 생각한 아이디어와 비슷한듯 보였지만, 아키텍쳐가 단순하고, 개선 여지도 많은 것 같아 베이스라인으로 생각해보면 좋을 것 같았다.
논문의 핵심 아이디어는 Stable Diffusion(SD)은 freeze 시킨 상태로 decoupled cross-attention을 활용하여 image features를 기존에 SD에서 쓰이던 text features와 결합해서 사용하겠다는 것이다.
즉, 기존의 SD에서는 text feature만 cross attention 형태로 UNet에 입력으로 들어왔다면, 본 논문에서는 image feature + text feature를 UNet 주겠다는 아이디어이다. (아래 그림 참고)
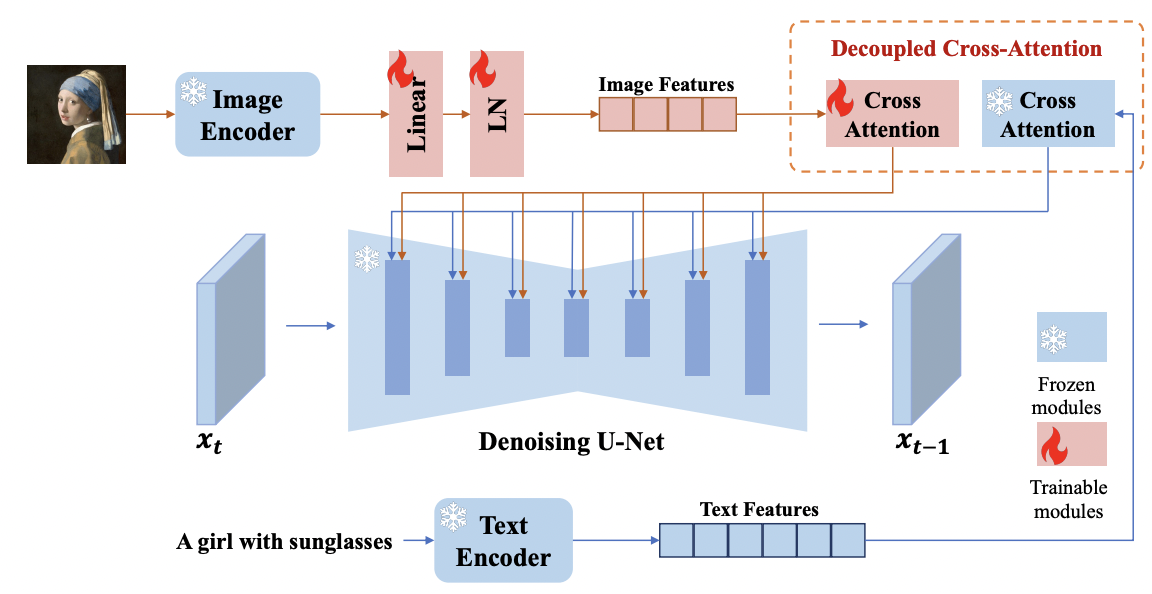
또한 text-prompt가 아닌 image-prompt가 왜 필요한지에 대해서도 언급하고 있다. image-prompt가 처음 stable diffusion에서 활용된 것은 DALL-E 2, Stable unCLIP 등이지만 너무 많은 학습 비용과 ControlNet등과의 비호환 등의 문제가 있었고, 이 논문에서는 SD는 freeze 시켜놓고 adapter만 fine-tuning 시키는 형태로 image-prompt를 사용할 수 있기 때문에, 훨씬 가볍고 성능도 좋다고 한다.
논문을 읽으면서 든 (자연스러운) 개선 방향은 다음과 같다.
- Training-Free : 논문의 모델은 IP-Adapter를 학습시키기 위해 10 million text-image pair dataset을 활용하였고, 총 파라미터 수는 22M개다.
- 논문에서는 이 정도면 충분히 작고 효율적이라고 하는데 adapter 학습 없이 well pre-trained diffusion model을 좀 더 잘 활용해본다면 좋은 성능을 낼 수 있지 않을까?
- 성능 개선 : 결과를 보면 task자체는 잘 수행하는 듯 보이나, image prompt에 있는 대상을 잘 보존하지는 못하고 있다. 이는 Dreambooth나 Textual inversion 등에서 훨씬 잘 하고 있는데, image prompt를 사용할 수 있게 하면서 그 프롬프트 안에 있는 대상을 잘 보존하는 방법도 고민해볼 필요가 있어 보인다.
- 논문의 결론에서도 이 부분은 언급하고 있다.(대상을 잘 보존하는 adapter로의 개선이 필요하다~)
2. In-Context Learning Unlocked for Diffusion Models (Prompt diffusion)
Diffusion models에서 in-context learning을 적용한 최초의 논문.
input, output 구조가 기존 text에서의 in-context learning보다 복잡하고, 처음부터 full-training을 시켜서 리소스도 많이 필요하지만(+ 6개의 downstream task만 수행 가능), LLM에서의 좋은 특징들(in-context learning)을 diffusion에 적용했다는 점에서는 분명히 contribution이 있는 것 같다.
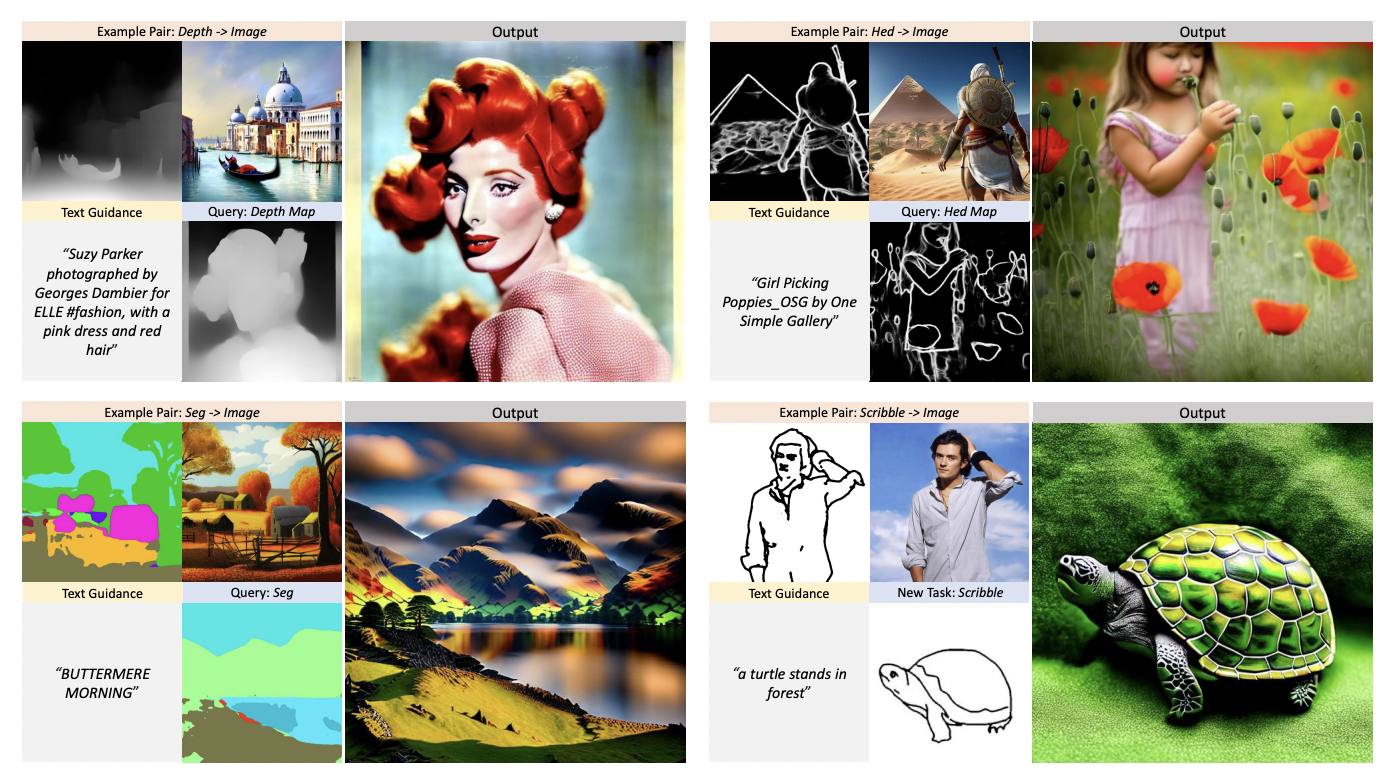
우선 prompt는 아래와 같이 구성한다.
input으로 들어가는 prompt에는 text-guidance, image1,2(어떤 task인지 알려주는), image-query(실제 task를 수행할 이미지)가 포함된다.
output에는 image-query에 해당하는 이미지에 image1 -> image2에 해당하는 task를 적용한 이미지가 최종 출력으로 나온다.

한 가지 의문(혹은 어쩌면 개선사항)은 text-guidance가 왜 필요한지 잘 이해가 안 된다는 것이다.
바로 아래에서 리뷰할 Diffusion Models Already Have a Semantic Latent Space에서는 h-space라는 공간을 잘 조작하여 diffusion model에서 manipulation을 잘 수행할 수 있었다고 하는데, 이 프롬프트에도 image1-image2 사이의 관계만 잘 찾아낼 수 있다면 text-guidance가 필요 없지 않을까? 하는 생각이 들었다.
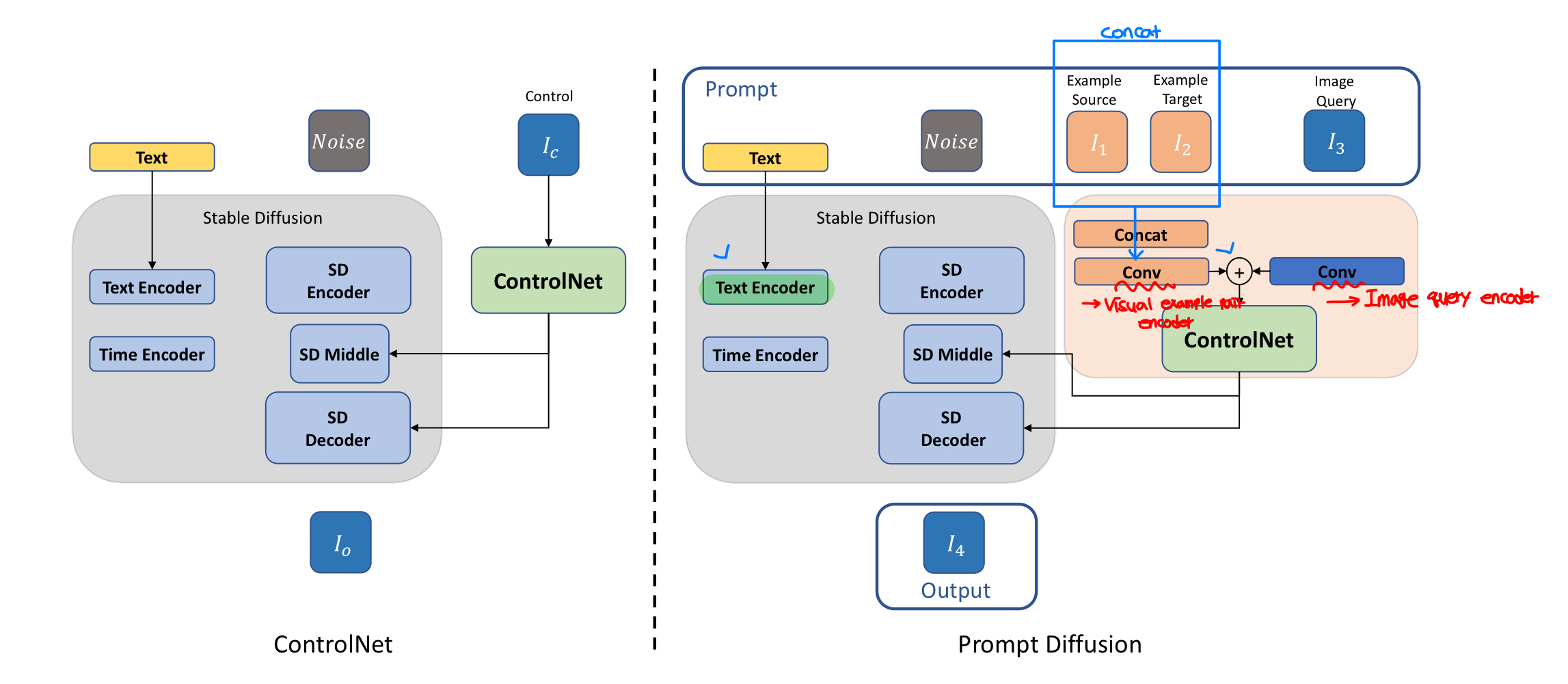
모델 구조는는 위와 같은데 사실 ControlNet과 거의 동일하고, Prompt를 text, image1,2,3 로 구성했을때 각각을 어떻게 넣어 줄 것인지만 차이가 있다.
(ControlNet을 아직 안 읽어봐서 clear한 이해는 못 한 것 같다. 다음주에 읽어 볼 예정이다.)
3. DIFFUSION MODELS ALREADY HAVE A SEMANTIC LATENT SPACE
정말 배울게 많았던 논문.
DDIM의 샘플링 공식(아래 식 참고)에서 predicted x_0 부분만 잘 바꿔주면(U-Net의 가장 깊숙한 layer(h-space)를 통해) image manipulation이 가능하고 이 h-space가 semantic latent space임을 보인 논문이다.

위 식에서 \epsilon_t^\theta(즉, model)가 predicted x0와 direction pointing xt 둘 다에 사용되고 이게 상쇄되면서 결국 epsilon을 학습시키던(\epsilon^tilde) 안 시키던 효과가 없다고 말하고 있다. 따라서 논문에서는 아래와 같이 predicted x0(P_t) 부분에서만 \epsilon^tilde를 사용하고 direction pointing to x_t 부분에서는 그냥 epsilon을 사용한다. 그리고 이를 Asymmetric reverse process(Asyrp)이라고 명명했다.
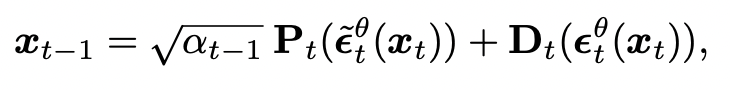
그림으로 보면 아래와 같다.
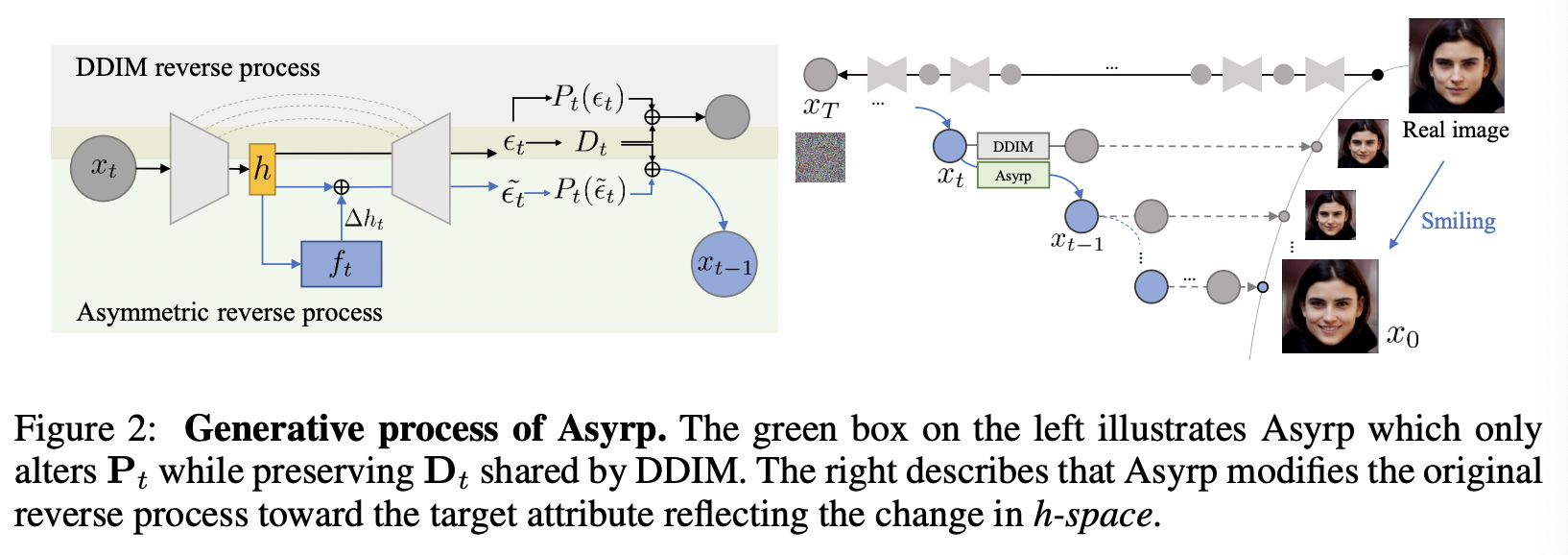
또한 이런 Asyrp을 전체 time step(1000~0)에서 수행하는 것이 아니라, t_edit에 해당하는(일반적으로 LPIPS = 0.33일때) 지점 까지만 수행해야 이미지의 퀄리티가 좋다고 한다. (전체 다 delta h를 먹이면, 오히려 이미지 퀄리티가 떨어짐)
뿐만 아니라, t_boost 시점 부터는 기존에 ddim에서 deterministic했던 부분(\eta = 0)을 stochastic하게 (\eta = 1) 노이즈를 추가해줌으로서 이미지 퀄리티를 올렸다고 한다.

t_edit, t_boost에 따른 구간 별 프로세스는 아래와 같다.
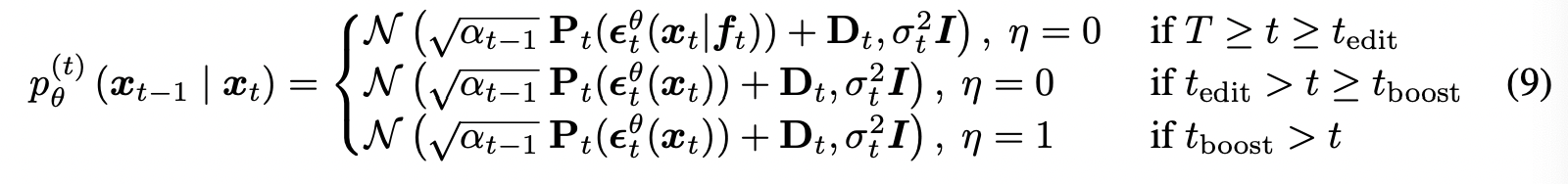
t_edit과 t_boost는 실험을 통해 empirical하게 구했으며, t_edit의 경우 일부 attribute는("pixar") 일반적인 attribute("happy")에 비해 좀 더 복잡하므로 t가 더 뒤 시점이여야 한다고 한다.
논문에서는 매우 다양한 실험을 진행하였는데, 많은 인사이트를 얻을 수 있는 것 같아 개인적으로 꼭 추천하는 논문이다.


4. Hierarchical Text-Conditional Image Generation with CLIP Latents (DALL-E 2)
GLIDE의 업업그레이드 버전. DALL-E 2로도 유명한 unclip 모델의 논문이다.
전체적인 overview는 아래와 같은데, 점선 아래 부분이 unCLIP이고, 윗 부분은 CLIP training process를 의미한다. prior과 decoder
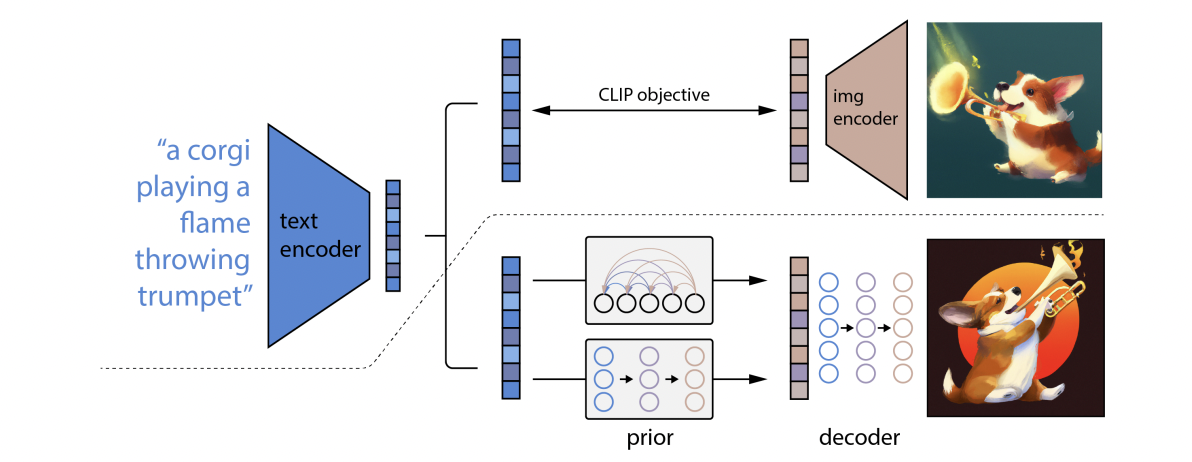
핵심은 prior과 decoder를 어떻게 학습시킬 것인가? 인데 우선 x가 이미지이고 y가 캡션, z_i가 CLIP image embedding일때, P(x|y)는 아래와 같이 표현할 수 있다. (chain rule과 조건부확률의 정의를 활용하면 간단히 유도할 수 있다.)
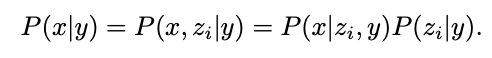
즉, 텍스트로 이미지를 생성함에 있어 이를 decoder(P(x|z_i, y)와 prior(P(z_i|y))로 나누어 생각할 수 있다는 것이다.
decoder는 기본적으로 GLIDE 모델을 조금 수정하여(timestep embedding에 clip embedding 추가 등) 사용하고, 고해상도 이미지를 만들기 위해 두개의 upsampler model을 학습시킨다.(64x64 -> 256x256, 256x256 -> 1024x1024)
prior는 AutoRegressive(AR) prior와 Diffusion prior 두 개에 대해 실험을 진행한다.
아래 그림에서 왼쪽이 AR piror이고, 오른쪽이 Diffusion prior이다.
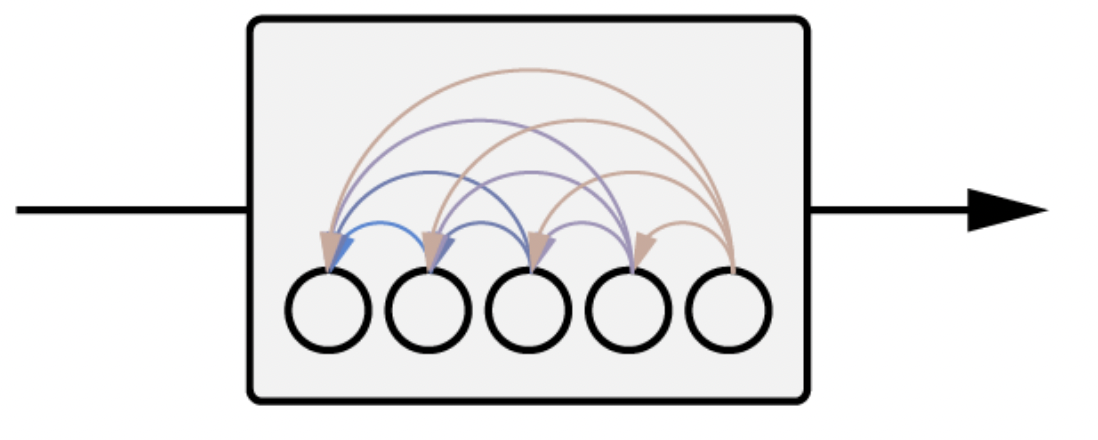
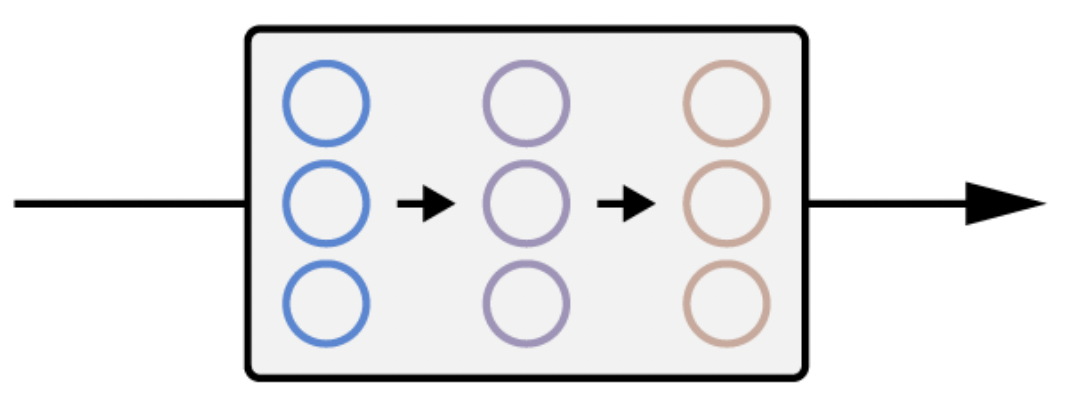
AR prior에서는 PCA를 활용해 z_i의 차원을 줄여서 활용하였고, Diffusion prior에서는 Decoder-only transformer를 활용하였다.
DALL-E2는 정말 다양한 task를 할 수 있는데, 그 결과는 GLIDE보다 훨씬 더 놀랍다.




DALLE-2는 좀 급하게 마무리한 감이 있는데, 갑자기 급하게 공부해야 될 분야가 생겨(아래 두 논문) 이 분야를 먼저 공부 후 여유가 된다면 보충 설명을 작성해야겠다.
다음 주에는 아래 두 논문을 읽을 것이고, 코드까지 다 뜯어보는 것이 목표이다.
- Planning with Diffusion for Flexible Behavior Synthesis (코드까지)
- IS CONDITIONAL GENERATIVE MODELING ALL YOU NEED FOR DECISION-MAKING? (코드까지)



댓글