목차
생성모델 관련 연구를 하며, 또 몇번의 인턴 면접을 보며, 생성모델을 평가하는 메트릭에 대해 "잘" 알고있는 것이 매우 중요하다는 생각이 든다.
사실 이미지를 잘 생성한다라는 것을 수치적으로 명확히 정량화하는 것은 매우 어려운 영역이고, 아직도 활발히 연구 중에 있다. 그러나 그럼에도, 생성모델을 연구하는데 있어서 정량적인 비교는 반드시 필요하기에 이미 많은 논문에서 자신만의 혹은 기존에 쓰이던 정량지표를 활용하여 해당 본인 논문의 우수성을 입증하고 있다.
오늘은 이러한 생성모델(gan, diffusion)의 연구들에서 주로 쓰이는 평가지표에는 어떤 것들이 있고, 각각이 어떤 의미를 갖는지 정리해보겠다. (사실 여기 나온 지표들 말고, 더 많은 좋은 메트릭들이 있을 수 있지만 내가 직접 논문들을 읽으며 봤던 혹은 많이 들어봤던 지표들만 추린 것 이다.)
1. Inception score
첫 등장 : Improved Techniques for Training GANs (NIPS 2016)
가장 먼저 Inception score이다. 아마 FID score와 함께, 가장 많이 보이는(보였던) 평가지표 중 하나일 것이다.
(GAN based 논문들에서는 FID score와 함께 꽤 많이 보였지만, 요즘에는 잘 보이지 않는 것 같다.)
Inception score(IS score)는 이미지의 Fidelity(품질)와 Diversity(다양성)가 높을수록 높은 양상을 보인다.
또한 Fidelity와 Diversity가 높을수록 점수가 높아지는데, 즉 Inception score는 점수가 높을수록 더 그럴싸한(real image) 이미지를 생성한다고 해석할 수 있다.
Inception score을 계산하기 위해서는 Inception model을 사용해야하는데, Inception model은 CNN based model 중 하나로 이 모델에 대한 자세한 설명은 여기를 참고하길 바란다.
Inception score의 계산 순서는 다음과 같다.
우선 생성된 sample image x_i가 있다고 하자.
discriminator(inception model, p_dis)을 활용하여 x_i에 대한 p_dis( · |x_i)의 분포를 구한다.
p( · |x_i)는 해당 이미지가 inception model의 정답 label들 중 어떤 label에 속할지에 대한 확률분포이다.
그런 다음, 우리의 생성모델 g를 활용해 이 p(y|x_i)를 marginalize한다.

이렇게 marginalize한 확률분포를 p^hat이라고 하면, 위에서 구했던 p_dis( · |x_i)와 p^hat의 KL divergence를 구해서 계산한다. 이렇게 구한 KL divergence 값들을 평균내고, 계산의 편의성을 위해 exponential을 취해주면 Inception score이 된다.
여기에 나와있는 시각자료들과 함께 본다면, 좀 더 이해가 잘 될 것이다.
Inception score에는 몇가지 치명적인 단점이 있는데, 우선 inception model 즉, classifier에 포함되어있지 않은 label의 경우 score값이 매우 낮게 나온다는 것이다. 또한 real data는 고려하지 않고, fake(generated) data만 활용해 점수가 계산되는데 이러한 단점은 아래에 나와있는 FID score에서 보완된다.
2. FID score
첫 등장 : GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium (NIPS 2017)
Frechet Inception Distance 일명 FID score는, 요즘까지도 가장 많이 쓰이는 생성모델의 평가지표라고 할 수 있다.
FID score는 real data와 fake data의 distribution(정확히는 각 data의 feature vector의 distribution)이 통계적인 측면에서 얼마나 유사한지, 그 distance를 나타낸 것이다.
구하는 식은 아래와 같다.
이때 u, ∑는 real image feature vector의 평균과 공분산 행렬이고, u'와 ∑'는 fake image feature vector의 평균과 공분산 행
렬이다.
real과 fake 각각의 image set에 대한 feature vector는 Inception score에서와 마찬가지로 pretrained model을 사용한다.
Inception model을 사용해도 괜찮지만, 임의의 feature extractor model f를 사용해 f(x_real)을 통해 u, ∑를 구할 수 있다.
FID score는 두 다변량 확률분포가 얼마나 유사한지 그 distance(Frechet distance)를 측정한 것이기 때문에, 점수가 낮을수록 분포가 가깝(good)다고 볼 수 있고 즉 fake image가 real image와 매우 비슷한 특징을 갖는다고 볼 수 있다.
Frechet distance 및 FID score에 대한 좀 더 엄밀한 설명은 여기에 자세히 나와있다.
실제로 FID score를 구해보니 계산하는데 정말 많은 시간이 걸린다는 단점이 있었다. 또한 통상적으로 최근에 나오는 generative model들은 FID score이 10 이하가 대부분인 것 같다.
2-1. Prompt fidelity
위 그림에서 Φ_θ(E|I'->I)가 아니라 Φ_θ(E|I->I') 가 맞지 않나....? 오타 같다..
Prompt fidelity는 Imagebrush에서 제시한 metric으로 visual in-context를 잘 따르는지 측정한다는 관점에서 Visual CLIP similarity와 쓰임이 유사하다고 볼 수 있다.
이때 Φ_θ는 model(ImageBrush)이고, examples {E, E'}를 참고해서 source image I가 들어왔을때 E->E'를 적용한 I'를 생성한다.
Prompt fidelity는 아래와 같이 FID score를 활용해 계산된다.
I -> I'가 condition으로 주어졌을때 E를 input으로 집어넣으면 model은 E'^hat를 생성할 것이다.
이렇게 생성된 E'^hat과 ground truth인 E' 사이의 FID score를 구해서 model의 output image가 얼마나 prompt에 충실하게 생성되고 있는지를 알 수 있다.
2-2. Image fidelity
반대로 model이 image I의 content를 잘 보존하고 있는지를 측정하기 위해 image fidelity metric도 제시하였다.
아래 식과 같이 E'->E가 condition으로 주어졌을때, after image였던 I'가 input으로 들어오면, 최종적으로 I^hat 즉 원본 이미지 I와 비슷한 ouput이 나올 것이다. 이렇게 생성된 I^hat과 I의 FID score를 구하면, 원래의 content를 잘 보존하고 있는지 측정할 수 있을 것이다.
3. LPIPS
첫 등장 : The Unreasonable Effectiveness of Deep Features as a Perceptual Metric (CVPR 2018)
Learned Perceptual Image Patch Similarity 일명 LPIPS는 위에서 설명한 Inception score 혹은 FID score처럼 생성된 fake image의 quality를 측정하는 것이 아닌, 두 이미지에 대한 perceptual distance를 측정하는 metric이다.
(LPIPS 이전의 방법(PSNR, SSIM 등)은 잘못된 이미지(human perceptual judgments와 다른)를 reference와 더 유사하다고 판단)
측정 방법은 위 식과 같다.
우선 두 이미지 x, x_0가 주어졌을때, pretrained VGG의 L개의 layer에서 feature를 stack하고 channel dimension으로 unit-normalize를 해준다. (-> 이때 만들어 지는 것이 y_hat^l, y_hat^l_0이다.)
이렇게 만든 y_hat^l과 y_hat^l_0을 이들의 channel-wise vector w^l로 scaling 해준다. 그리고 이 둘 사이의 L2 distance를 구한다.
마지막으로 spatially하게 평균을 내주고(height와 width wise로) L개의 channel에 대해 channel wise로 합해주면 된다.
LPIPS는 주로 super-resolution이나 image reconstruction 혹은 diffusion의 denoising process에서 각 time step별 x_t가 얼마나 차이가 나는지 등을 측정하기 위해 사용된다.(latent diffusion에서의 super-resolution 성능을 평가하거나, Asyrp에서의 editing interval 등을 구하는데 사용됨)
💡 LPIPS는 FID, IS score 처럼 fidelity나 diversity가 높은 이미지를 생성하는지 측정한다기 보다는, 두 image x,y가 얼마나 차이가 있는지를 보는 지표다.
4. CLIP smilarity
CLIP은 2021년 OpenAI에서 발표한 large multimodal model로 약 4억개의 text-image pair 쌍을 이용해 (contrastive) pretraining 시켰다.
Contrastive pre-training에 대해 좀 더 자세히 말해보자면, Text Encoder(Transformer)와 Image Encoder(ResNet, VIT)를 scratch로 처음부터 학습 시키는데, 이때 각각의 image-text pair에서 동일한 index(아래 그림에서 파란색 부분)의 cosine similarity는 가까워지도록, 나머지 부분의 consine similarity는 멀어지도록 학습을 시킨다. (더 자세한 설명)
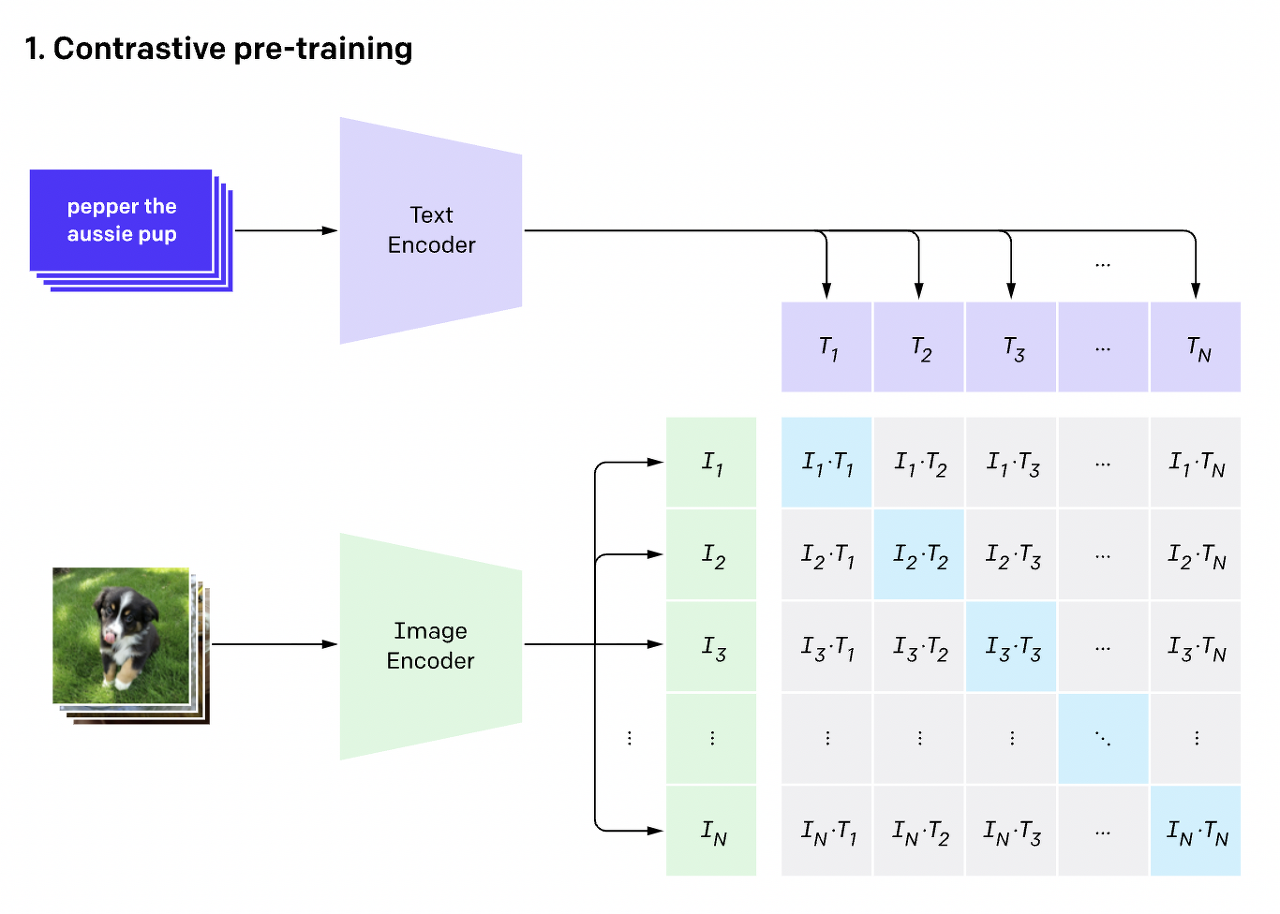
이렇게 학습시킨 Text Encoder와 Image Encoder는 zero-shot prediction도 가능하고, 또 image와 text의 joint embedding space를 잘 표현하고 있기 때문에, 이를 이용해 edited(generated) image가 target text prompt와 얼마나 align하고 있는지를 평가할 수 있는 CLIPScore등이 등장하였다.
4-1. Directional CLIP similarity
이러한 CLIP 모델을 사용한 가장 대표적인 평가 메트릭으로, stylegan-nada, diffuionCLIP, visii 등에서 사용되었다.
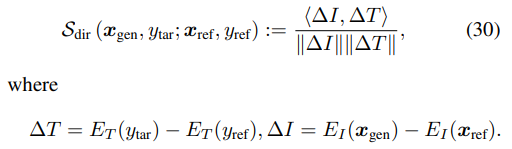
메트릭 자체는 clip image encoder와 clip text encoder를 통과한 output들의 차이(변화량)를 구해 이 차이간의 similarity를 구한 것이 전부이다.
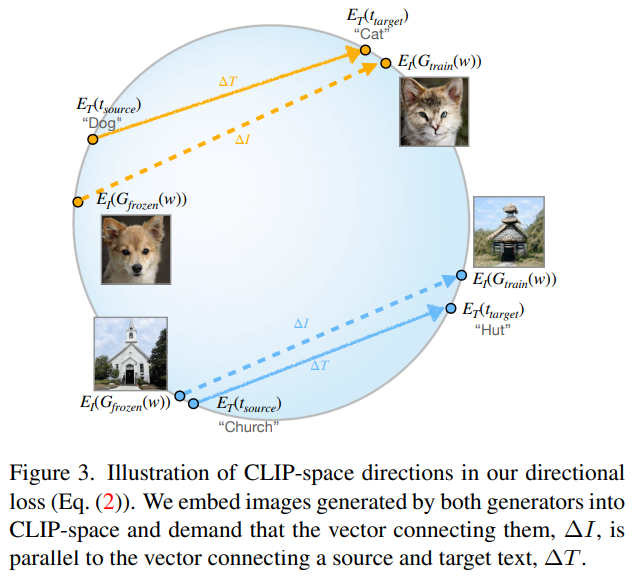
즉, Directional CLIP similarity가 높을수록 두 vector △I와 △T의 cosine similarity가 높다고 할 수 있다.(각도 0에 가깝)
4-2. Visual CLIP similarity
위 Directional CLIP similarity를 ∆I(example)와 ∆I'(test)에 대해서 계산하는 것이다.
아래 사진을 예시로, 먼저 before example image와 after example image사이의 ∆I를 구한다.
그런 다음 before test와 after test image 사이의 ∆I'를 구한다.
이렇게 구한 ∆I와 ∆I'로 Directional CLIP similarity에서처럼 cosine similarity를 구해주면 된다.

Visual CLIP similarity는 example images(before-after 형태의 pair로)가 주어졌을때, test image(before)와 이에 대한 generated image(after)가 얼마나 유사한지를 나타내는 score라고 할 수 있다.
즉, Visual CLIP similarity가 높을수록, test image before -> test image after이 examples을 잘 따른다고 할 수 있다.
(visual instruction task에서 꼭 필요한 메트릭이라고 할 수 있다.)
4-3. Image CLIP similarity
Image CLIP similarity는 두 이미지가 얼마나 유사한가, 즉 바뀐(생성된) 이미지가 원본 이미지를 얼마나 따르는지에 대한 score이다. (how much the edited image agrees with the input image)

위 그림과 같이 image to image translation, conditional image generation task 등에서 쓰일 수 있고, condition을 줘서 image를 edit하는 과정에서 원본 이미지가 너무 손상되어서 나오면 이 score는 낮게 나올 것이다.
즉, Image CLIP similarity가 높을수록 생성된 이미지가 원래 이미지를 잘 따른다고 볼 수 있다.
단, 원래 이미지를 잘 따른다는 것은 바꿔 생각하면 edit이 잘 안되었다고 생각할 수도 있고, similarity 역시 원본 이미지를 그냥 그대로 return 했을때 제일 높게 나올 것이므로 conditional image generation 혹은 image2image translation task에서 이 값이 높다고 무조건 좋은 것은 아니다.
4-4. CLIP-I
4-3에서 언급한 Image CLIP similarity를 여러 image들에 대해 구한 뒤 평균 낸 것이다.
5. DINO
CLIP-I와 CLIP-T는 모두 Dreambooth에서 제시된 평가 메트릭인데, 해당 논문에서는 DINO를 사용해 real image와 generated image 사이의 similarity를 구하는 방법론도 제시하였다.
CLIP 대신 DINO를 쓰는 이유는, DINO는 동일한 class의 subject 차이를 무시하지 않도록 훈련되었기 때문이다.
💡 DINO
CLIP과 같은 supervised network와 달리, DINO는 self supervised 방식으로 학습되어 subject or image의 unique feature을 구별할 수 있다.
쉽게 말해 아래 그림의 예시로, Dreambooth의 핵심은 특정 강아지 사진을 condition으로 주고, "the puppy is in a doghouse" 했을때, 그냥 아무 강아지가 아닌 "그 특정 강아지"의 subject는 보존하면서 in a doghouse라는 문맥에 맞게 이미지를 생성하는 것이다.
이러한 능력을 평가하기 위해서는 같은 class(puppy)라고 모두 동일하게 인식하는 것이 아닌 각 subject의 차이(어떤 puppy인가)를 인지할 수 있어야한다.

6. TIFA
TIFA는 LLM과 image captioning model(BLIP2)를 활용해 VQA accuracy를 기반으로 주어진 image와 text prompt pair의 semantic alignment를 평가하는 방법론이다.

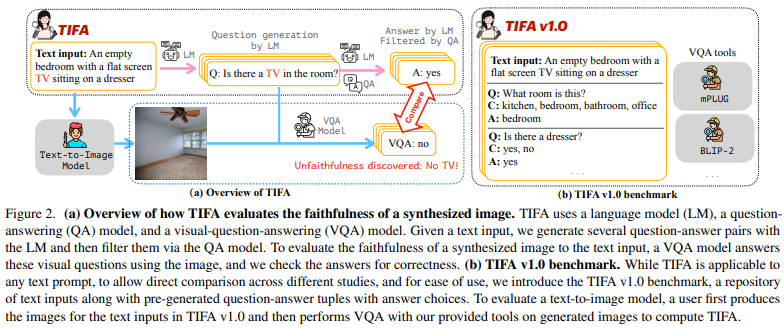
위 그림과 같이 Text input이 들어오면, LM을 활용하여 Question-Answer 쌍을 생성한다. QA필터를 활용해 이를 필터링한 후 VQA 모델이 이를 답변한다. 이때 생성되는 QA 질문은 어떤 text input이여도 상관 없지만, 비교를 위해 약 25000개의 질문을 pre-generate했다고 한다.
최종적으로 VQA 모델의 답변 결과의 accuracy를 바탕으로 TIFA를 구할 수 있다.
이 외에도 아래와 같은 메트릭도 있다.
- Rarity Score : A New Metric to Evaluate the Uncommonness of Synthesized Images (ICLR 2022)
- Probabilistic Precision and Recall Towards Reliable Evaluation of Generative Models (ICCV 2023)
그러나 이러한 메트릭은 요즘 읽는 논문들에서는 등장하지 않았고, 목적도 조금 다른 듯 보이기에 자세한 설명은 생략하겠다. (이를테면 rarity score는 얼마나 unique한 이미지들을 생성하느냐에 대한 척도이다.)
'AI Theory > Generative models' 카테고리의 다른 글
| 최대한 쉽게 설명한 GAN (2) | 2022.02.07 |
|---|---|
| 오토인코더(Autoencoder)가 뭐에요? - 5. Variational AutoEncoder(VAE) (0) | 2022.02.03 |
| 오토인코더(Autoencoder)가 뭐에요? - 4. Practice with PyTorch (AutoEncoder) (0) | 2022.01.31 |
| 오토인코더(Autoencoder)가 뭐에요? - 3. This is AutoEncoder! (0) | 2022.01.26 |
| 오토인코더(Autoencoder)가 뭐에요? - 2.Why AutoEncoder? (0) | 2022.01.25 |




댓글