이번주에 원래 읽으려고 계획했던 논문은 아래 6편의 논문이다.
[읽음]
- Denoising Diffusion Implicit Models (DDIM)
- Plug-and-Play Diffusion Features for Text-Driven Image-to-Image Translation
- DIFFUSIONCLIP: TEXT-GUIDED IMAGE MANIPULATION USING DIFFUSION MODELS
[못 읽음]
- Diffusion Models already have a Semantic Latent Space
- GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
- SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
이번주에는 위에 세 개 밖에 읽지 못하였다. 나머지 세 개는 다음주에 읽어야겠다.(코드를 먼저하고 시간이 된다면)
이번 포스팅에서는 DDIM, Plug-and-Play Diffusion, DIFFUSIONCLIP 세 논문에 대해 간략하게 리뷰해보겠다.
1. Denoising Diffusion Implicit Models (DDIM)
DDIM의 핵심 contribution은 기존 DDPM의 forward process(Markovian)를 non-Markovian으로 바꿨다는 것이다.

그렇다면 핵심은 non-Markovian으로 어떻게 바꿨고, 바꿨을때 어떤 이점이 있는 것일까를 이해하는 것이다.
우선 DDPM의 Loss function을 보면 아래와 같다.

위 식은 marginal distribution인 q(x_t | x_0)에만 depend하고, joint distribution인 q(x_{1:T} | x_0)에는 depend 하지 않는다.
-> 즉 x_0가 주어졌을때 x_t에 대한 objective function을 계산하는 것이기 때문에 x_{1:T}와는 관련이 없다는 의미인 것 같다.
따라서 x_0는 x_{1:T} 전체에 직접적으로 영향을 미치는 것이 아니라 x_t(marginal)에만 영향을 미친다고 생각할 수 있고, 이를 나타낸 것이 아래의 그림이다.
위 forward process를 수식으로 표현하면 아래 식과 같고

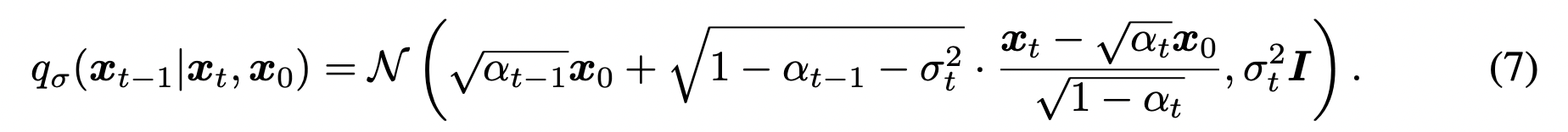
이때 7번식은 아래 식을 만족시키기 위해 선택된 것이다. (그렇게 하자~의 약속)

사실 이 약속(7번식)이 가장 이해가 안됐는데, 그러니까 7번식 자체로만 이해를 해보자면
x_t와 x_0가 주어져있을때, x_{t-1}을 어떻게 modeling할 수 있을까?
우선 기존의 posterior에 해당하는 q_{\sigma}(x_t|x_0) 식을 만족해야하므로 x_t = \sqrt{α_{t-1}} x_0 + \sqrt {1-α_t} \epsilon 일 것이다.
\sqrt{α_{t-1}} x_0 + \sqrt {1-α_t} \epsilon (즉, x_t)과 x_0가 주어진 상황에서 x_{t-1}을 modeling 해야하므로 (\sigma_t를 활용해서)
다시 생각해보면, \sqrt {1-α_t} 에서 \sqrt {1-α_t-\sigma_t^2}로 sigma_t^2만큼 빼주면 되는 것이다.
(7번식의 mean term에 제일 뒤에 나오는 {x_t - \sqrt{\alpha_t} x_0} / \sqrt(1-\alpha_t} 부분은 epsilon에 대해 정리해주면 것이다.)
글로 쓰려니 굉장히 설명을 못한 것 같은데 정리해보면 아래와 같다.

6번과 7번 수식을 통해 아래 식이 만족한다는 증명은 논문의 Appendix B의 Lemma 1 부분을 보면 알 수 있다. 귀납법을 통해 증명해놨으니 참고하면 좋을 것 같다.
결과적으로 DDPM의 느린 sampling 속도를 개선할 수 있었고, 무엇보다 개인적으로 생각하는 DDIM의 가장 중요한 특징 중 하나는 image-encoding이 가능해졌다는 것이다. (즉, x_0 -> x_T -> x_0 가능)
뒤에 나오는 DiffusionCLIP이나 그 이후의 후행 연구들이 위 특징에서 motivation을 얻는 경우가 많은 것 같다.
이에 대한 내용은 본 논문의 4-3 파트에 있으므로 관심 있으신 분들은 읽어보면 좋을 것 같다.
2. Plug-and-Play Diffusion Features for Text-Driven Image-to-Image Translation
해당 논문은 pre-trained diffusion model을 추가적인 fine-tuning 없이 image-to-image translation task를 가능하게 했다.

간단하게 핵심 Idea만 말하면 pre-trained diffusion model(Stable Diffusion, GLIDE, Dreambooth 등과 같은 text condition에 대해 학습된)의 decoder 부분에서 self-attention의 query와 key를 가져와서 이를 text prompt와 cross attention에서 사용하는 것이다.
self-attention query와 key를 cross attention에 활용한다는 idea가 간단한것 같으면서도 좋은 insight였던 것 같다.
3. DIFFUSIONCLIP: TEXT-GUIDED IMAGE MANIPULATION USING DIFFUSION MODELS
DiffusionCLIP은 pre-trained diffusion model과 pre-trained CLIP을 활용해 약간의 fine-tuning을 통해 image-to-image translation 및 style transfer task를 수행했다.
점점 논문 설명이 빈약해지는 것 같은데, 사실 약간의 technique만 추가될 뿐 핵심은 DDIM이 image encoding이 잘 된다는 것을 CLIP model 및 loss와 함께 잘 활용했다는 것이다.
조만간 Plug-and-Play Diffusion과 DiffusionCLIP의 코드를 뜯어볼 것 같은데, 그때 자세히 포스팅 할 수 있다면 해보겠다..!

이번 주에는 생각보다 DDIM 수식이 많이 복잡해서 읽는데 시간도 오래 걸렸고, 목요일과 금요일은 대학원 면담 및 약속도 있었어서 더 시간이 촉박했던 것 같다. 개인적으로 Plug-and-Play diffusion과 DIFFUSIONCLIP은 코드를 꼭 이해하고 돌려보고 싶은데, colab pro에서 vscode 연결해가면서 하는게 너무 비효율적이란 생각이 많이 든다...... 그래도 나중에 읽을 논문들의 코드 이해를 위해서라도 지금부터 코드를 병행해야 할 것 같다.
이번주나 다음주부터 영어공부도 해야할 것 같은데, 선대 스터디와 영어 공부까지 하기엔 조금 벅차다는 느낌을 받는다. (선대 스터디 첫 주차 결석 .. ) 그래도 최대한 시간을 쪼개며 열심히 해봐야겠다..!!
그리고 빅자분 수업 플젝을 diffusion을 활용한 주제로 할 것 같고(k-fashion 분석), 소프트웨어 실습 수업도 주제(tini diffusion(?))를 슬슬 정해야할 것 같은데, 둘 다 웬만하면 다음 주 내에 구체적인 방향을 정해야겠다.



댓글